∏∏∏首先在文章的开头先慰问一下我床头的申婷婷,希望它能够好好看一看我自己写的博客,能让他未来有一个好的归宿。
Begin~~~~ 开始前放一个我喜欢的小姐姐,养养眼再开始学习

什么是Hadoop?
Hadoop是一个能够对大量数据进行分布式处理的软件框架。以一种可靠、高效、可伸缩的方式进行数据处理。主要包括三部分内容:Hdfs,MapReduce,Yarn
Hadoop在广义上指一个生态圈,泛指大数据技术相关的开源组件或产品,如HBase,Hive,Spark,Zookeeper,Kafka,flume…

====================================================
在面试题开始前我们先对hadoop中的组成部分做一个简单的了解
Hdfs
作用:hadoop中的存储系统,用于存储文件
MapRdeuce
是hadoop的核心,计算系统
yarn
作用:资源调度器
以下为hadoop启动后有哪些进程?
NameNode 名称节点
管理文件系统的命名空间,记录每个文件中各个块所在的数据节点信息
作用:1.管理DataNode,维护所有的文件和目录。
2.记录每个文件所在的数据节点信息,但并不永久保存。
DataNode 数据节点
作用:1.存储并检索数据块,受客户端或namenode调度
2.定期向namenode发送所存储的块的信息
ResourceManger 资源管理器
作用:1.管理集群上资源(HDFS存储的数据)的使用
NodeManger 节点管理器
作用:运行在集群中所有节点上能够启动和监控容器
能简单介绍Hadoop1.0,2.0,3.0的区别吗?
其实我们现在用的是2.7.2版本,还是比较落后的,为了对hadoop的历史做一个更全的认识,就去了解了一下以往的版本和现在的差异:
Hadoop1.0由分布式存储系统HDFS和分布式计算框架MapReduce组成,其中HDFS由一个NameNode和多个DateNode组成,MapReduce由一个JobTracker和多个TaskTracker组成。在Hadoop1.0中容易导致单点故障,拓展性差,性能低,支持编程模型单一的问题。
Hadoop2.0即为克服Hadoop1.0中的不足,提出了以下关键特性:yarn是大佬
Yarn:它是Hadoop2.0引入的一个全新的通用资源管理系统,完全代替了Hadoop1.0中的JobTracker。在MRv1 中的 JobTracker 资源管理和作业跟踪的功能被抽象为 ResourceManager 和 AppMaster 两个组件。Yarn 还支持多种应用程序和框架,提供统一的资源调度和管理功能
