Paper:《NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion,女娲:用于神经视觉世界创造的视觉》翻译与解读
导读:微软亚洲研究院联手北京大学,2021年11月,在 GitHub 开源了一个多模态预训练模型:NÜWA(女娲),可实现文本/草图转图像、图像补全、文字/草图转视频等任务,功能异常强大。
把文字、图像、视频分别看做一维、二维、三维数据,分别对应3个以它们为输入的编码器。另外预训练好一个处理图像与视频数据的3D解码器。两者配合就获得了以上各种能力。
目录
《NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion》翻译与解读
Abstract
1. Introduction
2. Related Works
2.1. Visual AutoRegressive Models
2.2. Visual Sparse SelfAttention
3. Method
3.1. 3D Data Representation
3.2. 3D Nearby SelfAttention
3.3. 3D EncoderDecoder
3.4. Training Objective
4. Experiments
4.1. Implementation Details
4.2. Comparison with stateoftheart
4.3. Ablation Study
5. Conclusion
《NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion》翻译与解读
| 链接 | https://arxiv.org/abs/2111.12417 |
| github | GitHub - microsoft/NUWA: A unified 3D Transformer Pipeline for visual synthesis |
| 作者 | Chenfei Wu, Jian Liang, Lei Ji, Fan Yang, Yuejian Fang, Daxin Jiang, Nan Duan |
| 发布日期 | 2021年11月24日 |
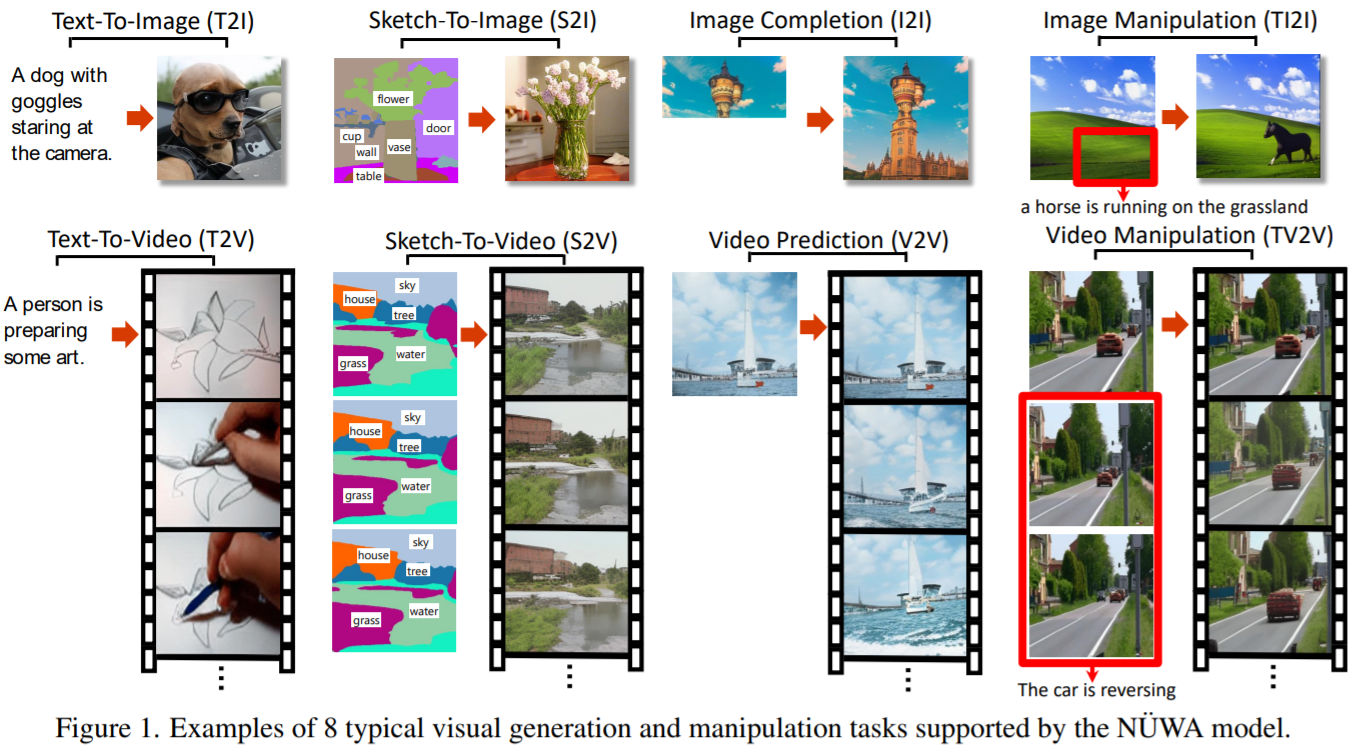
| Figure 1. Examples of 8 typical visual generation and manipulation tasks supported by the NUWA model. | 图1所示,由NUWA模型支持的8个典型的可视化生成和操作任务的例子。 |
Abstract
| This paper presents a unified multimodal pre-trained model called N ¨UWA that can generate new or manipulate existing visual data (i.e., images and videos) for various visual synthesis tasks. To cover lan-guage, image, and video at the same time for different scenarios, a 3D transformer encoder-decoder frame-work is designed, which can not only deal with videos as 3D data but also adapt to texts and images as 1D and 2D data, respectively. A 3D Nearby Attention (3DNA) mechanism is also proposed to consider the nature of the visual data and reduce the computational complexity. We evaluate N ¨UWA on 8 downstream tasks. Compared to several strong baselines, N ¨UWA achieves state-of-the-art results on text-to-image gen-eration, text-to-video generation, video prediction, etc. Furthermore, it also shows surprisingly good zero-shot capabilities on text-guided image and video manipula-tion tasks. Project repo is https://github.com/microsoft/NUWA. | 本文提出了一个统一的多模态预训练模型,称为NÜWA,它可以为各种视觉合成任务生成新的或操作现有的视觉数据(即图像和视频)。为了同时覆盖不同场景的语言、图像和视频,设计了一种3D转换器编码器-解码器框架,该框架既能将视频处理为3D数据,又能将文本和图像分别处理为1D和2D数据。此外,还提出了一种3D邻近注意(3DNA)机制,以考虑视觉数据的性质,降低计算复杂度。我们在8个下游任务上评估NÜWA。与几个强基线相比,NÜWA在文本到图像生成、文本到视频生成、视频预测等方面取得了最先进的结果。此外,它还显示出惊人的好零镜头 文本引导图像和视频操作任务的能力。项目的仓库是 https://github.com/microsoft/NUWA。 |
1. Introduction
| Nowadays, the Web is becoming more visual than ever before, as images and videos have become the new informa-tion carriers and have been used in many practical applica-tions. With this background, visual synthesis is becoming a more and more popular research topic, which aims to build models that can generate new or manipulate existing visual data (i.e., images and videos) for various visual scenarios. Auto-regressive models [33, 39, 41, 45] play an impor-tant role in visual synthesis tasks, due to their explicit den-sity modeling and stable training advantages compared with GANs [4, 30, 37, 47]. Earlier visual auto-regressive models, such as PixelCNN [39], PixelRNN [41], Image Transformer [28], iGPT [5], and Video Transformer [44], performed vi-sual synthesis in a “pixel-by-pixel” manner. However, due to their high computational cost on high-dimensional visual data, such methods can be applied to low-resolution images or videos only and are hard to scale up. Recently, with the arise of VQ-VAE [40] as a discrete visual tokenization approach, efficient and large-scale pretraining can be applied to visual synthesis tasks for images (e.g., DALL-E [33] and CogView [9]) and videos (e.g., GO-DIVA [45]). Although achieving great success, such solu-tions still have limitations – they treat images and videos separately and focus on generating either of them. This lim-its the models to benefit from both image and video data. | 如今,网络正变得比以往任何时候都更加可视化,图像和视频已经成为新的信息载体,并在许多实际应用中得到了应用。