狄利克雷分布主题模型LDA
文章目录
- 狄利克雷分布主题模型LDA
- 1、整体把握LDA
- 2、前提知识
- 2.1 gamma函数
- 2.2 四个分布
- 2.2.1 二项分布
- 2.2.2 多项分布
- 2.2.3 Beta分布
- 2.2.3 Dirichlet分布
- 2.3 一个概念和一个理念
- 2.3.1 先验分布、后验分布、似然估计[10]
- 2.3.2 Beta-Binomial共轭
- 3、LDA模型
- 3.1 pLSA跟LDA的对比:生成文档与参数估计
- 3.2 LDA生成文档过程的进一步理解
- 3.3 pLSA跟LDA的概率图对比
- 3.4 pLSA跟LDA参数估计方法的对比
- 4、LDA参数估计:Gibbs采样
- 参考资料
1、整体把握LDA
LDA由Blei, David M.、Ng, Andrew Y.、Jordan于2003年提出,是一种主题模型,它可以将文档集 中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题(分布)出来后,便可以根据主题(分布)进行主题聚类或文本分类。同时,它是一种典型的词袋模型,即一篇文档是由一组词构成,词与词之间没有先后顺序的关系。
比如假设事先给定了这几个主题:Arts、Budgets、Children、Education,然后通过学习训练,获取每个主题Topic对应的词语。
然后以一定的概率选取上述某个主题,再以一定的概率选取那个主题下的某个单词,不断的重复这两步,最终生成一篇文章。
LDA就是要干这事:根据给定的一篇文档,反推其主题分布。
通俗来说,可以假定认为人类是根据上述文档生成过程写成了各种各样的文章,现在某小撮人想让计算机利用LDA干一件事:你计算机给我推测分析网络上各篇文章分别都写了些啥主题,且各篇文章中各个主题出现的概率大小(主题分布)是啥。
在LDA模型中,一篇文档生成的方式如下:
- 从狄利克雷分布 α alpha α中取样生成文档 i 的主题分布 θ i theta_i θi
- 从主题的多项式分布 θ i theta_i θi中取样生成文档i第 j 个词的主题 z i , j z_{i,j} zi,j
- 从狄利克雷分布 β beta β中取样生成主题 z i , j z_{i,j} zi,j对应的词语分布 ϕ z i , j phi_{z_{i,j}} ϕzi,j
- 从词语的多项式分布 ϕ z i , j phi_{z_{i,j}} ϕzi,j中采样最终生成词语 w i , j w_{i,j} wi,j
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tgkYTuTU-1669296395614)(D:/2047890784UserData/Desktop/1.jpg)]
2、前提知识
一个函数:gamma函数,
四个分布:二项分布、多项分布、分布,Dirichelet分布
一个概念和一个理念:共轭先验和贝叶斯框架
两个模型 :pLSA、LDA
一个采样:Gibbs采样
2.1 gamma函数
Γ ( x + 1 ) = ∫ 0 ∞ t x e − t d t (1) Gamma(x+1) = int_0^{infty}t^xe^{-t}dttag{1} Γ(x+1)=∫0∞txe−tdt(1)
这个函数还有一个性质: Γ ( x + 1 ) = x Γ ( x ) , 所 以 Γ ( n ) = ( n − 1 ) ! Gamma(x+1) = xGamma(x),所 以quadGamma(n) = (n-1)! Γ(x+1)=xΓ(x),所以Γ(n)=(n−1)!
2.2 四个分布
2.2.1 二项分布
假设某个试验是伯努利试验,其成功概率用
p
p
p表示,那么失败的概率为
q
=
1
−
p
q=1-p
q=1−p。进行n次这样的试验,成功了
x
x
x次,则失败次数为n-x,发生这种情况的概率可用下面公式来计算:
P
(
x
)
=
C
n
x
p
x
(
1
−
p
)
n
−
x
=
n
!
x
!
(
n
−
x
)
!
P
x
(
1
−
p
)
(
n
−
x
)
(2)
P(x) = C_n^xp^x(1-p)^{n-x} = frac{n!}{x!(n-x)!}P^x(1-p)^{(n-x)}tag{2}
P(x)=Cnxpx(1−p)n−x=x!(n−x)!n!Px(1−p)(n−x)(2)
其中:
C
n
x
=
n
!
x
!
(
n
−
x
)
!
C_n^x=frac{n!}{x!(n-x)!}
Cnx=x!(n−x)!n!
2.2.2 多项分布
多项式分布是指单次试验中随机变量的取值不在是0-1,而是有多种离散值可能(1,2,3,4…k)。比如投6个面的骰子试验,N次试验结果服从K=6的多项分布。其中: ∑ i = 1 k p i = 1 , p i > 0 sumlimits_{i=1}^kp_i=1,p_i>0 i=1∑kpi=1,pi>0
多项分布的概率密度函数为,其中
∑
i
=
1
k
x
i
=
n
sumlimits_{i=1}^kx_i=n
i=1∑kxi=n
P
(
x
1
,
x
2
,
.
.
.
,
x
n
;
n
,
p
1
,
p
2
,
.
.
.
,
p
k
)
=
n
!
x
1
!
x
2
!
.
.
.
x
n
!
