1、中文同义词替换时,常用到Word2Vec,以下说法错误的是
A. Word2Vec基于概率统计
B. Word2Vec结果符合当前语料环境
C. Word2Vec得到的都是语义上的同义词
D. Word2Vec受限于训练语料的数量和质量
参考答案:C
解析:Word2Vec是常用的词向量表示,它采用的是同等上下文环境下的词语具有相同的词向量,而并非相同的含义。例如,我使用和朋友聊天。我使用<微信>和朋友聊天。这两句话只要上下文一样,那么QQ和微信的词向量表示也相同。当然也有我爱<中国>和我爱<中华人民共和国>这两个词在语义上的表示是相同的。
2、假定你用一个线性SVM分类器求解二类分类问题,如下图所示,这些用红色圆圈起来的点表示支持向量
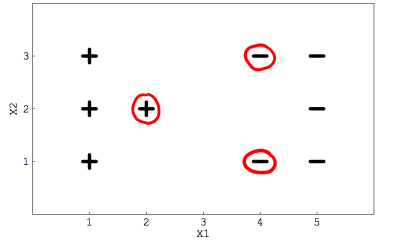
如果移除这些圈起来的数据,决策边界(即分离超平面)是否会发生改变?
A. 会
B. 不会
参考答案:A
解析:SVM的决策边界取决于支持向量,支持向量发生改变,其决策边界也会发生改变。
3、如果将数据中除圈起来的三个点以外的其他数据全部移除,那么决策边界是否会改变?
A.会
B.不会
参考答案:B
解析:同上题。
4、关于SVM泛化误差描述正确的是
A. 超平面与支持向量之间距离
B. SVM对未知数据的预测能力
C. SVM的误差阈值
最后
以上就是坚定乌龟最近收集整理的关于机器学习习题(18)的全部内容,更多相关机器学习习题(18)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复