NameNode 单点故障得以解决:Hadoop2.2.0 同时解决了 NameNode 单点故障问题和内存受限问题,并提供 NFS,QJM 和 Zookeeper 三种可选的共享存储系统
HDFS 快照:指 HDFS(或子系统)在某一时刻的只读镜像,该只读镜像对于防止数据误删、丢失等是非常重要的。例如,管理员可定时为重要文件或目录做快照,当发生了数据误删或者丢失的现象时,管理员可以将这个数据快照作为恢复数据的依据
支持Windows 操作系统:Hadoop 2.2.0 版本的一个重大改进就是开始支持 Windows 操作系统
Append:新版本的 Hadoop 引入了对文件的追加操作
同时,新版本的Hadoop对于HDFS做了两个非常重要的增强,分别是支持异构的存储层次和通过数据节点为存储在HDFS中的数据提供内存缓冲功能
相比于hadoop2.0的话,3.0增加的东西我都没见过也没用过,不过也先放上吧,玩意以后有用呢,有想了解的小伙伴可以专项的去了解。在这里我就不多赘述了……
HDFS可擦除编码:这项技术使HDFS在不降低可靠性的前提下节省了很大一部分存储空间
多NameNode支持:在Hadoop3.0中,新增了对多NameNode的支持。当然,处于Active状态的NameNode实例必须只有一个。也就是说,从Hadoop3.0开始,在同一个集群中,支持一个 ActiveNameNode 和 多个 StandbyNameNode 的部署方式。
MR Native Task优化
Yarn基于cgroup 的内存和磁盘 I/O 隔离
Yarn container resizing
介绍一下HDFS读写流程
这个问题我还是比较基础的,就用自己的话稍微的做了以下总结,但是最重要的还是能把图放心中,一图在手,面试无有,文字的话毕竟还是会忘记
读流程
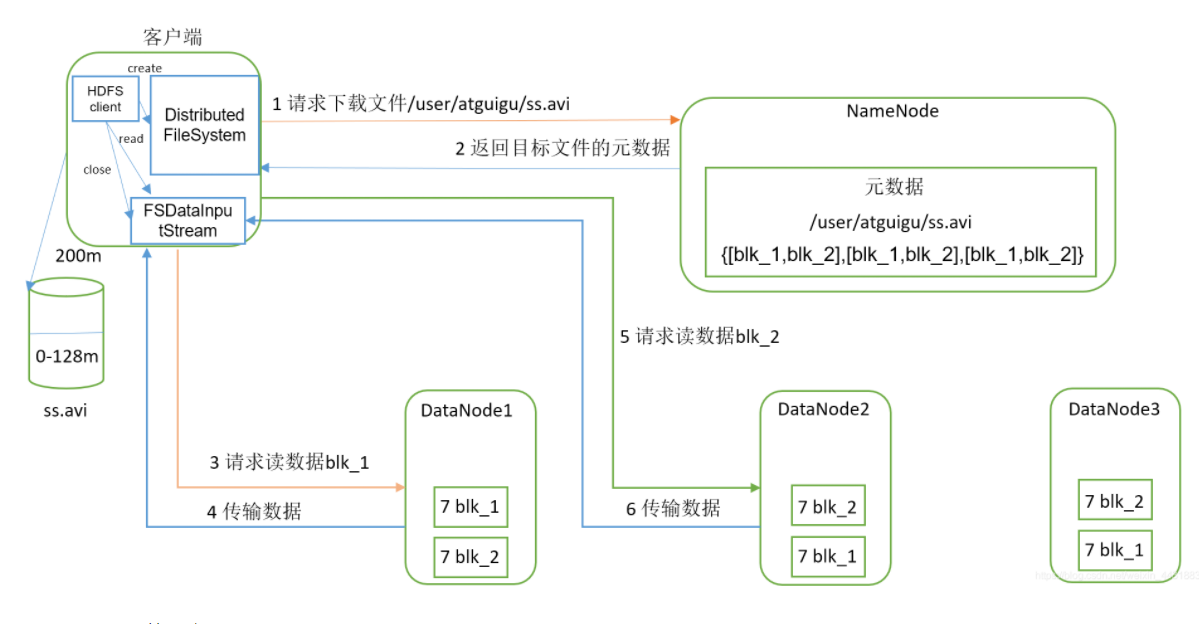
- 客户端向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode
- 挑选一台datanode(就近原则,然后随机)服务器
- datanode开始传输数据给客户端
- 客户端以packet为单位接受,先在本地缓存,然后写入目标文件
写流程
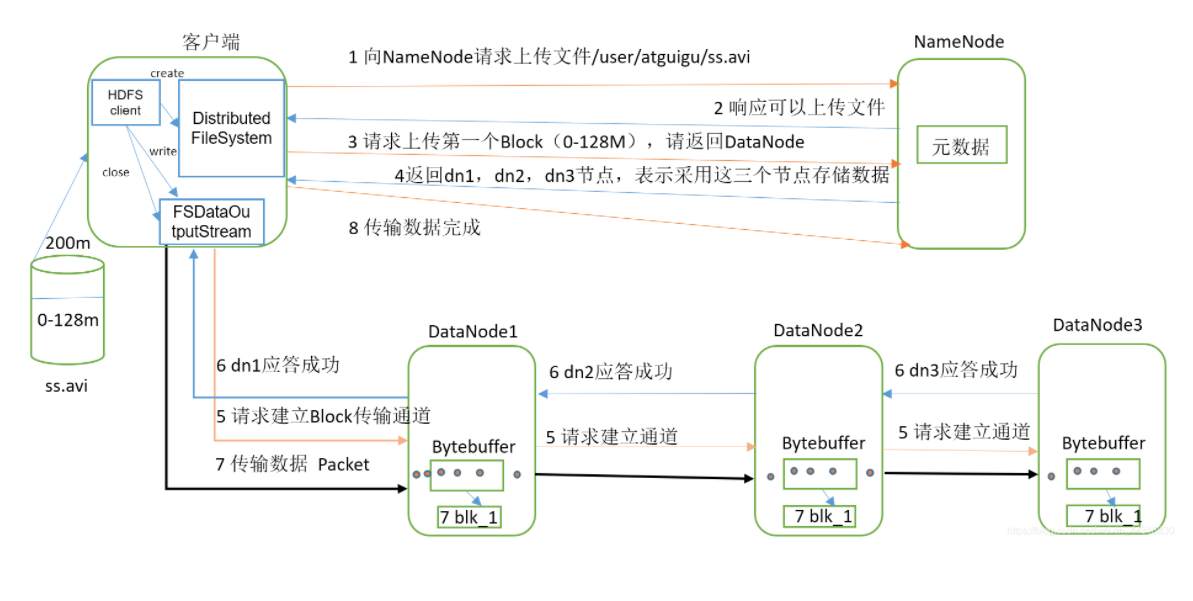
写流程
- 1.客户端请求向namenode请求上传文件,namenode检查目标文件是否已经存在
- namenode返回是否可以上传
- 客户端请求第一个block上传到哪几个datanade服务器上
- namenode返回3个datanode节点,分别为dn1、dn2、dn3
