Hadoop生态圈-HBase的HFile创建方式
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
废话不多说,直接上代码,想说的话都在代码的注释里面。
一.环境准备
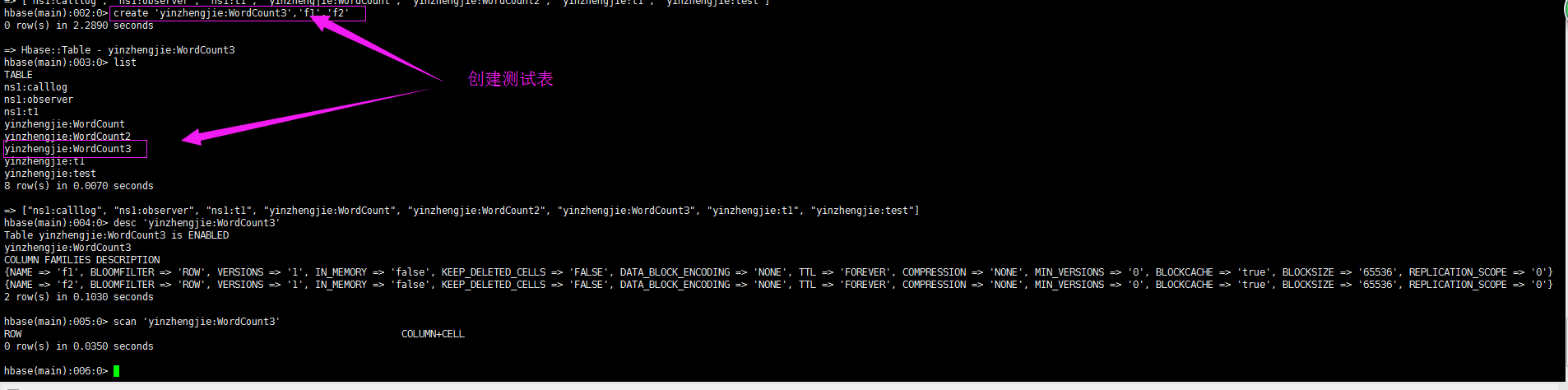
list
create 'yinzhengjie:WordCount3','f1','f2'
list
desc 'yinzhengjie:WordCount3'
scan 'yinzhengjie:WordCount3'
二.编写HFile创建方式的代码
1>.编写Map端代码
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.hbase.hfile; 7 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.LongWritable; 10 import org.apache.hadoop.io.Text; 11 import org.apache.hadoop.mapreduce.Mapper; 12 13 import java.io.IOException; 14 15 public class HFileOutputMapper extends Mapper<LongWritable, Text, Text, IntWritable> { 16 @Override 17 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 18 //得到一行数据 19 String line = value.toString(); 20 String[] arr = line.split(" "); 21 // 22 for (String word : arr){ 23 context.write(new Text(word),new IntWritable(1)); 24 } 25 } 26 }
2>.编写Reducer端代码
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.hbase.hfile; 7 8 import org.apache.hadoop.hbase.Cell; 9 import org.apache.hadoop.hbase.CellUtil; 10 import org.apache.hadoop.hbase.KeyValue; 11 import org.apache.hadoop.hbase.io.ImmutableBytesWritable; 12 import org.apache.hadoop.hbase.util.Bytes; 13 import org.apache.hadoop.io.IntWritable; 14 import org.apache.hadoop.io.Text; 15 import org.apache.hadoop.mapreduce.Reducer; 16 17 import java.io.IOException; 18 19 public class HFileOutputReducer extends Reducer<Text,IntWritable,ImmutableBytesWritable,Cell> { 