HashMap是我们最常用的数据结构之一,它方便高效,但遗憾的是,HashMap是线程不安全的,在并发环境下,在HashMap的扩容过程中,可能造成散列表的循环锁死。而线程安全的HashTable使用了大量Synchronized锁,导致了效率非常低下。幸运的是,并发编程大师Doug Lea为我们提供了ConcurrentHashMap,它是线程安全版的HashMap。这篇文章将为大家简单分析一下HashMap死循环的原因和ConcurrentHashMap的实现原理。在此之前,想要熟悉HashMap实现原理的朋友可以参考我的文章《Java源码剖析之HashMap 》。
1 HashMap锁死问题的分析
HashMap在并发执行put操作时会引起死循环,这是因为并发会导致HashMap的Entry链表形成环形数据结构,这样,Entry的next节点永不为null,在散列表扩容的时候,形成循环的桶就永远不会走到尽头null,产生死循环。
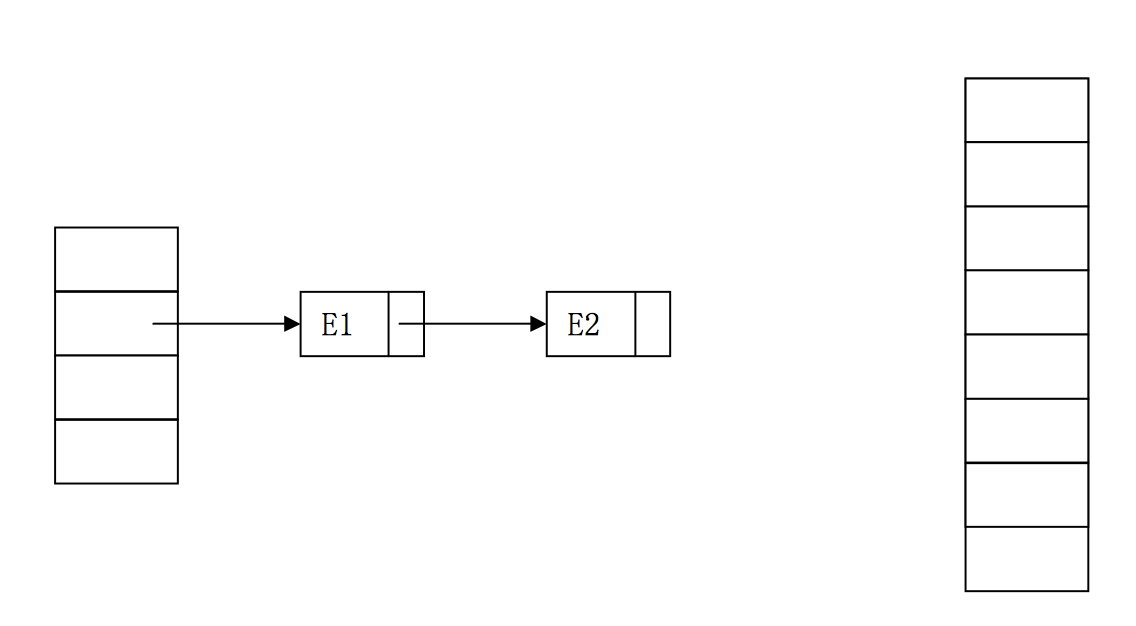
单线程时的正确扩容
// 扩容操作,从一个数组转移到另一个数组