- 客户端请求dn1上传数据,dn1收到请求会继续调用dn2、dn3,将这个通道建立完成
- dn1、dn2、dn3逐级应答客户端
- 客户端开始往dn1上传第一个block,以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
- 当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器
HDFS的架构
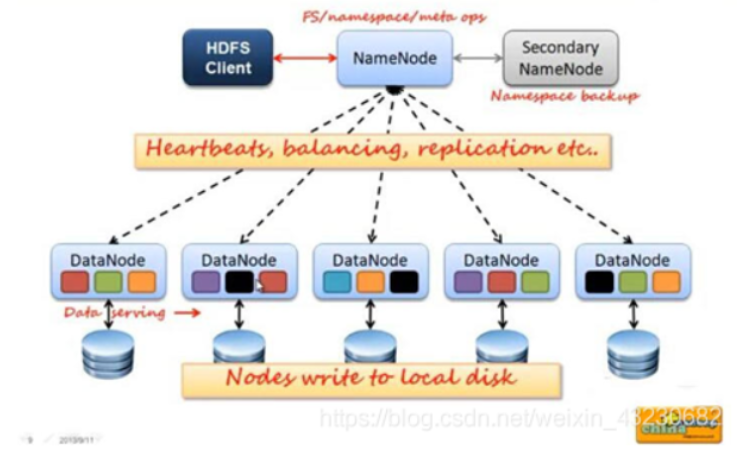
HDFS集群包括,NameNode和DataNode以及Secondary Namenode
- NameNode负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息。
- DataNode 负责管理用户的文件数据块,每一个数据块都可以在多个datanode上存储多个副本。
- Secondary NameNode用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。最主要作用是辅助namenode管理元数据信息
Yarn的工作流程Yarn的组件主要包括:
ResourceManager : 资源管理
Application Master : 任务调度
NodeManager : 节点管理,负责执行任务
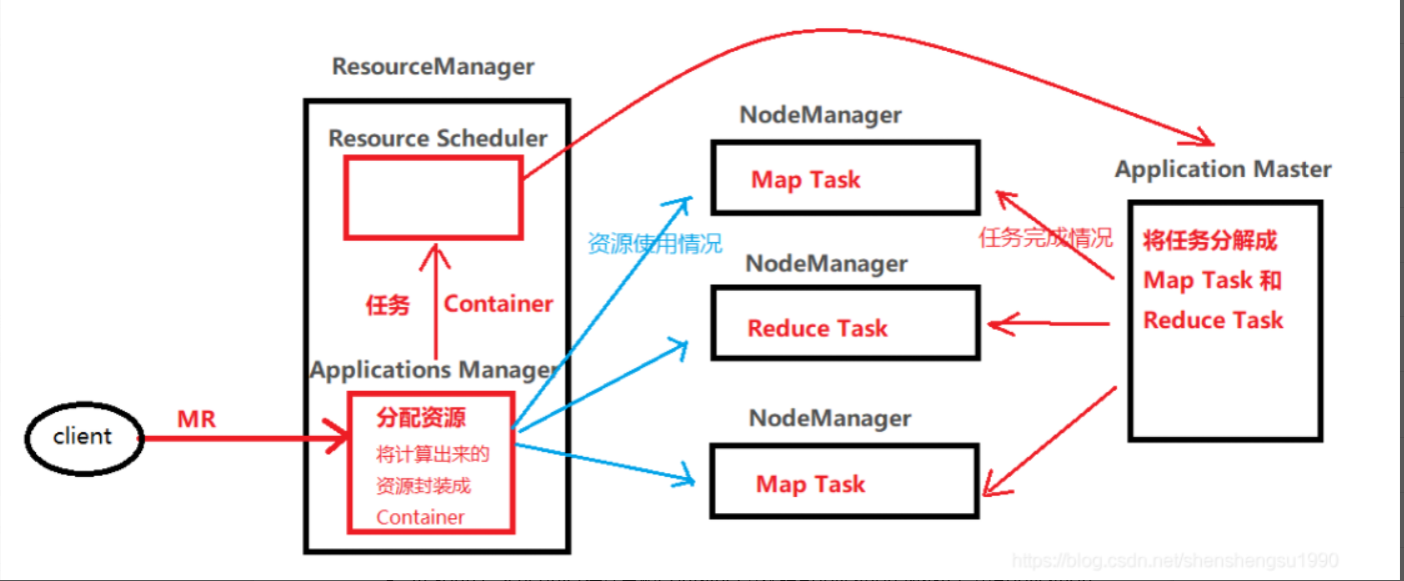
- 用户向Yarn中提交一个MR(MapReduce)任务,由ResourceManager中的Applications Manager接收
- Applications Manager负责资源的分配, 根据任务计算出所需要的资源,如cpu资源和内存资源,将这些资源封装成Container
- Applications Manager将任务和Container发送给Resource Scheduler(资源调度器)
- Resource Scheduler将任务和Container分配给Application Master, 由Application Master进行二次划分, 将任务分解成MapTask和2ReduceTask
- Application Master将MapTask和ReduceTask分配给NodeManager,三个NodeManager随机接收到MapTask或者ReduceTask , 由NodeManager负责任务的执行
- 注意,Application Master会对NodeManager的任务完成情况进行监控, 而Applications Manager会对NodeManager的任务资源使用情况进行监控.