20 @Override 21 protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 22 int sum = 0; 23 for (IntWritable value : values) { 24 sum += value.get(); 25 } 26 if(key.toString().length() > 0){ 27 ImmutableBytesWritable outKey = new ImmutableBytesWritable(Bytes.toBytes(key.toString())); 28 //创建cell 29 Cell cell = CellUtil.createCell(Bytes.toBytes(key.toString()), 30 Bytes.toBytes("f1"), Bytes.toBytes("count"),System.currentTimeMillis(), 31 KeyValue.Type.Minimum,Bytes.toBytes(sum+""),null); 32 context.write(outKey,cell); 33 } 34 } 35 }
3>.编写主程序代码
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.hbase.hfile; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.Path; 10 import org.apache.hadoop.hbase.Cell; 11 import org.apache.hadoop.hbase.HBaseConfiguration; 12 import org.apache.hadoop.hbase.HTableDescriptor; 13 import org.apache.hadoop.hbase.TableName; 14 import org.apache.hadoop.hbase.client.Connection; 15 import org.apache.hadoop.hbase.client.ConnectionFactory; 16 import org.apache.hadoop.hbase.io.ImmutableBytesWritable; 17 import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2; 18 import org.apache.hadoop.io.IntWritable; 19 import org.apache.hadoop.io.Text; 20 import org.apache.hadoop.mapreduce.Job; 21 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 22 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 23 24 public class App { 25 26 public static void main(String[] args) throws Exception { 27 28 