环境
dubbo版本:2.7.8
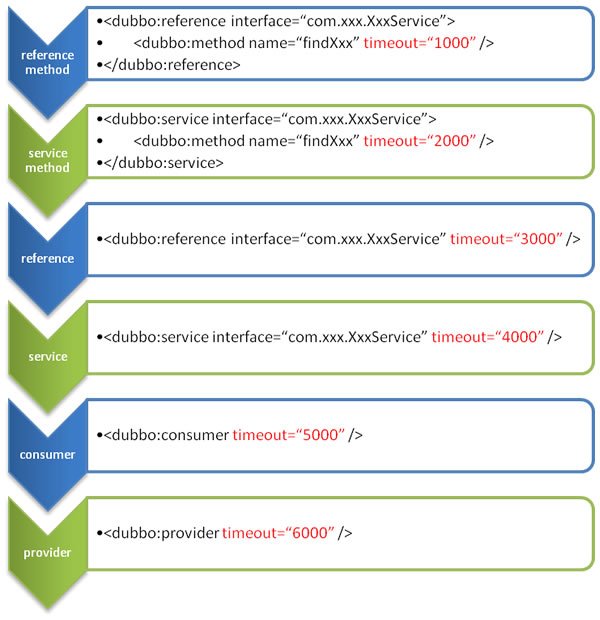
超时配置
下图显示了timeout配置的查找顺序:
- 方法级优先,接口级次之,全局配置再次之。
- 如果级别一样,则消费方优先,提供方次之。
其中,服务提供方配置,通过URL经由注册中心传递给消费方。
源码分析
HashedWheelTimer
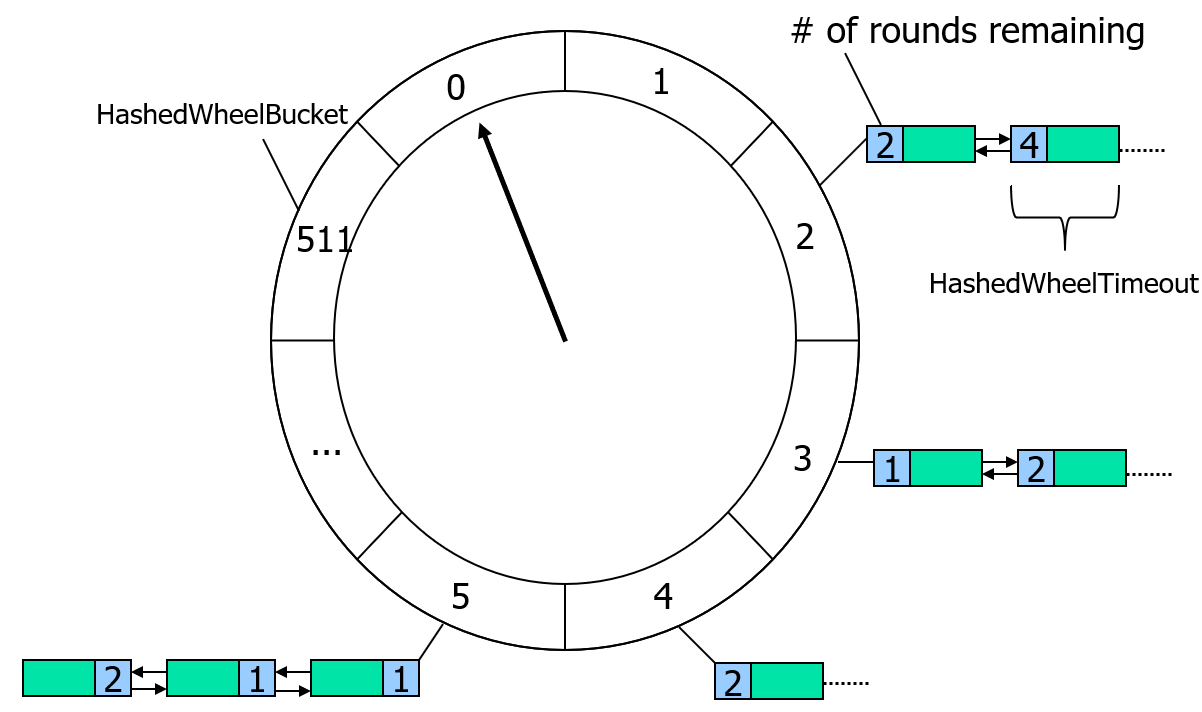
HashedWheelTimer是一个计时器。主要的数据结构是一个HashedWheelBucket数组,类似于哈希表(下文称作wheel)。
HashedWheelTimer具体如何计时的,我的理解是:wheel分为多个bucket,顺序循环遍历,从一个bucket到另一个bucket经过固定的时间。每个bucket可放置多个定时任务。定时任务都有过期时间,根据过期时间可以计算出定时任务的剩余圈数和放置位置。遍历到某个bucket时,遍历其中的定时任务,若该任务剩余圈数<=0时,则需要执行该任务,否则剩余圈数-1。
下面是HashedWheelTimer.Worker的run方法的主要逻辑
private long tick;
@Override
public void run() {
... // 省略无关代码
do {
final long deadline = waitForNextTick(); // 等待固定时间
if (deadline > 0) {
int idx = (int) (tick & mask);
processCancelledTasks(); // 从bucket中移除取消的timeout
HashedWheelBucket bucket = wheel[idx];
transferTimeoutsToBuckets(); // 把新的timeout放到bucket中
bucket.expireTimeouts(deadline); // 从bucket中移除到期timeout
tick++;
}
} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);
... // 省略无关代码
}
在dubbo源码中,有2个地方用到了HashedWheelTimer,分别在DefaultFuture类和HeaderExchangeClient类中,分别对应dubbo-future-timeout和dubbo-client-idleCheck这两个线程,当项目启动时这2个线程就开始运行了。dubbo-client-idleCheck负责重连provider的,这里暂不分析。dubbo-future-timeout负责RPC超时管理的。
RPC超时如何交给HashedWheelTimer管理
把HashedWheelTimeout放到wheel中
RPC过程会创建DefaultFuture对象,同时会调用DefaultFuture中的HashedWheelTimer的newTimeout方法
@Override
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {
... // 省略一些空值抛异常代码
long pendingTimeoutsCount = pendingTimeouts.incrementAndGet();
if (maxPendingTimeouts > 0 && pendingTimeoutsCount > maxPendingTimeouts) {
pendingTimeouts.decrementAndGet();
throw new RejectedExecutionException("Number of pending timeouts ("
+ pendingTimeoutsCount + ") is greater than or equal to maximum allowed pending "
+ "timeouts (" + maxPendingTimeouts + ")");