∏
i
=
1
n
p
i
x
i
P(x_1,x_2,...,x_n;n,p_1,p_2,...,p_k) = frac{n!}{x_1!x_2!...x_n!} prodlimits_{i=1}^np_i^{x_i}
P(x1,x2,...,xn;n,p1,p2,...,pk)=x1!x2!...xn!n!i=1∏npixi
举例: 假设萤火虫对食物的喜欢程序,我们给三种选择:花粉,蚜虫,面团。假设20%的萤火虫喜欢花粉,35%的萤火虫喜欢蚜虫,45%的萤火虫喜欢面团。我们对30只萤火虫做实验,发现8只喜欢花粉,10只喜欢蚜虫,12只喜欢面团,这件事的概率为:
p ( N 1 = 8 , N 2 = 10 , N 3 = 12 ) = 30 ! 8 ! 10 ! 12 ! 0. 2 8 0. 3 10 0.4 5 12 p(N_1=8,N_2=10,N_3=12)=frac{30!}{8!10!12!}0.2^80.3^{10}0.45^{12} p(N1=8,N2=10,N3=12)=8!10!12!30!0.280.3100.4512
2.2.3 Beta分布
1、基本介绍
beta分布可以看作一个概率的概率分布,当你不知道一个东西的具体概率是多少时,它可以给出了所有概率出现的可能性大小。
例如:现在有一个棒球运动员,我们希望能够预测他在这一赛季中的棒球击球率是多少。
2、 β beta β分布公式
给定参数
α
>
0
alpha>0
α>0和
β
>
0
beta>0
β>0,取值范围为[0,1]的随机变量 x 的概率密度函数:
β
(
x
;
α
,
β
)
=
1
B
(
α
,
β
)
x
α
−
1
(
1
−
x
)
β
−
1
(5)
beta(x;alpha,beta)=frac{1}{B(alpha,beta)}tag{5}x^{alpha-1}(1-x)^{beta-1}
β(x;α,β)=B(α,β)1xα−1(1−x)β−1(5)
其中B函数是一个标准化函数,其中 KaTeX parse error: tag works only in display equations,KaTeX parse error: tag works only in display equations
(1)公式推导
- 如果随机变量 X 服从参数为 n 和 q 的二项分布,那么它的概率由概率质量函数(对于连续随机变量,则为概率密度函数)为:
p ( x ) = C n x q x ( 1 − q ) n − x (6) p(x)=C_n^xq^x(1-q)^{n-x} tag{6} p(x)=Cnxqx(1−q)n−x(6)
-
将上面的公式表示为以 q q q为变量, x x x为常量的形式,那么就有: f ( q ) ∞ q a ( 1 − q ) b f(q) infty q^a(1-q)^b f(q)∞qa(1−q)b,其中 a a a和 b b b是常量, q ∈ ( 0 , 1 ) qin (0,1) q∈(0,1)
-
可以把这个正比因子设为 k k k,即 f ( q ) = k q a ( 1 − q ) b f(q)=kq^a(1-q)^b f(q)=kqa(1−q)b,那么满足表达式: ∫ 0 1 f ( q ) d q = ∫ 0 1 k q a ( 1 − q ) b d q = k ∫ 0 1 q a ( 1 − q ) b d q = 1 int_0^1f(q)dq= int_0^1kq^a(1-q)^bdq=kint_0^1q^a(1-q)^bdq=1 ∫01f(q)dq=∫01kqa(1−q)bdq=k∫01qa(1−q)bdq=1,求得 k = 1 ∫ 0 1 q a ( 1 − q ) b d q k=frac{1}{int_0^1q^a(1-q)^bdq} k=∫01qa(1−q)bdq1。
-
记 B ( a + 1 , b + 1 ) = ∫ 0 1 q a ( 1 − q ) b d q B(a+1,b+1)=int_0^1q^a(1-q)^bdq B(a+1,b+1)=∫01qa(1−q)bdq,即有
- f ( q ) = 1 B ( a + 1 , b + 1 ) q a ( 1 − q ) b f(q)=frac{1}{B(a+1,b+1)}q^a(1-q)^b f(q)=B(a+1,b+1)1qa(1−q)b
- B ( α , β ) = ∫ 0 1 t α − 1 ( 1 − t ) β − 1 d t B(alpha,beta)=int_0^1t^{alpha-1}(1-t)^{beta-1}dt B(α,β)=∫01tα−1(1−t)β−1dt
总结:
① β beta β分布的概率密度函数: f ( x ; α , β ) = 1 B ( a , b ) x a − 1 ( 1 − x ) b − 1 f(x;alpha,beta)=frac{1}{B(a,b)}x^{a-1}(1-x)^{b-1} f(x;α,β)=B(a,b)1xa−1(1−x)b−1
② β beta β分布: B ( x ; α , β ) = ∫ 0 1 x α − 1 ( 1 − x ) β − 1 d x B(x;alpha,beta)=int_0^1x^{alpha-1}(1-x)^{beta-1}dx B(x;α,β)=∫01xα−1(1−x)β−1dx
KaTeX parse error: tag works only in display equations
(2) β beta β函数与 Γ Gamma Γ函数之间的关系
需要的基础知识:
假设向长度为1的桌子上扔一个红球(如上图),它会落在0到1这个范围内,设这个长度值为 x ,再向桌上扔一个白球,那么这个白球落在红球左边的概率即为 x 。 若一共扔了 n 次白球,其中每一次都是相互独立的,假设落在红球左边的白球数量为 k ,那么随机变量 K 服从参数为 n 和 x 的二项分布:
P ( K = k ∣ x ) = C n k x k ( 1 − x ) n − k P(K=k|x) = C_n^kx^k(1-x)^{n-k} P(K=k∣x)=Cnkxk(1−x)n−k
那么K的分布为: P ( K = k ) = ∫ 0 1 C n k x k ( 1 − x ) n − k d x P(K=k)=int_0^1C_n^kx^k(1-x)^{n-k}dx P(K=k)=∫01Cnkxk(1−x)n−kdx换种思路:
先将这 n+1 个球都丢出来,再选择一个球作为红球,任何一个球被选中的概率均为 1n+1 ,此时红球左边有 0,1,2…n 个球的概率均为 1n+1 ,有 P ( K = k ) = ∫ 0 1 C n k x k ( 1 − x ) n − k d x = 1 n + 1 P(K=k)=int_0^1C_n^kx^k(1-x)^{n-k}dx=frac{1}{n+1} P(K=k)=∫01Cnkxk(1−x)n−kdx=n+11
故有:
∫ 0 1 x k ( 1 − x ) n − k d x = k ! ( n − k ) ! ( n + 1 ) ! (7) int_0^1x^k(1-x)^{n-k}dx=frac{k!(n-k)!}{(n+1)!}tag{7} ∫01xk(1−x)n−kdx=(n+1)!k!(n−k)!(7)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ADvrVTBP-1669296395615)(D:/2047890784UserData/Desktop/2.jpg)]
推理过程:
B
(
α
,
β
)
=
∫
0
1
t
α
−
1
(
1
−
t
)
β
−
1
d
t
B(alpha,beta)=int_0^1t^{alpha-1}(1-t)^{beta-1}dt
B(α,β)=∫01tα−1(1−t)β−1dt
- 假设:$k=alpha-1,n-k=beta-1 , 所 以 有 : ,所以有: ,所以有:n=alpha+beta-2$
B ( α , β ) = ( α − 1 ) ! ( β − 1 ) ! ( α + β − 1 ) ! (8) B(alpha,beta)=frac{(alpha-1)!(beta-1)!}{(alpha+beta-1)!}tag{8} B(α,β)=(α+β−1)!(α−1)!(β−1)!(8)
- 由公式(1)可知: Γ ( α ) = ( α − 1 ) ! , Γ ( β ) = ( β − 1 ) ! Gamma(alpha)=(alpha-1)!,Gamma(beta)=(beta-1)! Γ(α)=(α−1)!,Γ(β)=(β−1)!