System.setProperty("HADOOP_USER_NAME", "yinzhengjie"); 29 Configuration conf = HBaseConfiguration.create(); 30 conf.set("fs.defaultFS","file:///"); 31 Connection conn = ConnectionFactory.createConnection(conf); 32 Job job = Job.getInstance(conf); 33 job.setJobName("HFile WordCount"); 34 job.setJarByClass(App.class); 35 job.setMapperClass(HFileOutputMapper.class); 36 job.setReducerClass(HFileOutputReducer.class); 37 //设置输出格式 38 job.setOutputFormatClass(HFileOutputFormat2.class); 39 //设置路径 40 FileInputFormat.addInputPath(job,new Path("file:///D:\BigData\yinzhengjieData\word.txt")); 41 FileOutputFormat.setOutputPath(job,new Path("file:///D:\BigData\yinzhengjieData\hfile")); 42 //设置输出k-v 43 job.setOutputKeyClass(ImmutableBytesWritable.class); 44 job.setOutputValueClass(Cell.class); 45 //设置map端输出k-v 46 job.setMapOutputKeyClass(Text.class); 47 job.setMapOutputValueClass(IntWritable.class); 48 /** 49 * 配置和"yinzhengjie:WordCount3"进行关联,也就是说"yinzhengjie:WordCount3"这个表必须在HBase数据库中存在, 50 * 实际操作是以"yinzhengjie:WordCount3"为模板,便于生成HFile文件! 51 */ 52 HFileOutputFormat2.configureIncrementalLoad(job, new HTableDescriptor(TableName.valueOf("yinzhengjie:WordCount3")), 53 conn.getRegionLocator(TableName.valueOf("yinzhengjie:WordCount3")) ); 54 job.waitForCompletion(true); 55 } 56 }
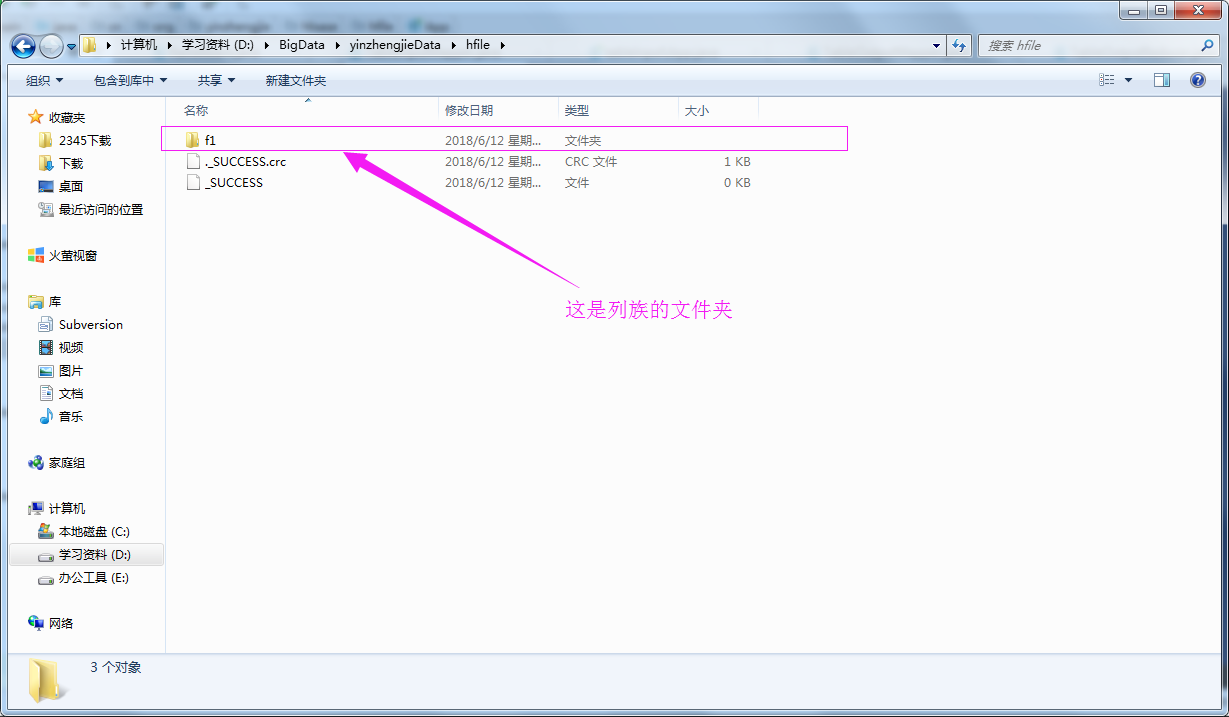
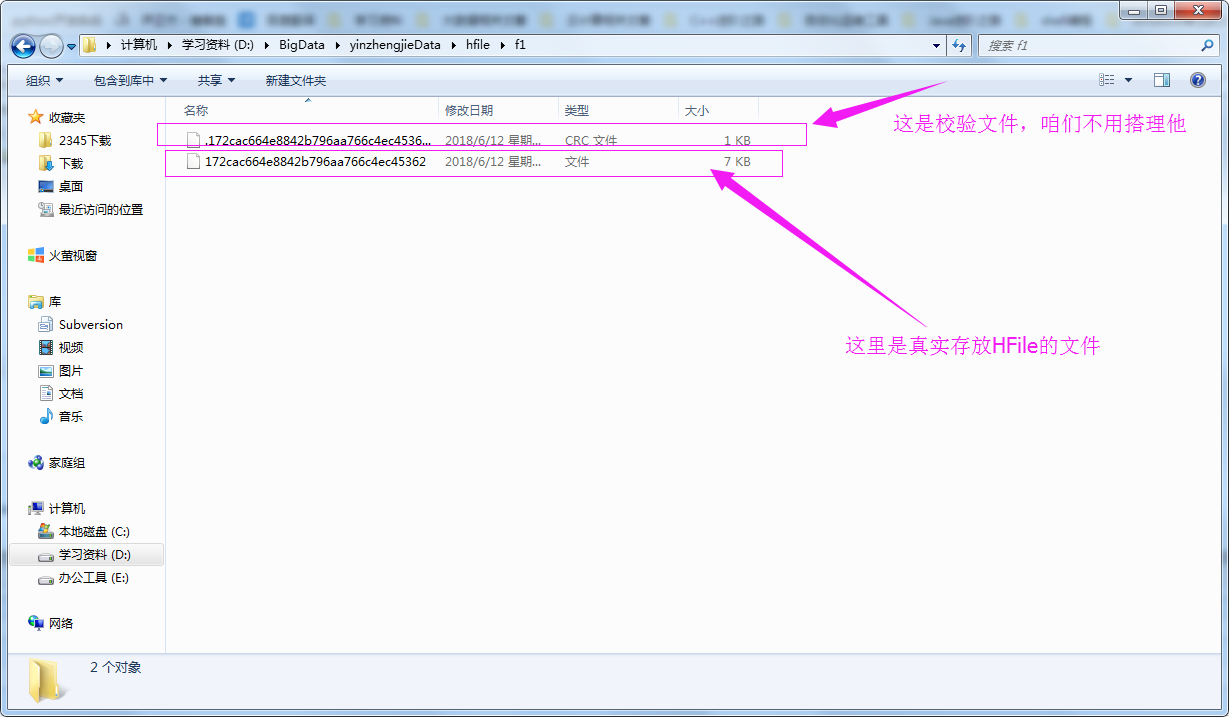
4>.查看测试结果
最后
以上就是朴素蚂蚁最近收集整理的关于Hadoop生态圈-HBase的HFile创建方式的全部内容,更多相关Hadoop生态圈-HBase内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复