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next; //假设第一个线程执行到这里
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null); // 可能导致死循环
}
}
}
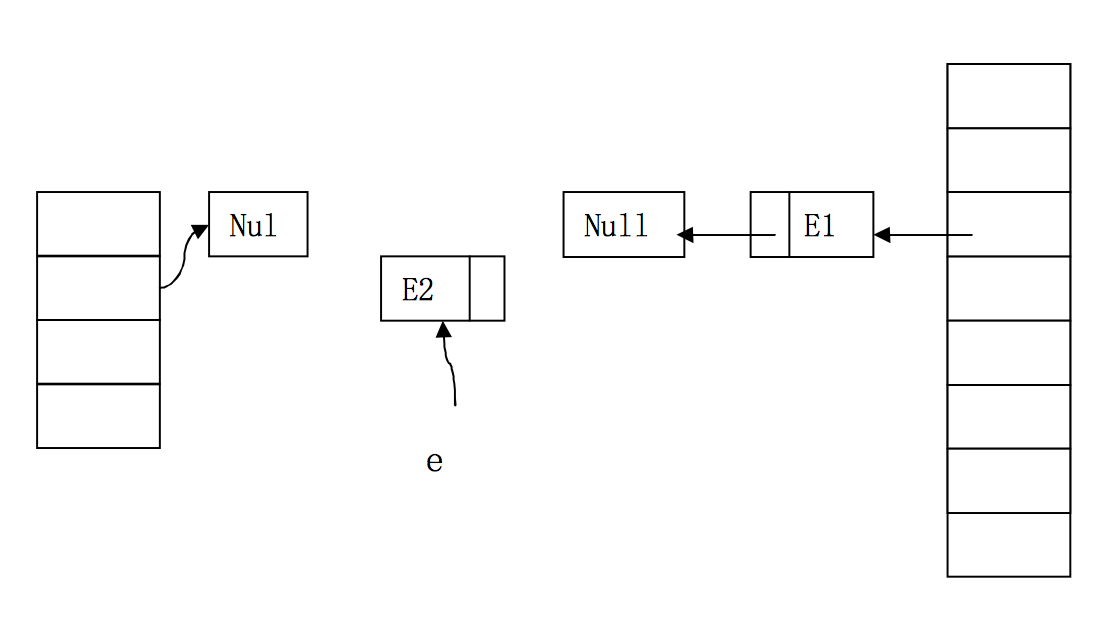
双线程并发下的错误扩容
右边两个桶分别属于线程1和线程2,他们并发执行了扩容。此时,线程1已经将E1和E2顺利转移到了新桶中。接着,线程2运行到了代码的第9行,已经获得了E1和E1.next。