B ( α , β ) = Γ ( α ) Γ ( β ) Γ ( α + β ) (9) B(alpha,beta)=frac{Gamma(alpha)Gamma(beta)}{Gamma(alpha+beta)}tag{9} B(α,β)=Γ(α+β)Γ(α)Γ(β)(9)
(3) β beta β分布的方差与期望
- E ( x ) = α α + β E(x)=frac{alpha}{alpha+beta} E(x)=α+βα
- D ( x ) = α β ( α + β + 1 ) ( α + β ) D(x)=frac{alpha beta}{(alpha+beta+1)(alpha+beta)} D(x)=(α+β+1)(α+β)αβ
(4) β beta β分布和二项分布之间的关系
进行n次伯努利试验,其出现试验成功的概率p服从一个先验概率密度分布 B e t a ( α , β ) Beta(α,β) Beta(α,β) ,试验结果出现k次试验成功,则试验成功的概率p的后验概率密度分布为 B e t a ( α + k , β + n − k ) Beta(α+k,β+n−k) Beta(α+k,β+n−k)
2.2.3 Dirichlet分布
Dirichlet 分布是 Beta 分布在高维度上的推广
Dirichlet分布是关于定义在区间[0,1]上的多个随机变量的联合概率分布,假设有d个变量,并且
μ
i
mu_i
μi,并且
∑
i
=
1
d
μ
i
=
1
sumlimits_{i=1}^dmu_i=1
i=1∑dμi=1,记
μ
=
(
μ
1
,
μ
2
,
.
.
.
,
μ
d
)
mu=(mu_1,mu_2,...,mu_d)
μ=(μ1,μ2,...,μd),每个
μ
i
mu_i
μi对应一个参数αi> 0,记
α
=
(
α
1
,
α
2
,
.
.
.
,
α
d
)
alpha=(alpha_1,alpha_2,...,alpha_d)
α=(α1,α2,...,αd),
α
^
=
∑
i
=
1
d
α
i
hat alpha=sumlimits_{i=1}^dalpha_i
α^=i=1∑dαi,那么它的概率密度函数为
p
(
μ
∣
α
)
=
D
i
r
(
μ
∣
α
)
=
Γ
(
∑
i
=
1
k
α
i
)
Γ
(
α
1
)
.
.
.
Γ
(
α
d
)
∏
i
=
1
d
μ
i
α
i
−
1
p(mu|alpha)=Dir(mu|alpha)=frac{Gamma(sumlimits_{i=1}^kalpha_i)}{Gamma(alpha_1)...Gamma(alpha_d)}prodlimits_{i=1}^dmu_i^{alpha_i-1}
p(μ∣α)=Dir(μ∣α)=Γ(α1)...Γ(αd)Γ(i=1∑kαi)i=1∏dμiαi−1
Dirichlet分布的每一个随机变量具有统计量如下:
-
E ( μ i ) = α i α ^ E(mu_i)=frac{alpha_i}{hat alpha} E(μi)=α^αi
-
D ( μ i ) = α i ( α ^ − α i ) α ^ 2 ( α ^ + 1 ) D(mu_i)=frac{alpha_i(hat alpha - alpha_i)}{{hat alpha}^2(hat alpha+1)} D(μi)=α^2(α^+1)αi(α^−αi)
-
c o v ( μ i , μ j ) = α i α j α ^ 2 ( α ^ + 1 ) cov(mu_i,mu_j)=frac{alpha_ialpha_j}{{hat alpha}^2(hat alpha+1)} cov(μi,μj)=α^2(α^+1)αiαj
由于Dirichlet分布描述的是多个定义于区间[0.1]的随机变量的概率分布,所以通常将其用作多项分布参数 μ i mu_i μi的概率分布。
Beta分布是二项式分布的共轭先验概率分布,而狄利克雷分布(Dirichlet分布)是多项式分布的共轭先验概率分布
2.3 一个概念和一个理念
2.3.1 先验分布、后验分布、似然估计[10]
这几个概念可以用“原因的可能性”和“结果的可能性”的“先后顺序”及“条件关系”来理解。下
隔壁老王要去10公里外的一个地方办事,他可以选择走路,骑自行车或者开车,并花费了一定时间到达目的地。在这个事件中,可以把交通方式(走路、骑车或开车)认为是原因,花费的时间认为是结果。
若老王花了一个小时的时间完成了10公里的距离,那么很大可能是骑车过去的,当然也有较小可能老王是个健身达人跑步过去的,或者开车过去但是堵车很严重。若老王一共用了两个小时的时间完成了10公里的距离,那么很有可能他是走路过去的。若老王只用了二十分钟,那么很有可能是开车。这种先知道结果,然后由结果估计原因的概率分布,p(交通方式|时间),就是后验概率。
老王早上起床的时候觉得精神不错,想锻炼下身体,决定跑步过去;也可能老王想做个文艺青年试试最近流行的共享单车,决定骑车过去;也可能老王想炫个富,决定开车过去。老王的选择与到达目的地的时间无关。先于结果,确定原因的概率分布,p(交通方式),就是先验概率。