在此背景下,视觉合成成为一个越来越受欢迎的研究课题,其目标是为各种视觉场景构建能够生成新的或操作已有视觉数据(如图像和视频)的模型。 自回归模型[33,39,41,45]在视觉合成任务中发挥着重要作用,这是因为自回归模型具有明显的密度建模和相对于GANs的稳定训练优势[4,30,37,47]。早期的视觉自回归模型,如PixelCNN[39]、PixelRNN[41]、Image Transformer[28]、iGPT[5]和Video Transformer[44],都以“逐像素”的方式进行视觉合成。但由于这种方法对高维视觉数据的计算成本较高,只能应用于低分辨率的图像或视频,且难以按比例放大。 近年来,随着VQ-VAE[40]作为一种离散的视觉标记化方法的出现,高效、大规模的预训练可以应用于图像(如DALL-E[33]、CogView[9])和视频(如GO-DIVA[45])的视觉合成任务。尽管取得了巨大的成功,但这样的解决方案仍然有局限性——它们分别对待图像和视频,并专注于生成图像和视频。这就限制了从图像和视频数据中获益的模型。 |
| In this paper, we present N ¨UWA, a unified multimodal pre-trained model that aims to support visual synthesis tasks for both images and videos, and conduct experiments on 8 downstream visual synthesis, as shown in Fig. 1. The main contributions of this work are three-fold: We propose N ¨UWA, a general 3D transformer encoder-decoder framework, which covers language, image, and video at the same time for different visual synthesis tasks. It consists of an adaptive encoder that takes either text or visual sketch as input, and a decoder shared by 8 visual synthesis tasks. We propose a 3D Nearby Attention (3DNA) mecha-nism in the framework to consider the locality charac-teristic for both spatial and temporal axes. 3DNA not only reduces computational complexity but also im-proves the visual quality of the generated results. Compared to several strong baselines, N ¨UWA achieves state-of-the-art results on text-to-image generation, text-to-video generation, video prediction, etc. Fur-thermore, N ¨UWA shows surprisingly good zero-shot capabilities not only on text-guided image manipula-tion, but also text-guided video manipulation. | 本文提出了一种统一的多模态预训练模型NÜWA,旨在同时支持图像和视频的视觉合成任务,并对8个下游视觉合成进行了实验,如图1所示。本工作的主要贡献有三方面: 我们提出了NÜWA,一个通用的3D变压器编码器-解码器框架,它涵盖了语言、图像和视频,同时用于不同的视觉合成任务。它由1个以文本或视觉草图为输入的自适应编码器和一个由8个视觉合成任务共享的解码器组成。 我们在该框架中提出了一种三维邻近注意(3DNA)机制,以考虑空间轴和时间轴的局地性特征。3DNA不仅降低了计算复杂度,而且提高了生成结果的视觉质量。 与几个强基线相比,NÜWA在文本到图像生成、文本到视频生成、视频预测等方面取得了最先进的结果。此外,NÜWA不仅在文本引导的图像处理上,而且在文本引导的视频处理上显示了令人惊讶的良好的零镜头能力。 |
2. Related Works
2.1. Visual AutoRegressive Models
| The method proposed in this paper follows the line of visual synthesis research based on auto-regressive models. Earlier visual auto-regressive models [5, 28, 39, 41, 44] per-formed visual synthesis in a “pixel-by-pixel” manner. How-ever, due to the high computational cost when modeling high-dimensional data, such methods can be applied to low-resolution images or videos only, and are hard to scale up. Recently, VQ-VAE-based [40] visual auto-regressive models were proposed for visual synthesis tasks. By con-verting images into discrete visual tokens, such methods can conduct efficient and large-scale pre-training for text-to-image generation (e.g., DALL-E [33] and CogView [9]), text-to-video generation (e.g., GODIVA [45]), and video prediction (e.g., LVT [31] and VideoGPT [48]), with higher resolution of generated images or videos. However, none of these models was trained by images and videos together. But it is intuitive that these tasks can benefit from both types of visual data. | 本文提出的方法遵循了基于自回归模型的视觉综合研究思路。早期的视觉自回归模型[5,28,39,41,44]以“逐像素”的方式执行形成的视觉合成。然而,由于建模高维数据时计算成本较高,这种方法只能应用于低分辨率的图像或视频,且难以按比例放大。 最近,基于VQ-VAE-的[40]视觉自回归模型被提出用于视觉合成任务。这些方法通过将图像转换成离散的视觉标记,可以对文本-图像生成(如dale - e[33]和CogView[9])、文本-视频生成(如GODIVA[45])和视频预测(如LVT[31]和视频- pt[48])进行高效、大规模的预训练,生成的图像或视频分辨率更高。然而,这些模型都不是由图像和视频一起训练的。但这些任务可以从两种类型的可视数据中受益,这是很直观的。 |
| Compared to these works, N ¨UWA is a unified auto-regressive visual synthesis model that is pre-trained by the visual data covering both images and videos and can sup-port various downstream tasks. We also verify the effec-tiveness of different pretraining tasks in Sec. 4.3. Besides, VQ-GAN [11] instead of VQ-VAE is used in N ¨UWA for vi-sual tokenization, which, based on our experiment, can lead to better generation quality. | 与这些作品相比,NÜWA是一个统一的自回归视觉合成模型,它是由包括图像和视频的视觉数据预先训练的,可以支持各种下游任务。我们也在第4.3节中验证了不同训练前任务的有效性。此外,VQ-GAN[11]代替VQ-VAE在NÜWA中用于视觉标记化,根据我们的实验,可以导致更好的生成质量。 |