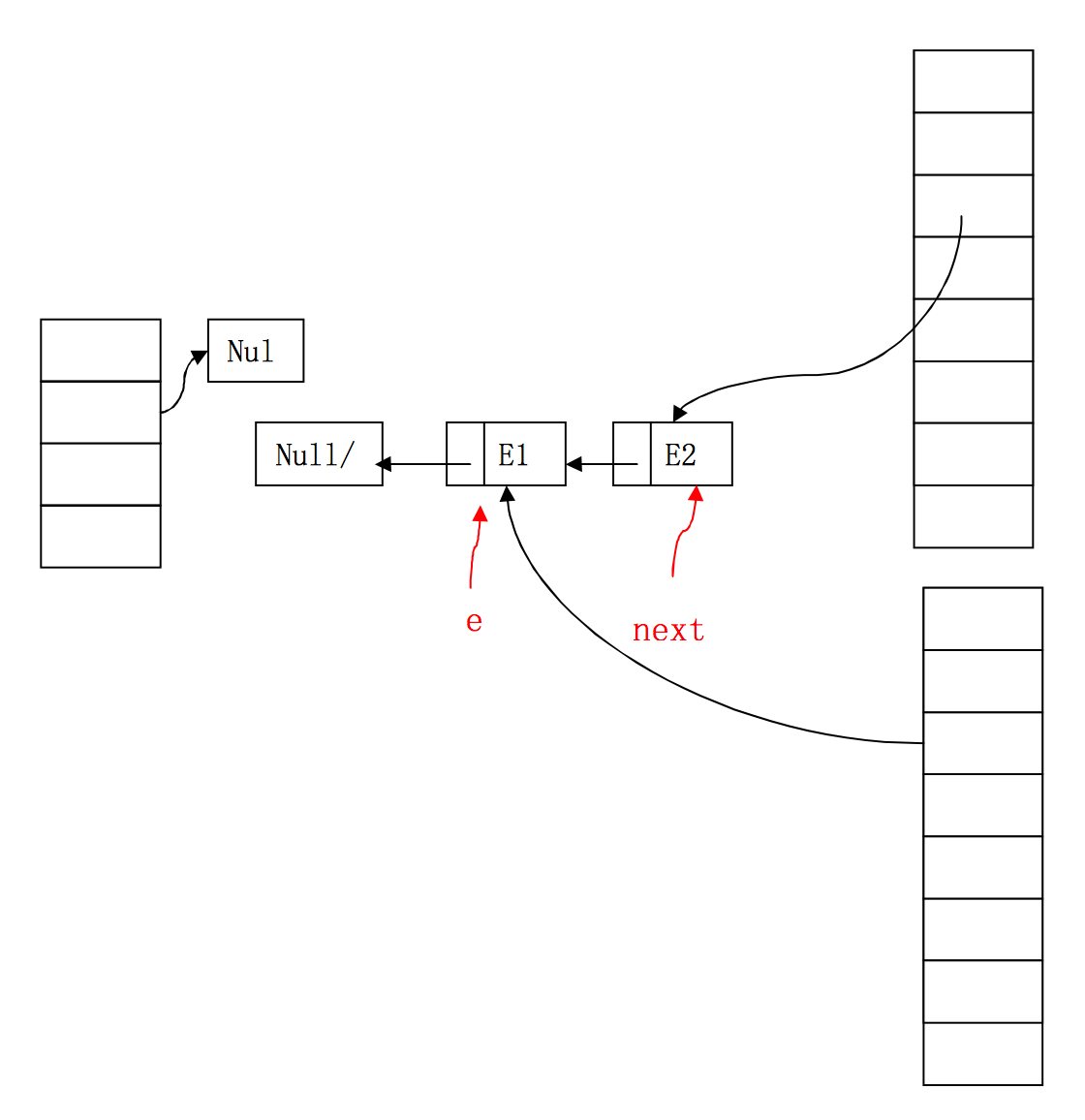
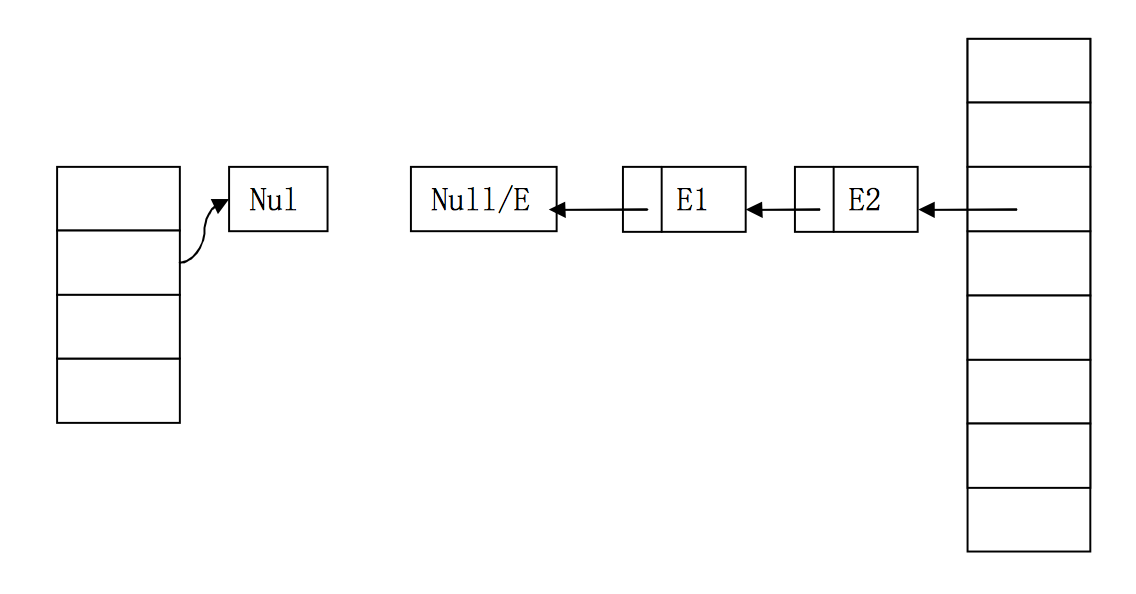
线程2将E1取到自己的桶中,而且虽然E1.next已经被线程1设为null,但在此之前,线程2已经获得了E1.next即E2。
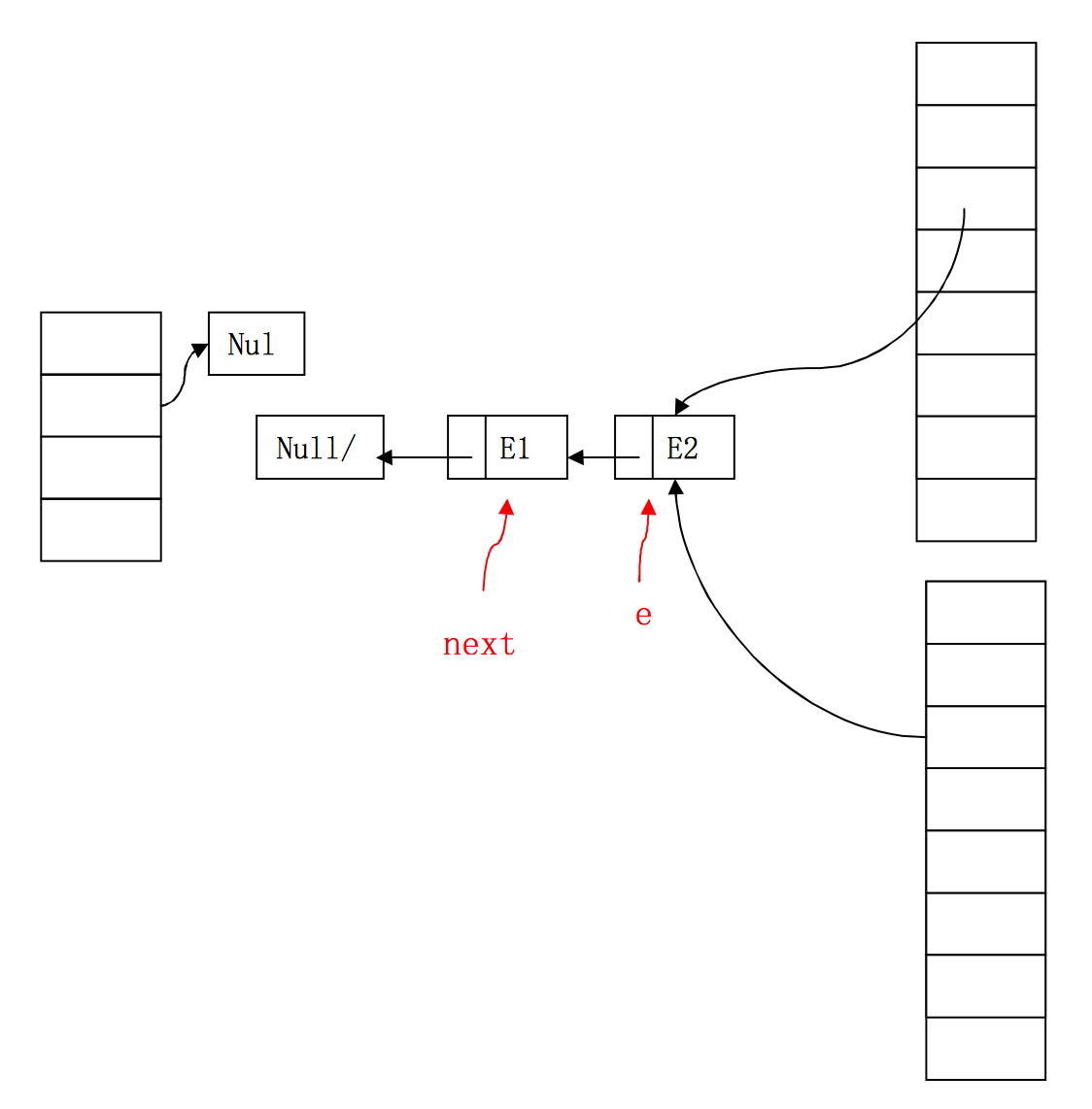
因此,线程2成功取到E2,并查看下一个Entry,本来,E2.next为null,但线程1已经反置了顺序,E2.next变成了E1!因此,线程2会继续执行添加元素的操作!