老王决定步行过去,那么很大可能10公里的距离大约需要两个小时;较小可能是老王平时坚持锻炼,跑步过去用了一个小时;更小可能是老王是个猛人,40分钟就到了。老王决定骑车过去,很可能一个小时就能到;较小可能是老王那天精神不错加上单双号限行交通很通畅,40分钟就到了;还有一种较小可能是老王运气很差,连着坏了好几辆共享单车,花了一个半小时才到。老王决定开车过去,很大可能是20分钟就到了,较小可能是那天堵车很严重,磨磨唧唧花了一个小时才到。这种先确定原因,根据原因来估计结果的概率分布,p(时间|交通方式),就是似然估计。
老王去那个地方好几趟,不管是什么交通方式,得到了一组关于时间的概率分布。这种不考虑原因,只看结果的概率分布,p(时间),也有一个名词:evidence(不清楚合适的中文名是什么)。
最后,甩出著名的贝叶斯公式: p ( θ ∣ x ) = p ( x ∣ θ ) p ( θ ) p ( x ) p(theta|x)=frac{p{(x|theta)}p(theta)}{p(x)} p(θ∣x)=p(x)p(x∣θ)p(θ)
x x x : 观察得到的数据(结果)
θ theta θ: 决定数据分布的参数(原因)
p ( θ ∣ x ) p(theta|x) p(θ∣x) : posterior
p ( θ ) p(theta) p(θ) : prior
p ( x ∣ θ ) p(x|theta) p(x∣θ) : likelihood
p ( x ) p(x) p(x) : evidence
2.3.2 Beta-Binomial共轭
先验分布+数据的知识=后验分布
更一般的,对于非负实数 α , β alpha,beta α,β ,我们有如下关系: B e t a ( p ∣ α , β ) + B i n o m C o u n t ( m 1 , m 2 ) = B e t a ( p ∣ α + m 1 , β + m 2 ) Beta(p|alpha,beta)+BinomCount(m_1,m_2)=Beta(p|alpha+m_1,beta+m_2) Beta(p∣α,β)+BinomCount(m1,m2)=Beta(p∣α+m1,β+m2)
** 参数的先验分布和后验分布都是Beta分布的情况,就是Beta-Binomial共轭**
3、LDA模型
3.1 pLSA跟LDA的对比:生成文档与参数估计
在pLSA模型中,我们按照如下的步骤得到“文档-词项”的生成模型:
- 按照概率 P ( d i ) P(d_i) P(di)选择一篇文档 d i d_i di
- 选定文档 d i d_i di后,确定文章的主题分布
- 从主题分布中按照概率 P ( z k ∣ d i ) P(z_k|d_i) P(zk∣di)选择一个隐含的主题类别 z k z_k zk
- 选定 z k z_k zk后,确定主题下的词分布
- 从词分布中按照概率 P ( w j ∣ z k ) P(w_j|z_k) P(wj∣zk)选择一个词 w j w_j wj
下面,咱们对比下本文开头所述的LDA模型中一篇文档生成的方式是怎样的:
-
按照先验概率 p ( d i ) p(d_i) p(di)选择一篇文档 d i d_i di
-
从狄利克雷分布(即Dirichlet分布) α alpha α中取样生成文档 d i d_i di的主题分布 θ i theta_i θi,换言之,主题分布 θ i theta_i θi由超参数为 α alpha α的Dirichlet分布生成
-
从主题的多项式分布 θ i theta_i θi中取样生成文档 d i d_i di第 j 个词的主题 z i , j z_{i,j} zi,j
-
从狄利克雷分布(即Dirichlet分布) β beta β中取样生成主题 z i , j z_{i,j} zi,j对应的词语分布 ϕ z i , j phi_{z_{i,j}} ϕzi,j,换言之,词语分布 ϕ z i , j phi_{z_{i,j}} ϕzi,j由参数为 β beta β的Dirichlet分布生成
-
从词语的多项式分布 ϕ z i , j phi_{z_{i,j}} ϕzi,j中采样最终生成词语 w i , j w_{i,j} wi,j
从上面两个过程可以看出,LDA在PLSA的基础上,为主题分布和词分布分别加了两个Dirichlet先验。
在PLSA中,选主题和选词都是两个随机的过程,先从主题分布{教育:0.5,经济:0.3,交通:0.2}中抽取出主题:教育,然后从该主题对应的词分布{大学:0.5,老师:0.3,课程:0.2}中抽取出词:大学。
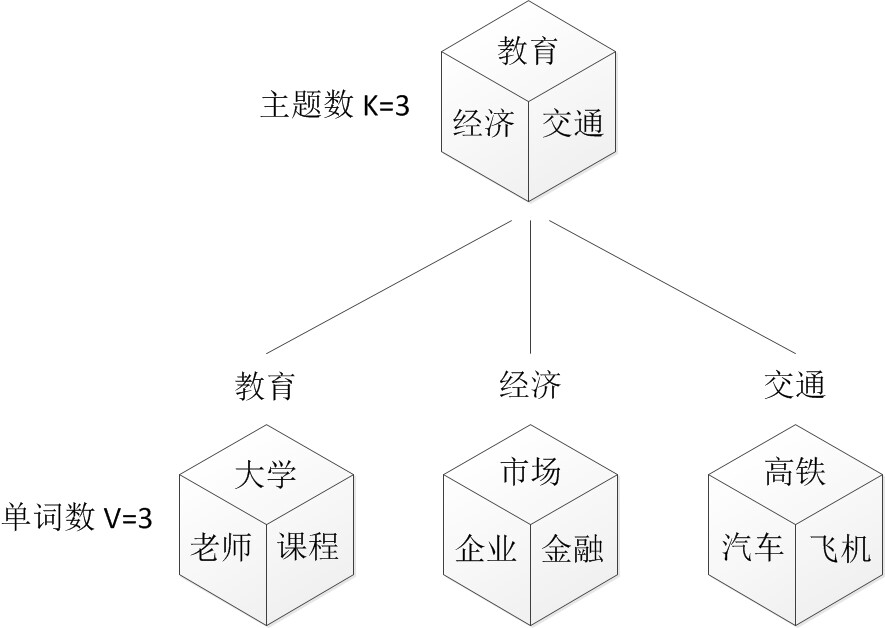
而在LDA中,选主题和选词依然都是两个随机的过程,依然可能是先从主题分布{教育:0.5,经济:0.3,交通:0.2}中抽取出主题:教育,然后再从该主题对应的词分布{大学:0.5,老师:0.3,课程:0.2}中抽取出词:大学。
那PLSA跟LDA的区别在于什么地方呢?区别就在于:
- PLSA中,主题分布和词分布是唯一确定的,能明确的指出主题分布可能就是{教育:0.5,经济:0.3,交通:0.2},词分布可能就是{大学:0.5,老师:0.3,课程:0.2}。