2.2. Visual Sparse SelfAttention
| How to deal with the quadratic complexity issue brought by self-attention is another challenge, especially for tasks like high-resolution image synthesis or video synthesis. Similar to NLP, sparse attention mechanisms have been explored to alleviate this issue for visual synthesis. [31, 44] split the visual data into different parts (or blocks) and then performed block-wise sparse attention for the synthesis tasks. However, such methods dealt with different blocks separately and did not model their relationships. [15,33,45] proposed to use axial-wise sparse attention in visual synthe-sis tasks, which conducts sparse attention along the axes of visual data representations. This mechanism makes training very efficient and is friendly to large-scale pre-trained mod-els like DALL-E [33], CogView [9], and GODIVA [45]. However, the quality of generated visual contents could be harmed due to the limited contexts used in self-attention.[6, 28, 32] proposed to use local-wise sparse attention in vi-sual synthesis tasks, which allows the models to see more contexts. But these works were for images only. Compared to these works, N ¨UWA proposes a 3D nearby attention that extends the local-wise sparse attention to cover both images to videos. We also verify that local-wise sparse attention is superior to axial-wise sparse attention for visual generation in Sec. 4.3. | 如何处理由自我注意带来的二次复杂度问题是另一个挑战,特别是对于高分辨率图像合成或视频合成等任务。 类似于NLP,稀疏注意机制已经被探索来缓解视觉合成的这个问题。[31,44]将视觉数据分割成不同的部分(或块),然后对合成任务进行逐块稀疏注意。然而,这些方法分别处理不同的块,并没有对它们的关系建模。[15,33,45]提出了在视觉合成任务中使用轴向稀疏注意,即沿着视觉数据表示的轴方向进行稀疏注意。这种机制使得训练非常高效,并且对大规模的预训练模型如DALL-E[33]、CogView[9]、GODIVA[45]都很友好。然而,生成的视觉内容的质量可能会受到损害,因为有限的上下文用于自我注意。[6,28,32]提出在视觉合成任务中使用局部稀疏注意,这使得模型能够看到更多的上下文。但这些作品只是图像。 与这些作品相比,NÜWA提出了一种3D附近注意,它将局部稀疏的注意扩展到覆盖两幅图像到视频。在第4.3节中,我们还验证了局部稀疏注意优于轴向稀疏注意。 |
3. Method
3.1. 3D Data Representation
| To cover all texts, images, and videos or their sketches, we view all of them as tokens and define a unified 3D no-tation X ∈ Rh×w×s×d, where h and w denote the number of tokens in the spatial axis (height and width respectively), s denotes the number of tokens in the temporal axis, and d is the dimension of each token. In the following, we in-troduce how we get this unified representation for different modalities. Texts are naturally discrete, and following Transformer [42], we use a lower-cased byte pair encoding (BPE) to tok-enize and embed them into R1×1×s×d. We use placeholder 1 because the text has no spatial dimension. Images are naturally continuous pixels. Input a raw im-age I ∈ RH×W×C with height H, width W and channel C, VQ-VAE [40] trains a learnable codebook to build a bridge between raw continuous pixels and discrete tokens, as denoted in Eq. (1)∼(2): | 涵盖所有文字、图片和视频或草图,我们认为所有这些标记和定义一个统一的3 d no-tation X∈Rh w×××s d h和w表示令牌的数量在空间轴(分别高度和宽度),s表示令牌的数量在时间轴,和d是每个令牌的维数。在下文中,我们将介绍如何得到不同模态的统一表示。 文本自然是离散的,在Transformer[42]之后,我们使用小写的字节对编码(BPE)来标记enize并将其嵌入到R1×1×s×d中。我们使用占位符1是因为文本没有空间维度。 图像自然是连续的像素。输入原始图像I∈RH×W×C,高度H,宽度W,通道C, VQ-VAE[40]训练一个可学习码本,在原始连续像素和离散令牌之间建立一座桥梁,如式(1)~(2)所示: |
|
| |
