文章目录
- 1. Flink 的类型系统
- 2. Flink 支持的数据类型
- 3. 类型提示(Type Hints)
- 4. 从kafka读取自定义类型的数据流
1. Flink 的类型系统
Flink 作为一个分布式处理框架,处理的是以数据对象作为元素的流。要分布式地处理这些数据,就不可避免地要面对数据的网络传输、状态的落盘和故障恢复等问题,这就需要对数据进行序列化和反序列化。
Flink 有自己一整套类型系统。Flink 使用“类型信息”(TypeInformation)来统一表示数据类型。TypeInformation 类是 Flink 中所有类型描述符的基类。它涵盖了类型的一些基本属性,并为每个数据类型生成特定的序列化器、反序列化器和比较器
2. Flink 支持的数据类型
Basic types: All Java primitives and their boxed form, plus void, String, Date, BigDecimal, and BigInteger.
Primitive arrays and Object arrays
Composite types:
------Flink Java Tuples (part of the Flink Java API): max 25 fields, null fields not supported
------Scala case classes (including Scala tuples): null fields not supported
------Row: tuples with arbitrary number of fields and support for null fields
------POJOs: classes that follow a certain bean-like pattern
Auxiliary types (Option, Either, Lists, Maps, …)
Generic types: These will not be serialized by Flink itself, but by Kryo.
(1)基本类型
所有 Java 基本类型及其包装类,再加上 Void、String、Date、BigDecimal 和 BigInteger
(2)数组类型
包括基本类型数组(PRIMITIVE_ARRAY)和对象数组(OBJECT_ARRAY)
(3)复合数据类型
Java 元组类型(TUPLE):这是 Flink 内置的元组类型,是 Java API 的一部分。最多25 个字段,也就是从 Tuple0~Tuple25,不支持空字段
Scala 样例类及 Scala 元组:不支持空字段
行类型(ROW):可以认为是具有任意个字段的元组,并支持空字段
POJO:Flink 自定义的类似于 Java bean 模式的类
(4)辅助类型
Option、Either、List、Map 等
(5)泛型类型(GENERIC)
Flink 支持所有的 Java 类和 Scala 类。不过如果没有按照POJO 类型的要求来定义,就会被 Flink 当作泛型类来处理。Flink 会把泛型类型当作黑盒,无法获取它们内部的属性;它们也不是由 Flink 本身序列化的,而是由 Kryo 序列化的。
在项目实践中,往往会将流处理程序中的元素类型定为 Flink 的 POJO 类型。Flink 对 POJO 类型的要求如下:
类是公共的(public)和独立的(没有非静态的内部类);
类有一个公共的无参构造方法;
类中的所有字段是 public 且非 final 的;或者有一个公共的 getter 和 setter 方法,这些方法需要符合 Java bean 的命名规范
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user, String url, Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString() {
return "Event{" +
"user='" + user + ''' +
", url='" + url + ''' +
", timestamp=" + new Timestamp(timestamp) +
'}';
}
}
3. 类型提示(Type Hints)
Flink 具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。但是,由于 Java 中泛型擦除的存在,在某些特殊情况下(如 Lambda 表达式中),自动提取的信息是不够精细的,需要显式地提供类型信息,才能使应用程序正常工作或提高其性能
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
Flink 专门提供了 TypeHint 类,它可以捕获泛型的类型信息,并且一直记录下来,为运行
时提供足够的信息。同样可以通过.returns()方法,明确地指定转换之后的 DataStream 里元素的类型
returns(new TypeHint<Tuple2<Integer, SomeType>>(){})
4. 从kafka读取自定义类型的数据流
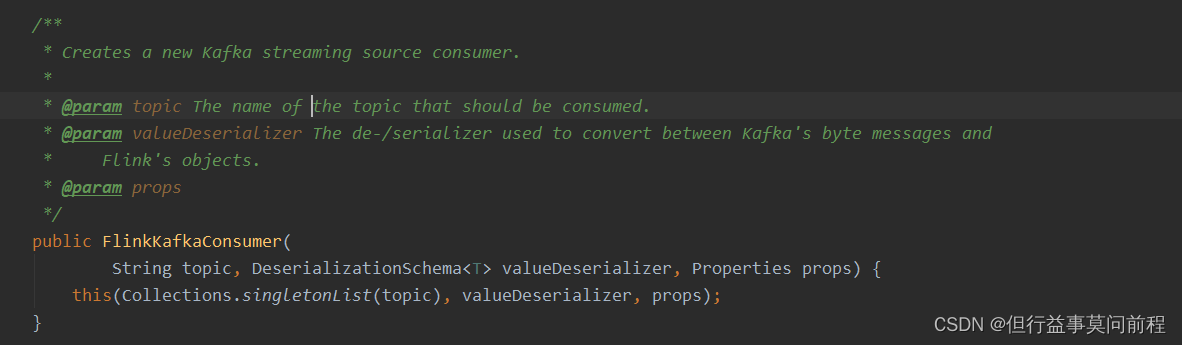
创建 FlinkKafkaConsumer 时需要传入三个参数:
第一个参数 topic,定义了从哪些主题中读取数据。可以是一个 topic,也可以是 topic列表,还可以是匹配所有想要读取的 topic 的正则表达式。当从多个 topic 中读取数据时,Kafka 连接器将会处理所有 topic 的分区,将这些分区的数据放到一条流中去
第二个参数是一个 DeserializationSchema 或者 KeyedDeserializationSchema。Kafka 消息被存储为原始的字节数据,所以需要反序列化成 Java 或者 Scala 对象。DeserializationSchema 和 KeyedDeserializationSchema 是公共接口,所以可以自定义反序列化逻辑
第三个参数是一个 Properties 对象,设置了 Kafka 客户端的一些属性
自定义反序列化器:
需要实现反序列化方法以及指定TypeInformation
import cn.hutool.json.JSONUtil;
import com.cz.pojo.Event;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import java.io.IOException;
public class EventSerializer implements DeserializationSchema<Event> {
@Override
public Event deserialize(byte[] message) throws IOException {
return JSONUtil.toBean(new String(message), Event.class);
}
@Override
public boolean isEndOfStream(Event nextElement) {
return false;
}
@Override
public TypeInformation<Event> getProducedType() {
return TypeInformation.of(Event.class);
}
}
作业:
import com.cz.pojo.Event;
import com.cz.source.my.EventSerializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class SourceKafkaTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.0.114:29092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
DataStreamSource<Event> stream = env.addSource(new FlinkKafkaConsumer<Event>(
"clicks",
new EventSerializer(),
properties
));
stream.print("Kafka");
env.execute();
}
}

最后
以上就是想人陪口红最近收集整理的关于Flink 支持的数据类型、从kafka读取自定义POJO类型的数据流的全部内容,更多相关Flink内容请搜索靠谱客的其他文章。








发表评论 取消回复