- 但在LDA中,主题分布和词分布不再唯一确定不变,即无法确切给出。例如主题分布可能是{教育:0.5,经济:0.3,交通:0.2},也可能是{教育:0.6,经济:0.2,交通:0.2},到底是哪个我们不再确定(即不知道),因为它是随机的可变化的。但再怎么变化,也依然服从一定的分布,即主题分布跟词分布由Dirichlet先验随机确定。
进一步,你会发现:
-
pLSA中,主题分布和词分布确定后,以一定的概率 ( P ( z k ∣ d i ) 、 P ( w j ∣ z k ) (P(z_k|d_i)、P(w_j|z_k) (P(zk∣di)、P(wj∣zk)分别选取具体的主题和词项,生成好文档。而后根据生成好的文档反推其主题分布、词分布时,最终用EM算法(极大似然估计思想)求解出了两个未知但固定的参数的值: ϕ k , j phi_{k,j} ϕk,j
- 文档d产生主题z的概率,主题z产生单词w的概率都是两个固定的值
- 举个文档d产生主题z的例子。给定一篇文档d,主题分布是一定的,比如{ P(zi|d), i = 1,2,3 }可能就是{0.4,0.5,0.1},表示z1、z2、z3,这3个主题被文档d选中的概率都是个固定的值:P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,如下图所示
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cul6rTk0-1669296395615)(D:/2047890784UserData/Desktop/4.jpg)]
- 文档d产生主题z的概率,主题z产生单词w的概率都是两个固定的值
-
但在贝叶斯框架下的LDA中,我们不再认为主题分布(各个主题在文档中出现的概率分布)和词分布(各个词语在某个主题下出现的概率分布)是唯一确定的(而是随机变量),而是有很多种可能。但一篇文档总得对应一个主题分布和一个词分布吧,怎么办呢?LDA为它们弄了两个Dirichlet先验参数,这个Dirichlet先验为某篇文档随机抽取出某个主题分布和词分布。
- 文档d产生主题z(准确的说,其实是Dirichlet先验为文档d生成主题分布Θ,然后根据主题分布Θ产生主题z)的概率,主题z产生单词w的概率都不再是某两个确定的值,而是随机变量。
- 还是再次举下文档d具体产生主题z的例子。给定一篇文档d,现在有多个主题z1、z2、z3,它们的主题分布{ P(zi|d), i = 1,2,3 }可能是{0.4,0.5,0.1},也可能是{0.2,0.2,0.6},即这些主题被d选中的概率都不再认为是确定的值,可能是P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,也有可能是P(z1|d) = 0.2、P(z2|d) = 0.2、P(z3|d) = 0.6等等,而主题分布到底是哪个取值集合我们不确定(为什么?这就是贝叶斯派的核心思想,把未知参数当作是随机变量,不再认为是某一个确定的值),但其先验分布是dirichlet 分布,所以可以从无穷多个主题分布中按照dirichlet 先验随机抽取出某个主题分布出来。如下图所示:
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vKf6K56M-1669296395615)(D:/2047890784UserData/Desktop/5.jpg)]
- 换言之,LDA在pLSA的基础上给这两参数 P ( z k ∣ d i ) 、 P ( w j ∣ z k ) P(z_k|d_i)、P(w_j|z_k) P(zk∣di)、P(wj∣zk)加了两个先验分布的参数(贝叶斯化):一个主题分布的先验分布Dirichlet分布 α alpha α,和一个词语分布的先验分布Dirichlet分布 β beta β
所以,pLSA跟LDA的本质区别就在于它们去估计未知参数所采用的思想不同,前者用的是频率派思想,后者用的是贝叶斯派思想。
好比,我去一朋友家:- 按照频率派的思想,我估计他在家的概率是1/2,不在家的概率也是1/2,是个定值。而按照贝叶斯派的思想,他在家不在家的概率不再认为是个定值1/2,而是随机变量。比如按照我们的经验(比如当天周末),猜测他在家的概率是0.6,但这个0.6不是说就是完全确定的,也有可能是0.7。如此,贝叶斯派没法确切给出参数的确定值(0.3,0.4,0.6,0.7,0.8,0.9都有可能),但至少明白在哪个范围或哪些取值(0.6,0.7,0.8,0.9)更有可能,哪个范围或哪些取值(0.3,0.4) 不太可能。进一步,贝叶斯估计中,参数的多个估计值服从一定的先验分布,而后根据实践获得的数据(例如周末不断跑他家),不断修正之前的参数估计,从先验分布慢慢过渡到后验分布。
3.2 LDA生成文档过程的进一步理解
上面说,LDA中,主题分布 —— 比如{ P(zi), i =1,2,3 }等于{0.4,0.5,0.1}或{0.2,0.2,0.6} —— 是由dirichlet先验给定的,不是根据文档产生的。所以,LDA生成文档的过程中,先从dirichlet先验中“随机”抽取出主题分布,然后从主题分布中“随机”抽取出主题,最后从确定后的主题对应的词分布中“随机”抽取出词。
那么,dirichlet先验到底是如何“随机”抽取主题分布的呢?