- 如果NodeManager上的任务执行成功,会把成功信息发送给Application Master和Applications Manager, 然后Applications Manager会进行资源的回收.
- 如果NodeManager上的任务执行失败,会把失败信息发送给Application Master和Applications Manager, 然后Applications Manager仍然会进行资源的回收. 此时Application Master会向Applications Manager申请资源, 重新将这个任务分配给这个NodeManager , 循环往复, 直到任务执行成功.
虽然文字看上去挺多的,但是特别好理解,搞清楚其中的组件是什么作用就不难啦
介绍一下MapReduce的Shuffle过程
关于Shuffle的理解我有另外一篇博客做了详细的描述,去看吧……见谅
小伙子,你似乎对hadoop挺了解啊,那你给我说说hadoop的优化,心中想:我就不信我难不住你了~~!!
来啊,兵来将挡水来土掩,谁怕谁啊!!
1)HDFS小文件影响
- 影响NameNode的寿命,因为文件元数据存储在NameNode的内存中
- 影响计算引擎的任务数量,比如每个小的文件都会生成一个Map任务
2)数据输入小文件处理
- 合并小文件:对小文件进行归档(Har)、自定义Inputformat将小文件存储成SequenceFile文件。
- 采用ConbinFileInputFormat来作为输入,解决输入端大量小文件场景
- 对于大量小文件Job,可以开启JVM重用
3)Map阶段
- 增大环形缓冲区大小。由100m扩大到200m
- 增大环形缓冲区溢写的比例。由80%扩大到90%
- 减少对溢写文件的merge次数。(10个文件,一次20个merge)
- 不影响实际业务的前提下,采用Combiner提前合并,减少 I/O
4)Reduce阶段
合理设置Map和Reduce数:两个都不能设置太少,也不能设置太多。太少,会导致Task等待,延长处理时间;太多,会导致 Map、Reduce任务间竞争资源,造成处理超时等错误。
设置Map、Reduce共存:调整 slowstart.completedmaps 参数,使Map运行到一定程度后,Reduce也开始运行,减少Reduce的等待时间
规避使用Reduce,因为Reduce在用于连接数据集的时候将会产生大量的网络消耗。
增加每个Reduce去Map中拿数据的并行数
集群性能可以的前提下,增大Reduce端存储数据内存的大小
5) IO 传输
- 采用数据压缩的方式,减少网络IO的的时间
- 使用SequenceFile二进制文件
你是怎么处理Hadoop宕机的问题的?
重启啊!!你这不是废话吗,问的都是什么牛马问题,没完没了了~~能这么说吗?不能,除非你觉着有什么不可抗力的因素产生,否则还是好好思考一下吧
如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB)。
如果写入文件过量造成NameNode宕机。那么调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。高峰期的时候用Kafka进行缓存,高峰期过去数据同步会自动跟上。
本次就暂时先总结这么多吧,循序渐进。希望大家能够一键三连,感谢,感谢~~
在结尾,为了首尾呼应,再附上一张小姐姐的照片,结束一段美好的学习周期~~~

最后
以上就是等待百褶裙最近收集整理的关于Hadoop相关面试题什么是Hadoop?介绍一下HDFS读写流程的全部内容,更多相关Hadoop相关面试题什么是Hadoop内容请搜索靠谱客的其他文章。








发表评论 取消回复