CNN实现手写数字识别
导入模块和数据集
import os
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
(x_train,y_train),(x_test,y_test)=datasets.mnist.load_data()##直接从keras库中下载mnist数据集
数据集预处理
#由于导入的数据集的shape为(60000,28,28),因为利用CNN需要先进行卷积和池化操作,所以需要保持图片的维度,经过处理之后,shape就变成了(60000,28,28,1),也就是60000张图片,每一张图片28(宽)*28(高)*1(单色)
x_train4D = x_train.reshape(x_train.shape[0],28,28,1).astype('float32')
x_test4D = x_test.reshape(x_test.shape[0],28,28,1).astype('float32')
#像素标准化
x_train,x_test = x_train4D/255.0,x_test4D/255.0
模型搭建
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=16,kernel_size=(5,5),padding='same',input_shape=(28,28,1),activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2,2)),
tf.keras.layers.Conv2D(filters=36,kernel_size=(5,5),padding='same',activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2,2)),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(10,activation='softmax')
])
CNN模型为两个卷积和池化层以及全连接层输出的小型网络。加入了Dropout层防止过拟合,提高模型的泛化能力。
模型训练
model.compile(loss='sparse_categorical_crossentropy',optimizer='adam',metrics=['acc'])
Model = model.fit(x=x_train,y=y_train,validation_split=0.2,epochs=20,batch_size=300,verbose=2)
我们所选取的loss函数为sparse_categorical_crossentropy函数,优化器选用的为adam,使用accuracy作为评判标准。对于训练集,我们分出80%作为训练集,20%作为测试集。一共训练20次,批训练尺寸为300.
“verbose=2”:显示训练过程。
训练结果如图所示:
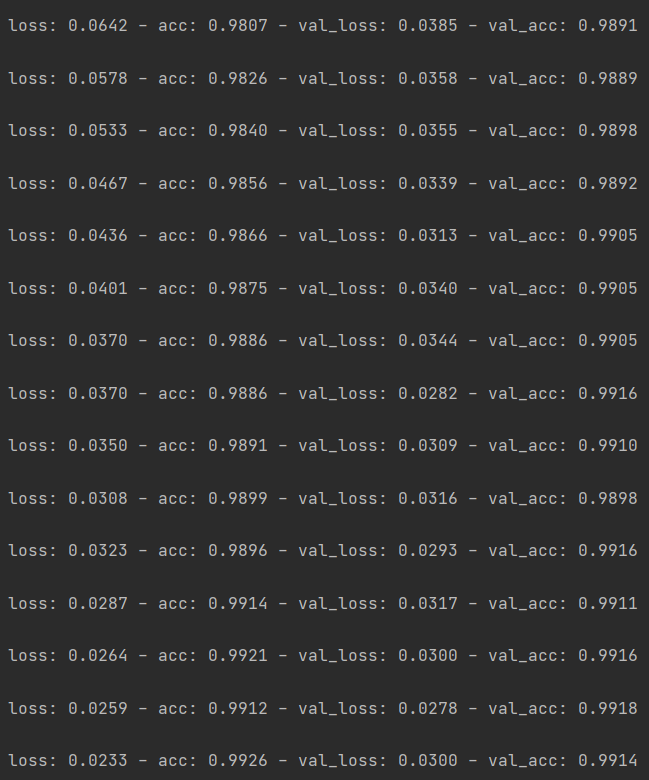
训练集的训练效果准确率高达99.2%,训练效果不错。
用搭建好的模型对测试集进行实验
model.evaluate(x_test,y_test,batch_size=200,verbose=2)
结果如下图所示:

没有出现过拟合的情况,正确率达到了99.3%。
线性回归实现手写数字识别
虽然标题为线性回归实现手写数字识别,但是也不知是用了线性回归,网络模型使用的是全连接层,没有CNN中的卷积和池化层,没有Dropout层。在更新参数的时候,用到的是线性回归方法。
导入模块和数据集
import os
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
(x,y),(x_val,y_val)=datasets.mnist.load_data()
这一部分与CNN大同小异
训练集数据预处理
#训练集数据预处理
x=tf.convert_to_tensor(x,dtype=tf.float32)/255.
y=tf.convert_to_tensor(y,dtype=tf.int32)##由于一开始读入的时候是numpy格式的,需要将其展开成tensor格式。
y=tf.one_hot(y,depth=10)##个人理解是,将每张图片的标签,弄成一个10维的向量。如果这个标签为1的话,那么在1那个位置就是1,其余地方为0
train_dataset = tf.data.Dataset.from_tensor_slices((x, y))#将图片单张取出来
train_dataset = train_dataset.batch(200)##批处理的尺度为200
数据预处理这一块,与CNN不同,因为我们这种方法,不需要用到卷积层和池化层,所以我们不需要保证每张图片都是(28 * 28),而是将其展成(1 * 784).