事实上,从dirichlet分布中随机抽取主题分布,这个过程不是完全随机的。为了说清楚这个问题,咱们得回顾下dirichlet分布。事实上,如果我们取3个事件的话,可以建立一个三维坐标系,类似xyz三维坐标系,这里,我们把3个坐标轴弄为p1、p2、p3,如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4ocMROCd-1669296395616)(D:/2047890784UserData/Desktop/6.jpg)]
在这个三维坐标轴所划分的空间里,每一个坐标点(p1,p2,p3)就对应着一个主题分布,且某一个点(p1,p2,p3)的大小表示3个主题z1、z2、z3出现的概率大小(因为各个主题出现的概率和为1,所以p1+p2+p3 = 1,且p1、p2、p3这3个点最大取值为1)。比如(p1,p2,p3) = (0.4,0.5,0.1)便对应着主题分布{ P(zi), i =1,2,3 } = {0.4,0.5,0.1}。
可以想象到,空间里有很多这样的点(p1,p2,p3),意味着有很多的主题分布可供选择,那dirichlet分布如何选择主题分布呢?把上面的斜三角形放倒,映射到底面的平面上,便得到如下所示的一些彩图(3个彩图中,每一个点对应一个主题分布,高度代表某个主题分布被dirichlet分布选中的概率,且选不同的,dirichlet 分布会偏向不同的主题分布):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eWoiN0vp-1669296395616)(D:/2047890784UserData/Desktop/7.jpg)]
我们来看上图中左边这个图,高度就是代表dirichlet分布选取某个坐标点(p1,p2,p3)(这个点就是一个主题分布)的概率大小。如下图所示,平面投影三角形上的三个顶点上的点:A=(0.9,0.05,0.05)、B=(0.05,0.9,0.05)、C=(0.05,0.05,0.9)各自对应的主题分布被dirichlet分布选中的概率值很大,而平面三角形内部的两个点:D、E对应的主题分布被dirichlet分布选中的概率值很小。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CcKrdBBB-1669296395616)(D:/2047890784UserData/Desktop/8.jpg)]
所以虽然说dirichlet分布是随机选取任意一个主题分布的,但依然存在着P(A) = P(B) = P© >> P(D) = P(E),即dirichlet分布还是“偏爱”某些主题分布的。
此外,就算说“随机”选主题也是根据主题分布来“随机”选取,这里的随机不是完全随机的意思,而是根据各个主题出现的概率值大小来抽取。比如当dirichlet先验为文档d生成的主题分布{ P(zi), i =1,2,3 }是{0.4,0.5,0.1}时,那么主题z2在文档d中出现的概率便是0.5。所以,从主题分布中抽取主题,这个过程也不是完全随机的,而是按照各个主题出现的概率值大小进行抽取。
3.3 pLSA跟LDA的概率图对比
接下来,对比下LDA跟pLSA的概率模型图模型,左图是pLSA,右图是LDA(右图不太规范,z跟w都得是小写, 其中,阴影圆圈表示可观测的变量,非阴影圆圈表示隐变量,箭头表示两变量间的条件依赖性conditional dependency,方框表示重复抽样,方框右下角的数字代表重复抽样的次数):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MQrsK7FZ-1669296395616)(D:/2047890784UserData/Desktop/9.jpg)]
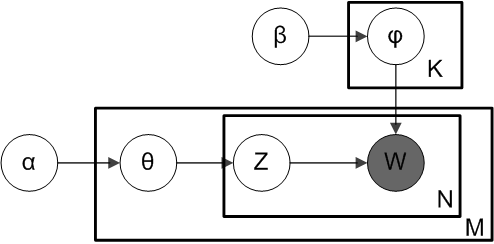
对应到上面右图的LDA,只有W / w是观察到的变量,其他都是隐变量或者参数,其中,Φ表示词分布,Θ表示主题分布,[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oPQkt0db-1669296395617)(https://gitee.com/empty-city-code/repository/raw/master/Img/20141117160438989)] 是主题分布Θ的先验分布(即Dirichlet 分布)的参数,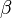
所以,对于一篇文档d中的每一个单词,LDA根据先验知识 α alpha α确定某篇文档的主题分布 θ theta θ,然后从该文档所对应的多项分布(主题分布) θ theta θ中抽取一个主题z,接着根据先验知识 β beta β确定当前主题的词语分布 ϕ phi ϕ,然后从主题z所对应的多项分布(词分布) ϕ phi ϕ中抽取一个单词w。然后将这个过程重复N次,就产生了文档d。
换言之:
- 假定语料库中共有M篇文章,每篇文章下的Topic的主题分布是一个从参数为的Dirichlet先验分布中采样得到的Multinomial分布,每个Topic下的词分布是一个从参数为的Dirichlet先验分布中采样得到的Multinomial分布。
- 对于某篇文章中的第n个词,首先从该文章中出现的每个主题的Multinomial分布(主题分布)中选择或采样一个主题,然后再在这个主题对应的词的Multinomial分布(词分布)中选择或采样一个词。不断重复这个随机生成过程,直到M篇文章全部生成完成。
综上,M 篇文档会对应于 M 个独立的 Dirichlet-Multinomial 共轭结构,K 个 topic 会对应于 K 个独立的 Dirichlet-Multinomial 共轭结构。
- 其中,
α
alpha
α→θ→z 表示生成文档中的所有词对应的主题,显然
α
alpha
α→θ 对应的是Dirichlet 分布,θ→z 对应的是 Multinomial 分布,所以整体是一个 Dirichlet-Multinomial 共轭结构,如下图所示:
- 类似的,
β
beta
β→φ→w,容易看出, 此时β→φ对应的是 Dirichlet 分布, φ→w 对应的是 Multinomial 分布, 所以整体也是一个Dirichlet-Multinomial 共轭结构,如下图所示:
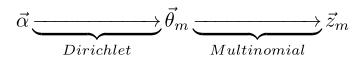
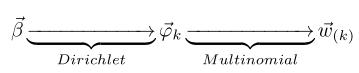
3.4 pLSA跟LDA参数估计方法的对比
上面对比了pLSA跟LDA生成文档的不同过程,下面,咱们反过来,假定文档已经产生,反推其主题分布。那么,它们估计未知参数所采用的方法又有什么不同呢?