| Videos can be viewed as a temporal extension of images, and recent works like VideoGPT [48] and VideoGen [51] extend convolutions in the VQ-VAE encoder from 2D to 3D and train a video-specific representation. However, this fails to share a common codebook for both images and videos. In this paper, we show that simply using 2D VQ-GAN to encode each frame of a video can also generate temporal consistency videos and at the same time benefit from both image and video data. The resulting representation is denoted as Rh×w×s×d, where s denotes the number of frames. For image sketches, we consider them as images with special channels. An image segmentation matrix RH×W with each value representing the class of a pixel can be viewed in a one-hot manner RH×W×C where C is the num-ber of segmentation classes. By training an additional VQ-GAN for image sketch, we finally get the embedded image representation Rh×w×1×d. Similarly, for video sketches, the representation is Rh×w×s×d. | 视频可以被看作是图像的时间扩展,最近的作品如VideoGPT[48]和VideoGen[51]将VQ-VAE编码器中的卷积从2D扩展到3D,并训练特定于视频的表示。然而,这不能为图像和视频共享一个共同的代码本。在本文中,我们证明了简单地使用2D VQ-GAN编码视频的每一帧也可以生成时间一致性的视频,同时受益于图像和视频数据。结果表示为Rh×w×s×d,其中s表示帧数。 对于图像速写,我们认为是具有特殊通道的图像。图像分割矩阵RH×W,每个值代表像素的类,可以用一热方式RH×W×C查看,其中C为分割类的数量。通过训练一个附加的VQ-GAN图像草图,我们最终得到了嵌入的图像表示Rh×w×1×d。类似地,对于视频草图,表示为Rh×w×s×d。 |

3.2. 3D Nearby SelfAttention
| In this section, we define a unified 3D Nearby Self-Attention (3DNA) module based on the previous 3D data representations, supporting both self-attention and cross-attention. We first give the definition of 3DNA in Eq. (6), and introduce detailed implementation in Eq. (7)∼(11): | 在本节中,我们基于之前的3D数据表示定义了一个统一的3D附近自我注意(3DNA)模块,支持自我注意和交叉注意。我们首先在式(6)中给出3DNA的定义,并在式(7)~(11)中引入详细的实现: |
|
|


3.3. 3D EncoderDecoder
| In this section, we introduce 3D encode-decoder built based on 3DNA. To generate a target Y ∈ Rh×w×s×dout under the condition of C ∈ Rh×w×s×din , the positional encoding for both Y and C are updated by three different learnable vocabularies considering height, width, and tem-poral axis, respectively in Eq. (12)∼(13):
Then, the condition C is fed into an encoder with a stack of L 3DNA layers to model the self-attention interactions, with the lth layer denoted in Eq. (14):
Similarly, the decoder is also a stack of L 3DNA layers. The decoder calculates both self-attention of generated re-sults and cross-attention between generated results and con-ditions. The lth layer is denoted in Eq. (15).
| 在本节中,我们将介绍基于3DNA构建的三维码译码器。为了在C∈Rh×w×s×din的条件下生成目标Y∈Rh×w×s×dout, Y和C的位置编码分别由Eq.(12) ~(13)中考虑到高度、宽度和时间轴的三个不同可学词汇来更新: 然后,将条件C输入一个包含l3dna层堆栈的编码器,对自我注意交互进行建模,第lth层如式(14)所示: 类似地,解码器也是一个l3dna层的堆栈。解码器计算生成结果的自注意和生成结果与条件之间的交叉注意。第l层如式(15)所示。 |
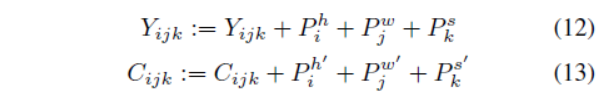

3.4. Training Objective
| We train our model on three tasks, Text-to-Image (T2I), Video Prediction (V2V) and Text-to-Video (T2V). The training objective for the three tasks are cross-entropys de-noted as three parts in Eq. (16), respectively:
| 我们以文本到图像(T2I)、视频预测(V2V)和文本到视频(T2V)三个任务来训练我们的模型。这三个任务的训练目标在式(16)中分别被标记为三个部分的交叉熵: |
| For T2I and T2V tasks, Ctext denotes text conditions. For the V2V task, since there is no text input, we instead get a constant 3D representation c of the special word “None”. θ denotes the model parameters. | 对于T2I和T2V任务,Ctext表示文本条件。对于V2V任务,因为没有文本输入,所以我们得到一个特定单词“None”的固定3D表示c。θ为模型参数。 |
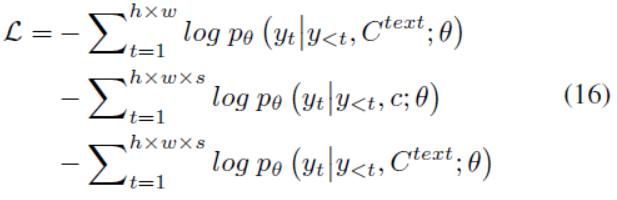
4. Experiments
4.1. Implementation Details
| Based on Sec. 3.4 we first pre-train N ¨UWA on three datasets: Conceptual Captions [22] for text-to-image (T2I) generation, which includes 2.9M text-image pairs, Mo-ments in Time [26] for video prediction (V2V), which in-cludes 727K videos, and VATEX dataset [43] for text-to-video (T2V) generation, which includes 241K text-video pairs. In the following, we first introduce implementation details in Sec. 4.1 and then compare N ¨UWA with state-of-the-art models in Sec. 4.2, and finally conduct ablation stud-ies in Sec. 4.3 to study the impacts of different parts. | 基于第3.4节,我们首先在三个数据集上对NÜWA进行预训练:用于文本-图像(T2I)生成的概念性字幕[22],包括2.9M文本-图像对;用于视频预测的mots in Time[26],包括727K个视频;用于文本-视频(T2V)生成的VATEX数据集[43],包括241K个文本-视频对。在接下来的章节4.1中,我们首先介绍了实施细节,然后将NÜWA与章节4.2中最先进的模型进行比较,最后在章节4.3中进行消融研究,研究不同部位的影响。 |