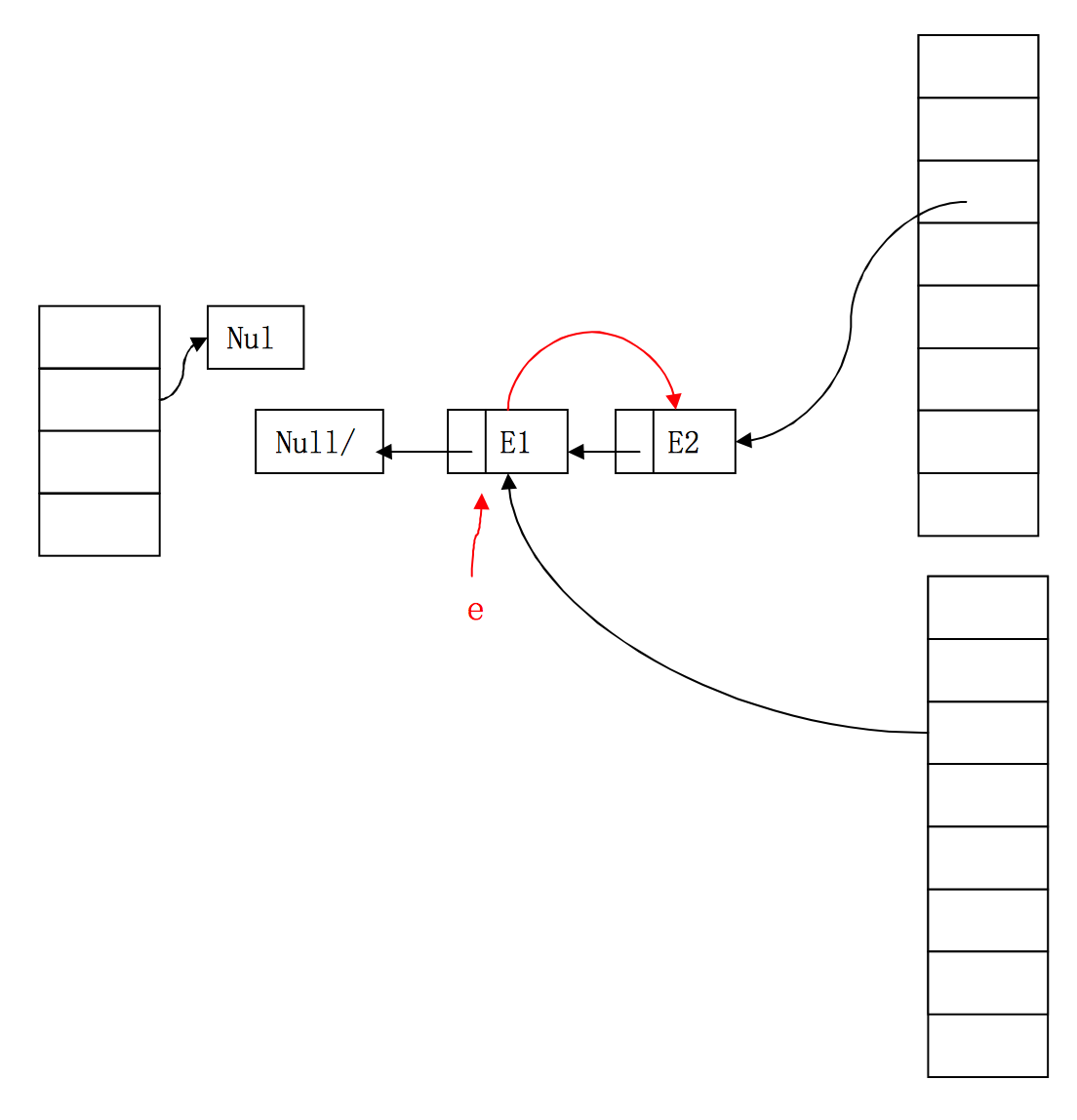
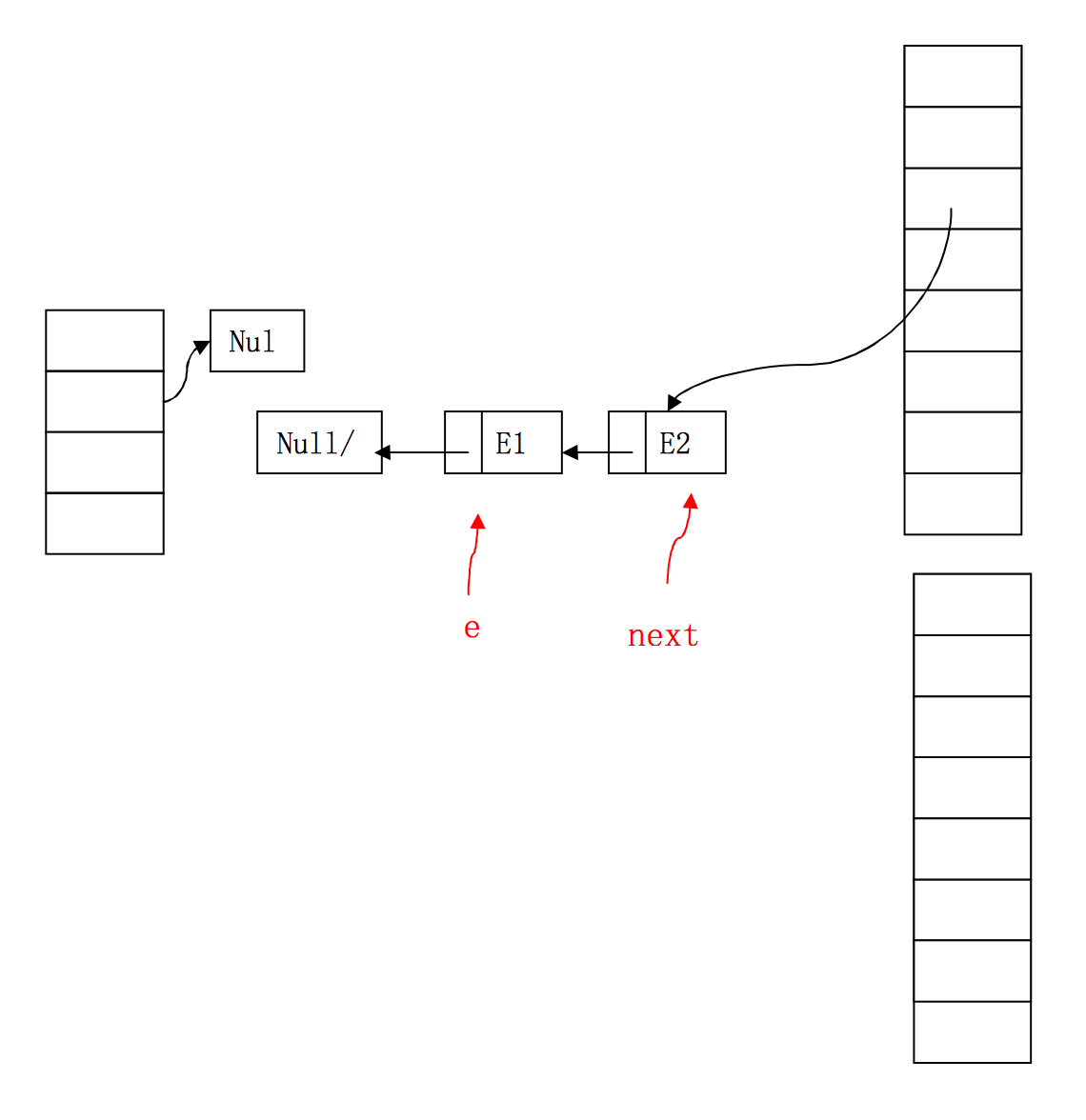
此时可以很清楚的看到,E2线程中的Entry已经形成了一个环形结构,扩容中对entry的遍历永远不会结束,造成了HashMap的死循环,put操作也不会停止了。
2 ConcurrentHashMap的实现
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因是所有访问HashTable的线程都需要竞争同一把锁。假如容器里有多把锁,每一把锁用于锁容器中的一部分数据,那么当多线程访问容器中不同段的数据时,线程间将不存在锁竞争,从而有效提高访问效率,这就是ConcurrentHashMap的分段锁技术。首先将数据分成一段一段地存储,再给每段数据配一把锁,当线程占用其中一段数据的时候,其他段的数据也能被其他线程访问。
结构解析
ConcurrentHashMap和Hashtable主要区别就是围绕着锁的粒度以及如何锁,可以简单理解成把一个大的HashTable分解成多个,形成了锁分离。如图:
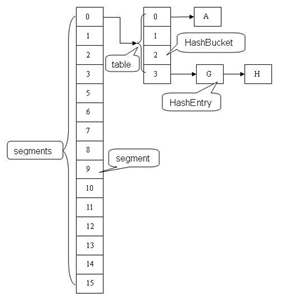
而HashTable则是锁住了整张hash表。
源码解析
get操作
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}