- 在pLSA中,我们使用EM算法去估计“主题-词项”矩阵 ϕ phi ϕ(由 P ( w j ∣ z k ) P(w_j|z_k) P(wj∣zk)转换得到)和“文档-主题”矩阵Θ(由 P ( z k ∣ d i ) P(z_k|d_i) P(zk∣di)转换得到)这两个参数,而且这两参数都是个固定的值,只是未知,使用的思想其实就是极大似然估计MLE。
- 而在LDA中,估计Φ、Θ这两未知参数可以用变分(Variational inference)-EM算法,也可以用gibbs采样,前者的思想是最大后验估计MAP(MAP与MLE类似,都把未知参数当作固定的值),后者的思想是贝叶斯估计。贝叶斯估计是对MAP的扩展,但它与MAP有着本质的不同,即贝叶斯估计把待估计的参数看作是服从某种先验分布的随机变量。
4、LDA参数估计:Gibbs采样
类似于pLSA,LDA的原始论文中是用的变分-EM算法估计未知参数,后来发现另一种估计LDA未知参数的方法更好,这种方法就是:Gibbs Sampling,有时叫Gibbs采样或Gibbs抽样,都一个意思。Gibbs抽样是马尔可夫链蒙特卡尔理论(MCMC)中用来获取一系列近似等于指定多维概率分布(比如2个或者多个随机变量的联合概率分布)观察样本的算法。
给定一个文档集合,w是可以观察到的已知变量,
α
alpha
α和
β
beta
β是根据经验给定的先验参数,其他的变量z,θ和φ都是未知的隐含变量,需要根据观察到的变量来学习估计的。根据LDA的图模型,可以写出所有变量的联合分布:
p
(
w
m
→
,
z
m
→
,
ϑ
m
→
,
Φ
∣
α
→
,
β
→
=
∏
n
=
1
N
m
p
(
w
m
,
n
∣
φ
z
m
,
n
→
)
)
p
(
z
m
,
n
∣
φ
m
→
)
p
(
Φ
∣
β
→
)
p(overrightarrow{w_m},overrightarrow{z_m},overrightarrow{vartheta_m},varPhi|overrightarrow{alpha},overrightarrow{beta}=prodlimits_{n=1}^{N_m}p(w_{m,n}|overrightarrow{varphi_{z_{m,n}}}))p(z_{m,n}|overrightarrow{varphi_m})p(varPhi|overrightarrow{beta})
p(wm,zm,ϑm,Φ∣α,β=n=1∏Nmp(wm,n∣φzm,n))p(zm,n∣φm)p(Φ∣β)
因为
α
alpha
α产生主题分布θ,主题分布θ确定具体主题,且
β
beta
β产生词分布
φ
varphi
φ、词分布φ确定具体词,所以上述式子等价于下述式子所表达的联合概率分布
p
(
w
→
,
z
→
)
p(overrightarrow{w},overrightarrow{z})
p(w,z)
p
(
w
→
,
z
→
∣
α
→
,
β
→
)
=
p
(
w
→
∣
z
→
,
β
→
)
p
(
z
→
∣
α
→
)
p(overrightarrow{w},overrightarrow{z}|overrightarrow{alpha},overrightarrow{beta})=p(overrightarrow{w}|overrightarrow{z},overrightarrow{beta})p(overrightarrow{z}|overrightarrow{alpha})
p(w,z∣α,β)=p(w∣z,β)p(z∣α)
其中,第一项因子
p
(
w
→
∣
z
→
,
β
→
)
p(overrightarrow{w}|overrightarrow{z},overrightarrow{beta})
p(w∣z,β)表示的是根据确定的主题
z
→
overrightarrow{z}
z和词分布的先验分布参数
β
→
overrightarrow{beta}
β采样词的过程,第二项因子
p
(
z
→
∣
α
→
)
p(overrightarrow{z}|overrightarrow{alpha})
p(z∣α)是根据主题分布的先验分布参数
α
alpha
α采样主题的过程,这两项因子是需要计算的两个未知参数。
第一个因子
p
(
w
→
∣
z
→
,
β
→
)
p(overrightarrow{w}|overrightarrow{z},overrightarrow{beta})
p(w∣z,β),可以根据确定的主题
z
→
overrightarrow{z}
z和从先验分布
β
beta
β取样得到的词分布Φ产生:
p
(
w
→
∣
z
→
,
Φ
)
=
∏
i
=
1
W
p
(
w
i
∣
z
i
)
=
∏
i
=
1
W
φ
z
i
,
w
i
p(overrightarrow{w}|overrightarrow{z},varPhi)=prod_{i=1}^Wp(w_i|z_i)=prod_{i=1}^Wvarphi_{z_i,w_i}
p(w∣z,Φ)=i=1∏Wp(wi∣zi)=i=1∏Wφzi,wi
由于样本中的词服从参数为主题 KaTeX parse error: Undefined control sequence: z at position 1: ̲z̲_i的独立多项分布,这意味着可以把上面对词的乘积分解成分别对主题和对词的两层乘积:
p
(
w
→
∣
z
→
,
Φ
)
=
∏
k
=
1
K
∏
{
i
:
z
i
−
k
}
p
(
w
i
=
t
∣
z
i
=
k
)
=
∏
k
=
1
K
∏
t
=
1
V
φ
k
,
t
n
k
(
t
)
p(overrightarrow{w}|overrightarrow{z},varPhi)=prodlimits_{k=1}^Kprodlimits_{{i:z_i-k}}p(w_i=t|z_i=k)=prodlimits_{k=1}^Kprodlimits_{t=1}^Vvarphi_{k,t}^{n_k^{(t)}}
p(w∣z,Φ)=k=1∏K{i:zi−k}∏p(wi=t∣zi=k)=k=1∏Kt=1∏Vφk,tnk(t)
其中,
n
k
(
t
)
n_k^{(t)}
nk(t)是词 t 在主题 k 中出现的次数。
回到第一个因子上来。目标分布
p
(
w
→
∣
z
→
,
β
→
)
p(overrightarrow{w}|overrightarrow{z},overrightarrow{beta})
p(w∣z,β)需要对词分布Φ积分:
Δ
(
α
⃗
)
=
∫
∏
k
=
1
V
p
k
α
k
−
1
d
p
⃗
Delta(vec{alpha})=int prod_{k=1}^{V} p_{k}^{alpha_{k}-1} d vec{p}
Δ(α)=∫k=1∏Vpkαk−1dp
可得:
p
(
w
⃗
∣
z
⃗
,
β
⃗
)
=
∫
p
(
w
⃗
∣
z
⃗
,
Φ
)
p
(
Φ
∣
β
⃗
)
d
Φ
=
∫
∏
z
=
1
K
1
Δ
(
β
⃗
)
∏
t
−
1
V
φ
z
,
t
n
z
(
t
)
+
β
t
−
1
d
φ
⃗
z
=
∏
z
−
1
K
Δ
(
n
⃗
z
+
β
⃗
)
Δ
(
β
⃗
)
,
n
⃗
z
=
{
n
z
(
t
)
}
t
−
1
V