| In Sec. 3.1, we set the sizes of 3D representations for text, image, and video as follows. For text, the size of 3D representation is 1 × 1 × 77 × 1280. For image, the size of 3D representation is 21 × 21 × 1 × 1280. For video, the size of 3D representation is 21 × 21 × 10 × 1280, where we sample 10 frames from a video with 2.5 fps. Although the default visual resolution is 336 × 336, we pre-train different resolutions for a fair comparison with existing models. For the VQ-GAN model used for both images and videos, the size of grid feature E(I) in Eq. (1) is 441 × 256, and the size of the codebook B is 12, 288. Different sparse extents are used for different modalities in Sec. 3.2. For text, we set (ew, eh, es) = (1, 1, ∞), where ∞ denotes that the full text is always used in attention. For image and image sketches, (ew, eh, es) = (3, 3, 1). For video and video sketches, (ew, eh, es) = (3, 3, 3). We pre-train on 64 A100 GPUs for two weeks with the layer L in Eq. (14) set to 24, an Adam [17] optimizer with a learning rate of 1e-3, a batch size of 128, and warm-up 5%of a total of 50M steps. The final pre-trained model has a total number of 870M parameters. | 在3.1节中,我们设置了文本、图像和视频的3D表示的大小,如下所示。对于文本,3D表示的大小为1 × 1 × 77 × 1280。图像的三维表示尺寸为21 × 21 × 1 × 1280。对于视频,3D表示的尺寸是21 × 21 × 10 × 1280,我们以2.5帧/秒的速度从视频中选取10帧。虽然默认的视觉分辨率是336x336,但我们预先训练不同的分辨率,以便与现有模型进行公平的比较。对于图像和视频使用的VQ-GAN模型,式(1)中网格特征E(I)的大小为441 × 256,码本B的大小为12,288。 在第3.2节中,对于不同的模式使用了不同的稀疏范围。对于文本,我们设置(ew, eh, es) =(1,1,∞),∞表示全文总是用于注意。对于图像和图像草图,(ew, eh, es) =(3,3,1)。对于视频和视频草图,(ew, eh, es) =(3,3,3)。 我们在64个A100 gpu上进行了两周的预训练,将式(14)中的L层设置为24,学习速率为1e-3的Adam[17]优化器,批处理大小为128,热身总数为50M步的5%。最终的预训练模型共有870M个参数。 |


4.2. Comparison with stateoftheart
| Text-to-Image (T2I) fine-tuning: We compare N ¨UWA on the MSCOCO [22] dataset quantitatively in Tab. 1 and qualitatively in Fig. 3. Following DALL-E [33], we use k blurred FID score (FID-k) and Inception Score (IS) [35] to evaluate the quality and variety respectively, and following GODIVA [45], we use CLIPSIM metric, which incor-porates a CLIP [29] model to calculate the semantic simi-larity between input text and the generated image. For a fair comparison, all the models use the resolution of 256 × 256. We generate 60 images for each text and select the best one by CLIP [29]. In Tab. 1, N ¨UWA significantly outperforms CogView [9] with FID-0 of 12.9 and CLIPSIM of 0.3429. Although XMC-GAN [50] reports a significant FID score of 9.3, we find N ¨UWA generates more realistic images com-pared with the exact same samples in XMC-GAN’s paper (see Fig. 3). Especially in the last example, the boy’s face is clear and the balloons are correctly generated. | 文本-图像(T2I)微调:我们对MSCOCO[22]数据集上的NÜWA进行了定量比较(见表1)和定性比较(见图3)。在dal - e[33]之后,我们分别使用k个模糊FID评分(FID-k)和Inception评分(IS)[35]来评估质量和多样性,在GODIVA[45]之后,我们使用CLIPSIM度量,该度量包含一个CLIP[29]模型来计算输入文本和生成图像之间的语义相似度。为了便于比较,所有的模型都使用了256 × 256的分辨率。我们为每个文本生成60个图像,并通过CLIP[29]选择最佳的一个。在表1中,NÜWA显著优于CogView [9], fidi -0为12.9,CLIPSIM为0.3429。虽然XMC-GAN[50]报告了显著的FID评分9.3,但我们发现NÜWA生成的图像比XMC-GAN论文中完全相同的样本(见图3)更真实。特别是在最后一个例子中,男孩的脸清晰,气球也正确生成。 |
| Text-to-Video (T2V) fine-tuning: We compare N ¨UWA on the Kinetics [16] dataset quantitatively in Tab. 2 and qualitatively in Fig. 4. Following TFGAN [2], we evaluate the visual quality on FID-img and FID-vid metrics and se-mantic consistency on the accuracy of the label of generated video. As shown in Tab. 2, N ¨UWA achieves the best perfor-mance on all the above metrics. In Fig. 4, we also show the strong zero-shot ability for generating unseen text, such as “playing golf at swimming pool” or “running on the sea”. Video Prediction (V2V) fine-tuning: We compare N ¨UWA on BAIR Robot Pushing [10] dataset quantitatively in Tab. 3. Cond. denotes the number of frames given to predict future frames. For a fair comparison, all the mod-els use 64×64 resolutions. Although given only one frame as condition (Cond.), N ¨UWA still significantly pushes the state-of-the-art FVD [38] score from 94±2 to 86.9. | 文字-视频(T2V)微调:我们在Fig. 2和Fig. 4中定量地比较了Kinetics[16]数据集上的NÜWA。在TFGAN[2]之后,我们评估了fidi -img和fidi -vid度量的视觉质量,以及生成的视频标签准确性的语义一致性。如表2所示,NÜWA在所有上述指标上都获得了最佳性能。在图4中,我们还展示了生成不可见文本的强大的零拍能力,例如“在游泳池打高尔夫球”或“在海上奔跑”。 视频预测(V2V)微调:我们在表3中对BAIR机器人Pushing[10]数据集上的NÜWA进行了定量比较。气孔导度。表示用来预测未来帧的帧数。为了便于比较,所有型号都使用64×64的分辨率。虽然只给了一帧作为条件(Cond.), NÜWA仍然显著地将最先进的FVD[38]分数从94±2提高到86.9。 |