}
start(); // 一个无关紧要的方法
// Add the timeout to the timeout queue which will be processed on the next tick.
// During processing all the queued HashedWheelTimeouts will be added to the correct HashedWheelBucket.
long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;
// Guard against overflow.
if (delay > 0 && deadline < 0) {
deadline = Long.MAX_VALUE;
}
HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline);
timeouts.add(timeout);
return timeout;
}
newTimeout方法主要是创建了HashedWheelTimeout对象并添加到timeouts这个链表中,其中传入的task是DefaultFuture的TimeoutCheckTask。
然后DefaultFuture设置好了之后,开始RPC发送请求。
与此同时,在HashedWheelTimer的线程中,一直在执行HashedWheelTimer.Worker的run方法,在run方法的transferTimeoutsToBuckets方法中,把之前添加到timeouts链表的HashedWheelTimeout对象拿出来,计算好剩余圈数和放置的index后,添加到对应的bucket中,之后就成功交给HashedWheelTimer进行超时管理。
private void transferTimeoutsToBuckets() {
// transfer only max. 100000 timeouts per tick to prevent a thread to stale the workerThread when it just
// adds new timeouts in a loop.
for (int i = 0; i < 100000; i++) {
HashedWheelTimeout timeout = timeouts.poll();
if (timeout == null) {
// all processed
break;
}
if (timeout.state() == HashedWheelTimeout.ST_CANCELLED) {
// Was cancelled in the meantime.
continue;
}
long calculated = timeout.deadline / tickDuration; // 注意timeout.deadline是从HashedWheelTimer初始化时的startTime开始的,所以下面calculated要减去tick
timeout.remainingRounds = (calculated - tick) / wheel.length;
// Ensure we don't schedule for past.
final long ticks = Math.max(calculated, tick);
int stopIndex = (int) (ticks & mask);
HashedWheelBucket bucket = wheel[stopIndex];
bucket.addTimeout(timeout);
}
}
判断超时后的处理
HashedWheelTimer.Worker的run方法包含了HashedWheelBucket的expireTimeouts方法
/**
*Expire all HashedWheelTimeouts for the given deadline.