begin{aligned} p(vec{w} mid vec{z}, vec{beta}) &=int p(vec{w} mid vec{z}, Phi) p(Phi mid vec{beta}) mathrm{d} Phi \ &=int prod_{z=1}^{K} frac{1}{Delta(vec{beta})} prod_{t-1}^{V} varphi_{z, t}^{n_{z}^{(t)}+beta_{t}-1} mathrm{~d} vec{varphi}_{z} \ &=prod_{z-1}^{K} frac{Deltaleft(vec{n}_{z}+vec{beta}right)}{Delta(vec{beta})}, quad vec{n}_{z}=left{n_{z}^{(t)}right}_{t-1}^{V} end{aligned}
p(w∣z,β)=∫p(w∣z,Φ)p(Φ∣β)dΦ=∫z=1∏KΔ(β)1t−1∏Vφz,tnz(t)+βt−1 dφz=z−1∏KΔ(β)Δ(nz+β),nz={nz(t)}t−1V
现在开始求第二个因子
p
(
z
→
∣
α
→
)
p(overrightarrow{z}|overrightarrow{alpha})
p(z∣α),先写出条件分布,然后分解成两部分的乘积:
p
(
z
⃗
∣
Θ
)
=
∏
i
−
1
W
p
(
z
i
∣
d
i
)
=
∏
m
−
1
M
∏
k
−
1
K
p
(
z
i
=
k
∣
d
i
=
m
)
=
∏
m
−
1
M
∏
k
−
1
K
θ
m
,
k
n
m
(
k
)
p(vec{z} mid Theta)=prod_{i-1}^{W} pleft(z_{i} mid d_{i}right)=prod_{m-1}^{M} prod_{k-1}^{K} pleft(z_{i}=k mid d_{i}=mright)=prod_{m-1}^{M} prod_{k-1}^{K} theta_{m, k}^{n_{m}^{(k)}}
p(z∣Θ)=i−1∏Wp(zi∣di)=m−1∏Mk−1∏Kp(zi=k∣di=m)=m−1∏Mk−1∏Kθm,knm(k)
其中,
d
i
d_i
di 表示的单词 i 所属的文档,
n
m
(
k
)
n_m^{(k)}
nm(k)是主题 k 在文章 m 中出现的次数。
对主题分布Θ积分可得:
p
(
z
⃗
∣
α
⃗
)
=
∫
p
(
z
⃗
∣
Θ
)
p
(
Θ
∣
α
⃗
)
d
Θ
=
∫
∏
m
−
1
M
1
Δ
(
α
⃗
)
∏
k
=
1
K
ϑ
m
,
k
n
m
(
k
)
+
α
k
−
1
d
ϑ
⃗
m
=
∏
m
−
1
M
Δ
(
n
⃗
m
+
α
⃗
)
Δ
(
α
⃗
)
,
n
⃗
m
=
{
n
m
(
k
)
}
k
−
1
K
begin{aligned} p(vec{z} mid vec{alpha}) &=int p(vec{z} mid Theta) p(Theta mid vec{alpha}) mathrm{d} Theta \ &=int prod_{m-1}^{M} frac{1}{Delta(vec{alpha})} prod_{k=1}^{K} vartheta_{m, k}^{n_{m}^{(k)}+alpha_{k}-1} mathrm{~d} vec{vartheta}_{m} \ &=prod_{m-1}^{M} frac{Deltaleft(vec{n}_{m}+vec{alpha}right)}{Delta(vec{alpha})}, quad vec{n}_{m}=left{n_{m}^{(k)}right}_{k-1}^{K} end{aligned}
p(z∣α)=∫p(z∣Θ)p(Θ∣α)dΘ=∫m−1∏MΔ(α)1k=1∏Kϑm,knm(k)+αk−1 dϑm=m−1∏MΔ(α)Δ(nm+α),nm={nm(k)}k−1K
综合第一个因子和第二个因子的结果,得到
p
(
w
→
,
z
→
)
p(overrightarrow{w},overrightarrow{z})
p(w,z)的联合分布结果为:
p
(
z
⃗
,
w
⃗
∣
α
⃗
,
β
⃗
)
=
∏
z
=
1
K
Δ
(
n
⃗
z
+
β
⃗
)
Δ
(
β
⃗
)
⋅
∏
m
−
1
M
Δ
(
n
⃗
m
+
α
⃗
)
Δ
(
α
⃗
)
p(vec{z}, vec{w} mid vec{alpha}, vec{beta})=prod_{z=1}^{K} frac{Deltaleft(vec{n}_{z}+vec{beta}right)}{Delta(vec{beta})} cdot prod_{m-1}^{M} frac{Deltaleft(vec{n}_{m}+vec{alpha}right)}{Delta(vec{alpha})}
p(z,w∣α,β)=∏z=1KΔ(β)Δ(nz+β)⋅∏m−1MΔ(α)Δ(nm+α)
最终求解的Dirichlet 分布期望为:(计算过程忽略不写)
φ k , t = n k ( t ) + β t ∑ t − 1 V n k ( t ) + β t ϑ m , k = n m ( k ) + α k ∑ k − 1 K n m ( k ) + α k begin{aligned} varphi_{k, t} &=frac{n_{k}^{(t)}+beta_{t}}{sum_{t-1}^{V} n_{k}^{(t)}+beta_{t}} \ vartheta_{m, k} &=frac{n_{m}^{(k)}+alpha_{k}}{sum_{k-1}^{K} n_{m}^{(k)}+alpha_{k}} end{aligned} φk,tϑm,k=∑t−1Vnk(t)+βtnk(t)+βt=∑k−1Knm(k)+αknm(k)+αk
Gibbs Sampling 便在这K 条路径中进行采样,如下图所示:

参考资料
[1]深入理解Beta分布:从定义到公式推导
[2] beta 分布
[3] Beta分布深入理解
[4]主题模型(LDA)(一)–通俗理解与简单应用
[5] 主题模型(LDA)(二)-公式推导
[6] 通俗理解LDA主题模型
[7] Dirichlet distribution狄利克雷分布
[8] LDA主题建模学习笔记
[9] LDA主题建模的python实现
[10 ]先验分布、后验分布、似然估计
[11]通俗理解LDA主题模型
)
[7] Dirichlet distribution狄利克雷分布
[8] LDA主题建模学习笔记
[9] LDA主题建模的python实现
[10 ]先验分布、后验分布、似然估计
[11]通俗理解LDA主题模型
最后
以上就是专注冷风最近收集整理的关于狄利克雷分布主题模型LDA狄利克雷分布主题模型LDA的全部内容,更多相关狄利克雷分布主题模型LDA狄利克雷分布主题模型LDA内容请搜索靠谱客的其他文章。


![[Python笔记] 用LDA(隐含狄利克雷分布)抽取主题分布+用户特征生成问题背景预处理训练ldalda模型的评价以稀疏矩阵输出结果结果](https://www.shuijiaxian.com/files_image/reation/bcimg20.png)





发表评论 取消回复