| Sketch-to-Image (S2I) fine-tuning: We compare N ¨UWA on MSCOCO stuff [22] qualitatively in Fig. 5. N ¨UWA generates realistic buses of great varieties compared with Taming-Transformers [11] and SPADE [27]. Even the reflection of the bus window is clearly visible. Image Completion (I2I) zero-shot evaluation: We compare N ¨UWA in a zero-shot manner qualitatively in Fig. 6. Given the top half of the tower, compared with Taming Transformers [11], N ¨UWA shows richer imagina-tion of what could be for the lower half of the tower, includ-ing buildings, lakes, flowers, grass, trees, mountains, etc. | 草图到图像(S2I)微调:我们在图5中定性地比较了MSCOCO材料[22]上的NÜWA。与驯服变形金刚[11]和铁锹[27]相比,UWA生产了各种各样的现实公交车。甚至公交车车窗的反光都清晰可见。 图像补全(I2I)零拍评价:我们在图6中用零拍的方式定性地比较了NÜWA。与《驯服的变形金刚》[11]相比,从塔顶的上半部分来看,东华大学对塔底的下半部分表现出了丰富的想象,包括建筑、湖泊、花草、树木、山脉等。 |
| Text-Guided Image Manipulation (TI2I) zero-shot evaluation: We compare N ¨UWA in a zero-shot manner qualitatively in Fig. 7. Compared with Paint By Word [3], N ¨UWA shows strong manipulation ability, generating high-quality text-consistent results while not changing other parts of the image. For example, in the third row, the blue firetruck generated by N ¨UWA is more realistic, while the behind buildings show no change. This is benefited from real-world visual patterns learned by multi-task pre-training on various visual tasks. Another advantage is the inference speed of N ¨UWA, practically 50 seconds to generate an im-age, while Paint By Words requires additional training dur-ing inference, and takes about 300 seconds to converge. Sketch-to-Video (S2V) fine-tuning and Text-Guided Video Manipulation (TV2V) zero-shot evaluation: As far as we know, open-domain S2V and TV2V are tasks first proposed in this paper. Since there is no comparison, we instead arrange them in Ablation Study in Section 4.3. | 文本引导图像处理(TI2I)零拍评价:我们在图7中以零拍的方式定性地比较了NÜWA。与Paint By Word[3]相比,NÜWA具有很强的操作能力,可以在不改变图像其他部分的情况下,生成高质量的文本一致性结果。例如,在第三排,NÜWA生成的蓝色消防车更真实,而后面的建筑没有变化。这得益于真实世界的视觉模式,这些模式是通过对各种视觉任务进行多任务预训练而习得的。另一个优点是NÜWA的推理速度,实际上生成图像需要50秒,而Paint By Words在推理过程中需要额外的训练,并且需要大约300秒的时间来收敛。 su -to-Video (S2V)微调和Text-Guided Video Manipulation (TV2V)零拍评价:据我们所知,开放域S2V和TV2V是本文首先提出的任务。由于没有比较,我们将其安排在4.3节的消融研究中。 |
| More detailed comparisons, samples, including human evaluations, are provided in the appendix. | 更详细的比较,样本,包括人类评估,在附录中提供。 |



| Figure 5. Quantitative comparison with state-of-the-art models for Sketch-to-Image (S2I) task on MSCOCO stuff dataset. Figure 6. Qualitative comparison with the state-of-the-art model for Image Completion (I2I) task in a zero-shot manner. Figure 7. Quantitative comparison with state-of-the-art models for text-guided image manipulation (TI2I) in a zero-shot manner. Figure 8. Reconstruction samples of VQ-GAN and VQ-GAN-Seg. | 图5。在MSCOCO材料数据集上进行S2I任务模型的定量比较。 图6。与目前最先进的图像补全(I2I)任务模型进行了定性比较。 图7。与最先进的文本引导图像处理(TI2I)模型在零镜头方式的定量比较。 图8。VQ-GAN和VQ-GAN- seg的重建样本。 |
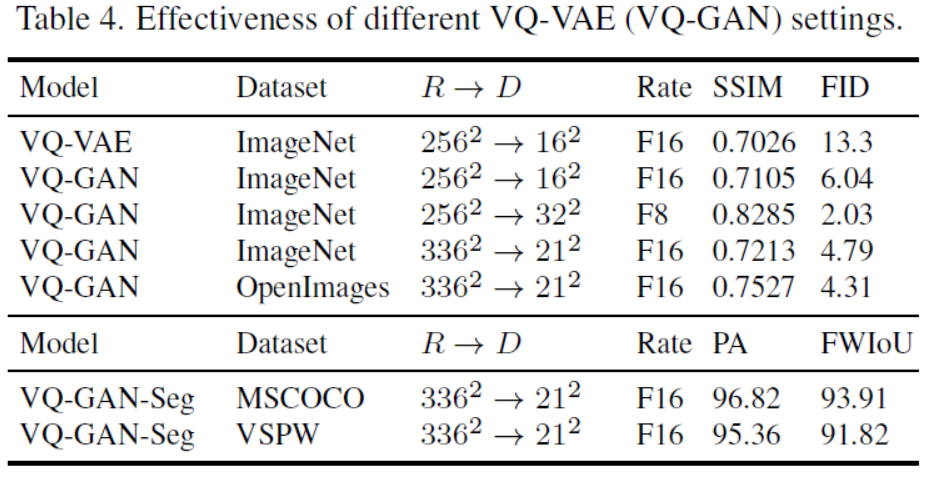
| Table 4. Effectiveness of different VQ-VAE (VQ-GAN) settings. Table 5. Effectiveness of multi-task pre-training for Text-to-Video (T2V) generation task on MSRVTT dataset. Table 6. Effectiveness of 3D nearby attention for Sketch-to-Video (S2V) task on VSPW dataset. | 表4。VQ-VAE (VQ-GAN)设置的有效性。 表5所示。MSRVTT数据集上T2V生成任务的多任务预训练效果 表6所示。VSPW数据集上S2V (Sketch-to-Video)任务三维邻近注意的有效性 |


4.3. Ablation Study