*/
void expireTimeouts(long deadline) {
HashedWheelTimeout timeout = head;
// process all timeouts
while (timeout != null) {
HashedWheelTimeout next = timeout.next;
if (timeout.remainingRounds <= 0) {
next = remove(timeout);
if (timeout.deadline <= deadline) { // 到期了
timeout.expire();
} else {
// The timeout was placed into a wrong slot. This should never happen.
throw new IllegalStateException(String.format(
"timeout.deadline (%d) > deadline (%d)", timeout.deadline, deadline));
}
} else if (timeout.isCancelled()) {
next = remove(timeout);
} else {
timeout.remainingRounds--;
}
timeout = next;
}
}
其中如果timeout判断为到期,则运行HashedWheelTimeout的expire方法
public void expire() {
if (!compareAndSetState(ST_INIT, ST_EXPIRED)) {
return;
}
try {
task.run(this);
} catch (Throwable t) {
if (logger.isWarnEnabled()) {
logger.warn("An exception was thrown by " + TimerTask.class.getSimpleName() + '.', t);
}
}
}
就是把之前HashedWheelTimeout创建时,传入的task的run方法执行,这个task也就是上面说到的DefaultFuture的TimeoutCheckTask。下面是TimeoutCheckTask的run方法
@Override
public void run(Timeout timeout) {
DefaultFuture future = DefaultFuture.getFuture(requestID);
if (future == null || future.isDone()) { // 判断future中有无数据;或负责RPC的线程运行再快一点,future早已为null
return;
}
if (future.getExecutor() != null) {
future.getExecutor().execute(() -> notifyTimeout(future));
} else {
notifyTimeout(future);
}
}
private void notifyTimeout(DefaultFuture future) {
// create exception response.
Response timeoutResponse = new Response(future.getId());
// set timeout status.
timeoutResponse.setStatus(future.isSent() ? Response.SERVER_TIMEOUT : Response.CLIENT_TIMEOUT);
timeoutResponse.setErrorMessage(future.getTimeoutMessage(true));
// handle response.
DefaultFuture.received(future.getChannel(), timeoutResponse, true);
}
在future.getTimeoutMessage方法中,设置了RPC超时错误信息Waiting server-side response timeout...或Sending request timeout in client-side...,之后就报org.apache.dubbo.remoting.TimeoutException了。
思考
数值溢出问题
下面是HashedWheelTimer的waitForNextTick方法
/**
* calculate goal nanoTime from startTime and current tick number,
* then wait until that goal has been reached.
*
* @return Long.MIN_VALUE if received a shutdown request,
* current time otherwise (with Long.MIN_VALUE changed by +1)
*/
private long waitForNextTick() {
long deadline = tickDuration * (tick + 1);
for (; ; ) {
final long currentTime = System.nanoTime() - startTime;
long sleepTimeMs = (deadline - currentTime + 999999) / 1000000;
if (sleepTimeMs <= 0) {
if (currentTime == Long.MIN_VALUE) {
return -Long.MAX_VALUE;
} else {
return currentTime;
}
}
if (isWindows()) {
sleepTimeMs = sleepTimeMs / 10 * 10;
}
try {
Thread.sleep(sleepTimeMs);
} catch (InterruptedException ignored) {
if (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_SHUTDOWN) {
return Long.MIN_VALUE;
}
}
}
}
上面的deadline,tick和currentTime都是long类型,且都在不断自增肯定会遇到溢出问题,那么溢出是否会对计时造成影响呢?
在dubbo的HashedWheelTimer中,tickDuration默认值为30000000。下表为tick与该tick计算出的deadline的对应关系
| tick | deadline |
|---|---|
| 307445734560 | 9223372036830000000 |
| 307445734561 | -9223372036849551616 |
| 614891469122 | -19551616 |
| 614891469123 | 10448384 |
| 9223372036854775807 | 0 |
| -9223372036854775808 | 30000000 |
可以知道deadline之间还是保持着tickDuration的固定时间间隔。
再举个极端点的例子:计算的deadline溢出变为负数,但是currentTime = System.nanoTime() - startTime;得到正数。其实最后sleepTimeMs = (deadline - currentTime + 999999) / 1000000;计算出的sleepTimeMs还是一个比tickDuration小的非负数。
结论是:数值溢出确实让人思考比较绕,但是它不影响计算出的等待时间。
最后
以上就是独特诺言最近收集整理的关于dubbo超时机制源码浅析环境超时配置源码分析思考的全部内容,更多相关dubbo超时机制源码浅析环境超时配置源码分析思考内容请搜索靠谱客的其他文章。
![[Apache Dubbo] Spring Boot 整合 Dubbo 实战[Apache Dubbo] Spring Boot 整合 Dubbo 实战](https://www.shuijiaxian.com/files_image/reation/bcimg25.png)




![Dubbo服务重启后不停报错[DUBBO] disconected from 问题原因解析](https://www.shuijiaxian.com/files_image/reation/bcimg3.png)


发表评论 取消回复