put操作
由于put方法里需要对共享变量进行写入操作,所以为了线程安全,在操作共享变量时必须得加锁。Put方法首先定位到Segment,然后在Segment里进行插入操作。插入操作需要经历两个步骤,第一步判断是否需要对Segment里的HashEntry数组进行扩容,第二步定位添加元素的位置然后放在HashEntry数组里。
是否需要扩容。在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold),如果超过阀值,数组进行扩容。值得一提的是,Segment的扩容判断比HashMap更恰当,因为HashMap是在插入元素后判断元素是否已经到达容量的,如果到达了就进行扩容,但是很有可能扩容之后没有新元素插入,这时HashMap就进行了一次无效的扩容。
如何扩容。扩容的时候首先会创建一个两倍于原容量的数组,然后将原数组里的元素进行再hash后插入到新的数组里。为了高效ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment进行扩容。
size操作
如果我们要统计整个ConcurrentHashMap里元素的大小,就必须统计所有Segment里元素的大小后求和。Segment里的全局变量count是一个volatile变量,那么在多线程场景下,我们是不是直接把所有Segment的count相加就可以得到整个ConcurrentHashMap大小了呢?不是的,虽然相加时可以获取每个Segment的count的最新值,但是拿到之后可能累加前使用的count发生了变化,那么统计结果就不准了。所以最安全的做法,是在统计size的时候把所有Segment的put,remove和clean方法全部锁住,但是这种做法显然非常低效。
因为在累加count操作过程中,之前累加过的count发生变化的几率非常小,所以ConcurrentHashMap的做法是先尝试2次通过不锁住Segment的方式来统计各个Segment大小,如果统计的过程中,容器的count发生了变化,则再采用加锁的方式来统计所有Segment的大小。
那么ConcurrentHashMap是如何判断在统计的时候容器是否发生了变化呢?使用modCount变量,在put , remove和clean方法里操作元素前都会将变量modCount进行加1,那么在统计size前后比较modCount是否发生变化,从而得知容器的大小是否发生变化。
最后
以上就是从容苗条最近收集整理的关于Java并发容器ConcurrentHashMap原理及HashMap死循环原因的分析1 HashMap锁死问题的分析2 ConcurrentHashMap的实现的全部内容,更多相关Java并发容器ConcurrentHashMap原理及HashMap死循环原因的分析1内容请搜索靠谱客的其他文章。








发表评论 取消回复