| The above part of Tab. 4 shows the effectiveness of dif-ferent VQ-VAE (VQ-GAN) settings. We experiment on Im-ageNet [34] and OpenImages [19]. R denotes raw resolu-tion, D denotes the number of discrete tokens. The com√pression rate is√denoted as F x, where x is the quotient of R divided by D. Comparing the first two rows in Tab. 4,VQ-GAN shows significantly better Fr´echet Inception Dis-tance (FID) [14] and Structural Similarity Matrix (SSIM) scores than VQ-VAE. Comparing Row 2-3, we find that the number of discrete tokens is the key factor leading to higher visual quality instead of compress rate. Although Row 2 and Row 4 have the same compression rate F16, they have different FID scores of 6.04 and 4.79. So what matters is not only how much we compress the original image, but also how many discrete tokens are used for representing an im-age. This is in line with cognitive logic, it’s too ambiguous to represent human faces with just one token. And practi-cally, we find that 162 discrete tokens usually lead to poor performance, especially for human faces, and 322 tokens show the best performance. However, more discrete tokens mean more computing, especially for videos. We finally use a trade-off version for our pre-training: 212 tokens. By training on the Open Images dataset, we further improve the FID score of the 212 version from 4.79 to 4.31. | 4884/5000 表4上半部分显示了不同VQ-VAE (VQ-GAN)设置的效果。我们在Im-ageNet[34]和OpenImages[19]上进行了实验。R表示原始分辨率,D表示离散令牌的数量。对比表4的前两行,VQ-GAN的Fr´echet Inception distance (FID)[14]和Structural Similarity Matrix (SSIM)得分明显好于VQ-VAE。比较2-3行,我们发现离散符号的数量是导致更高视觉质量的关键因素,而不是压缩速率。虽然Row 2和Row 4有相同的压缩率F16,但是它们的FID评分不同,分别为6.04和4.79。因此,重要的不仅是我们压缩了原始图像的多少,还包括有多少离散符号被用于表示一个图像。这符合认知逻辑,用一个符号来表示人脸太模糊了。实际上,我们发现162个离散符号通常会导致较差的性能,尤其是对于人脸,而322个符号表现最好。然而,更多的离散标记意味着更多的计算,特别是对于视频。我们最终为我们的预培训使用了一个权衡版本:212个令牌。通过在Open Images数据集上进行训练,我们进一步将212版本的FID分数从4.79提高到4.31。 |
| The below part of Tab. 4 shows the performance of VQ-GAN for sketches. VQ-GAN-Seg on MSCOCO [22] is trained for Sketch-to-Image (S2I) task and VQ-GAN-Seg on VSPW [24] is trained for Sketch-to-Video (S2V) task. All the above backbone shows good performance in Pixel Accuracy (PA) and Frequency Weighted Intersection over Union (FWIoU), which shows a good quality of 3D sketch representation used in our model. Fig. 8 also shows some reconstructed samples of 336×336 images and sketches. Tab. 5 shows the effectiveness of multi-task pre-training for the Text-to-Video (T2V) generation task. We study on a challenging dataset, MSR-VTT [46], with natural descrip-tions and real-world videos. Compared with training only on a single T2V task (Row 1), training on both T2V and T2I (Row 2) improves the CLIPSIM from 0.2314 to 0.2379. This is because T2I helps to build a connection between text and image, and thus helpful for the semantic consis-tency of the T2V task. In contrast, training on both T2V and V2V (Row 3) improves the FVD score from 52.98 to 51.81. This is because V2V helps to learn a common un-conditional video pattern, and is thus helpful for the visual quality of the T2V task. As a default setting of N ¨UWA, training on all three tasks achieves the best performance. | 下表4显示了VQ-GAN对草图的性能。MSCOCO[22]上的VQ-GAN-Seg训练用于sketchto - image (S2I)任务,VSPW[24]上的VQ-GAN-Seg训练用于sketchto - video (S2V)任务。该模型具有良好的像素精度(PA)和频率加权交叉联合(FWIoU)性能,表明该模型具有良好的三维草图表示质量。图8还展示了一些336×336图像和草图的重构样本。 表5显示了多任务预训练对于T2V (Text-to-Video)生成任务的有效性。我们研究一个具有挑战性的数据集,MSR-VTT[46],具有自然的描述和真实世界的视频。与只进行单个T2V任务训练(第1行)相比,同时进行T2V和T2I训练(第2行)将CLIPSIM从0.2314提高到0.2379。这是因为T2I有助于在文本和图像之间建立联系,从而有助于T2V任务的语义一致性。相比之下,T2V和V2V(第三行)的训练将FVD得分从52.98提高到51.81。这是因为V2V有助于学习一种常见的非条件视频模式,因此有助于提高T2V任务的视觉质量。作为NÜWA的默认设置,在所有三个任务上进行训练可以获得最佳性能。 |