测试集数据预处理
x_test = tf.convert_to_tensor(x_val,dtype=tf.float32)/255.
y_test = tf.convert_to_tensor(y_val,dtype=tf.int32)
test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test))
test_db = test_db.batch(200)
测试集和训练集的数据预处理,差别在于没有tf.one_hot的过程,因为测试集的图片维度后来需要用到,就不能随意处理。
模型搭建
model = keras.Sequential([
layers.Dense(512,activation='relu'),##全连接层,784-512-256-10
layers.Dense(256,activation='relu'),
layers.Dense(10)
])
optimizer = optimizers.SGD(learning_rate=0.001)##学习率,也可以理解为步长
模型为简单的3层全连接层,激活函数为relu函数。
参数调整
def train_epoch(epoch):
for step,(x,y) in enumerate(train_dataset):##循环300次
with tf.GradientTape() as tape:
#[b,28,28]=>[b,784]将图片打平
x=tf.reshape(x,(-1,28*28))
out=model(x)
##[b,784]=>[b,10]
loss=tf.reduce_sum(tf.square(out-y))/x.shape[0]##out和y的欧氏距离平方和再除以n作为loss
##需要更新w1,w2,w3,b1,b2,b3,用这个函数直接返回的是loss对于wi的偏导,loss对于bi的偏导
grads=tape.gradient(loss,model.trainable_variables)
##更新参数
optimizer.apply_gradients(zip(grads,model.trainable_variables))
if step % 100 == 0:
print(epoch,step,'loss:',loss.numpy())
利用训练集调整的参数,对测试集进行测试
def test():
total_correct = 0
total_num = 0
for step,(x_test,y_test) in enumerate(test_db):
x_test=tf.reshape(x_test,(-1,28*28))##调整图片的维度
out = model(x_test)#利用训练好的模型对输入进行处理
probability = tf.nn.softmax(out,axis=1)#softmax函数处理为该图片为某一类别的概率
prediction = tf.argmax(input=probability,axis=1)#argmax函数挑选出最大的那个数的索引。这里我说的不是很清楚,大家可以百度一下argmax函数的功能
prediction = tf.cast(x=prediction,dtype=tf.int32)#转换为int类型
correct = tf.equal(x=prediction,y=y_test)#将预测与真正的结果作比较,返回有多少个位置相匹配
correct = tf.cast(x=correct,dtype=tf.int32)#转换成int类型
correct = tf.reduce_sum(input_tensor = correct)#求和
total_correct+=int (correct)
total_num+=x_test.shape[0]
acc=total_correct / total_num
print("测试集正确率:",acc)
训练过程
def train():#一共100次epoch
for epoch in range(100):
train_epoch(epoch)
test()
结果如下图所示:
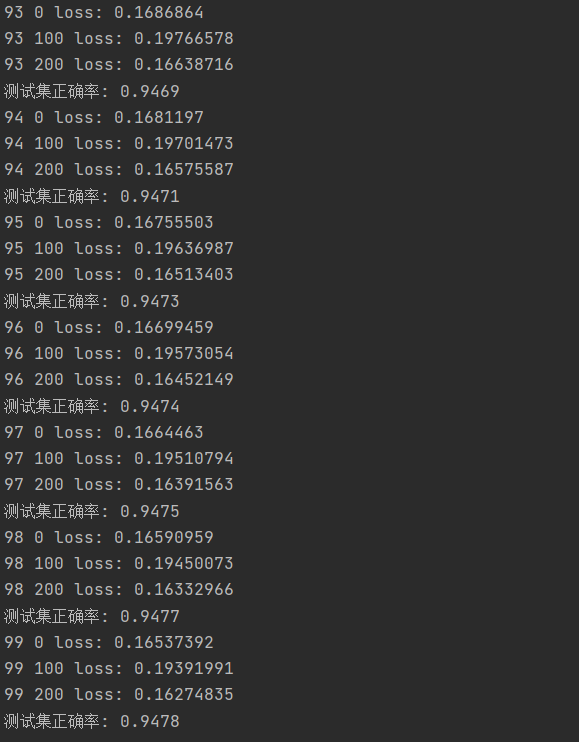
经过100次epoch之后,正确率维持在94.8%左右。可以看一下当做了30次epoch的时候,结果如下图所示:
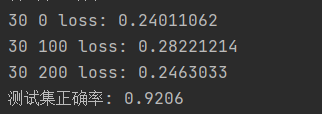
epoch次数多了,正确率确实高了,但是提升的速度越来越小。
综合对比:CNN实现手写数字识别比线性回归实现手写数字识别,正确率高很多。
最后
以上就是明理石头最近收集整理的关于基于tensorflow2.0利用CNN与线性回归两种方法实现手写数字识别的全部内容,更多相关基于tensorflow2内容请搜索靠谱客的其他文章。








发表评论 取消回复