| Tab. 7 shows the effectiveness of 3D nearby attention for the Sketch-to-Video (S2V) task on the VSPW [24] dataset. We study on the S2V task because both the encoder and de-coder of this task are fed with 3D video data. To evaluate the semantic consistency for S2V, we propose a new met-ric called Detected PA, which uses a semantic segmentation model [49] to segment each frame of the generated video and then calculate the pixel accuracy between the generated segments and input video sketch. The default N ¨UWA set-ting in the last row, with both nearby encoder and nearby de-coder, achieves the best FID-vid and Detected PA. The per-formance drops if either encoder or decoder is replaced by full attention, showing that focusing on nearby conditions and nearby generated results is better than simply consid-ering all the information. We compare nearby-sparse and axial-sparse in two-folds. Firstly��� , the���computational com-plexity of nearby-sparse is O (hws) ehewes and axis-sparse attention is O ((hws) (h + w + s)). For generating long videos (larger s), nearby-sparse will be more compu-tational efficient. Secondly, nearby-sparse has better per-formance than axis-sparse in visual generation task, which is because nearby-sparse attends to “nearby” locations con-taining interactions between both spatial and temporal axes, while axis-sparse handles different axis separately and only consider interactions on the same axis. | 表7显示了在VSPW[24]数据集上sketchto - video (S2V)任务中三维附近注意的有效性。我们之所以研究S2V任务,是因为该任务的编码器和解码器都提供了三维视频数据。为了评估S2V的语义一致性,我们提出了一种新的度量方法,称为检测PA,它使用一个语义分割模型[49]对生成的视频进行每帧分割,然后计算生成的视频片段与输入视频草图之间的像素精度。默认的NÜWA设置在最后一行,与附近的编码器和译码器,实现最佳的FID-vid和检测PA。如果编码器或解码器被完全关注所取代,性能会下降,这表明关注附近的条件和附近生成的结果比简单地考虑所有的信息要好。我们在两方面比较了近稀疏和轴稀疏。首先���,附近稀疏的���computational复杂度为O (hws) ehewes,轴稀疏的注意复杂度为O ((hws) (h + w + s))。对于生成长视频(更大的视频),near -sparse将具有更高的计算效率。其次,在视觉生成任务中,邻稀疏比轴稀疏有更好的表现,这是因为邻稀疏处理的是包含时空轴交互的“邻近”位置,而轴稀疏处理的是不同轴,只考虑同一轴上的交互。 |
| Fig. 9 shows a new task proposed in this paper, which we call “Text-Guided Video Manipulation (TV2V)”. TV2V aims to change the future of a video starting from a selected frame guided by text. All samples start to change the future of the video from the second frame. The first row shows the original video frames, where a diver is swimming in the water. After feeding “The diver is swimming to the surface” into N ¨UWA’s encoder and providing the first video frame, N ¨UWA successfully generates a video with the diver swim-ming to the surface in the second row. The third row shows another successful sample that lets the diver swim to the bottom. What if we want the diver flying to the sky? The fourth row shows that N ¨UWA can make it as well, where the diver is flying upward, like a rocket. | 图9显示了本文提出的一个新任务,我们称之为“文本引导视频操作(TV2V)”。TV2V的目标是改变未来的视频,从文本引导的选定帧开始。所有的样本从第二帧开始改变视频的未来。第一行显示的是原始的视频画面,一个潜水员正在水里游泳。在将“潜水员正在游向水面”输入到NÜWA的编码器并提供第一个视频帧后,NÜWA成功地在第二排生成了一段潜水员游向水面的视频。第三行是另一个成功的样本,让潜水员游到水底。如果我们想让潜水员飞上天呢?第四行表示NÜWA也能做到这一点,潜水员向上飞,像火箭一样。 |
5. Conclusion
| In this paper, we present N ¨UWA as a unified pre-trained model that can generate new or manipulate existing images and videos for 8 visual synthesis tasks. Several contribu-tions are made here, including (1) a general 3D encoder-decoder framework covering texts, images, and videos at the same time; (2) a nearby-sparse attention mechanism that considers the nearby characteristic of both spatial and tem-poral axes; (3) comprehensive experiments on 8 synthesis tasks. This is our first step towards building an AI platform to enable visual world creation and help content creators. | 在本文中,我们提出NÜWA作为一个统一的预训练模型,可以为8个视觉合成任务生成新的或操作现有的图像和视频。本文给出了一些贡献,包括 (1)一个通用的3D编码器-解码器框架,同时涵盖文本、图像和视频; (2)考虑空间轴和时间轴的邻近性特征的邻近-稀疏注意机制; (3) 8个综合任务的综合实验。 这是我们构建AI平台的第一步,让我们能够创造视觉世界并帮助内容创造者。 |
最后
以上就是简单哈密瓜最近收集整理的关于Paper:《NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion,女娲:用于神经视觉世界创造的视觉》翻译与解读《NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion》翻译与解读的全部内容,更多相关Paper:《NÜWA:内容请搜索靠谱客的其他文章。








发表评论 取消回复