作者:周志湖
网名:摇摆少年梦
微信号:zhouzhihubeyond
本节主要内容
- Spark运行方式
- Spark运行原理解析
本节内容及部分图片来自:
http://blog.csdn.net/book_mmicky/article/details/25714419
http://blog.csdn.net/yirenboy/article/details/47441465
这两篇文件对Spark的运行架构原理进行了比较深入的讲解,写得非常好,建议大家认真看一下,在此向作者致敬!
1. Spark运行方式
用户编写完Spark应用程序之后,需要将应用程序提交到集群中运行,提交时使用脚本spark-submit进行,spark-submit可以带多种参数,参数选项可以通过下列命令查看
root@sparkmaster:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/bin# ./spark-submit --help
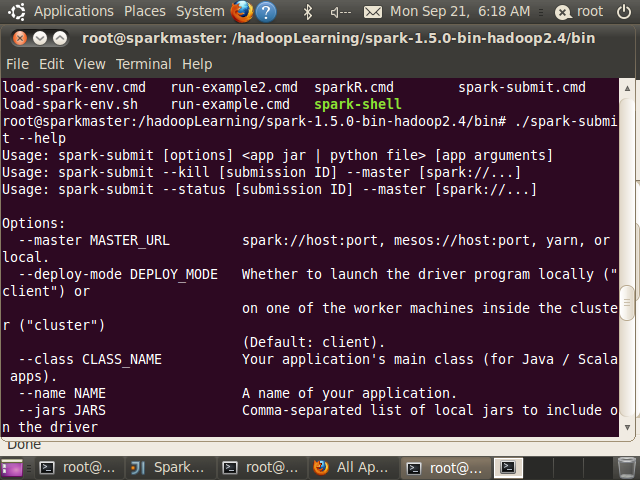
可以看到,spark-submit提交参数如下:
./bin/spark-submit
--class <main-class>
--master <master-url>
--deploy-mode <deploy-mode>
--conf <key>=<value>
... # other options
<application-jar>
[application-arguments]下面介绍几种常用Spark应用程序提交方式:
(1)本地运行方式 –master local
//--master local,本地运行方式。读取文件可以采用本地文件系统也可采用HDFS,这里给出的例子是采用本地文件系统
//从本地文件系统读取文件file:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md
//生成的结果也保存到本地文件系统:file:/SparkWordCountResult
root@sparkmaster:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/bin# ./spark-submit --master local
--class SparkWordCount --executor-memory 1g
/root/IdeaProjects/SparkWordCount/out/artifacts/SparkWordCount_jar/SparkWordCount.jar
file:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md
file:/SparkWordCountResult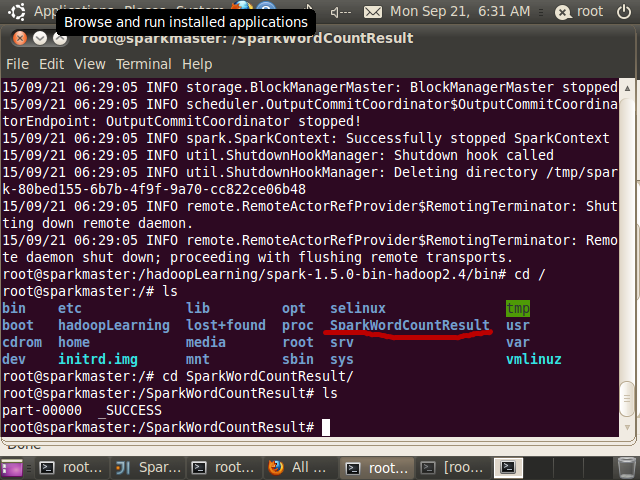
(2)Standalone运行方式 –master spark://sparkmaster:7077
采用Spark自带的资源管理器进行集群资源管理
//standalone运行,指定--master spark://sparkmaster:7077
//采用本地文件系统,也可采用HDFS
//没有指定deploy-mode,默认为client deploy mode
root@sparkmaster:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/bin#
./spark-submit --master spark://sparkmaster:7077
--class SparkWordCount --executor-memory 1g
/root/IdeaProjects/SparkWordCount/out/artifacts/SparkWordCount_jar/SparkWordCount.jar
file:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md
file:/SparkWordCountResult2
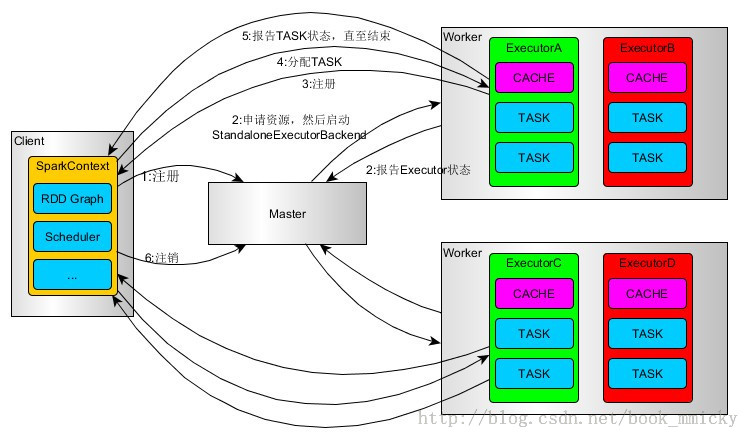
图片来源:http://blog.csdn.net/book_mmicky/article/details/25714419,
在执行过程中,可以通过http://192.168.1.103:4040查看任务状态,192.168.1.103为sparkmaster IP地址:
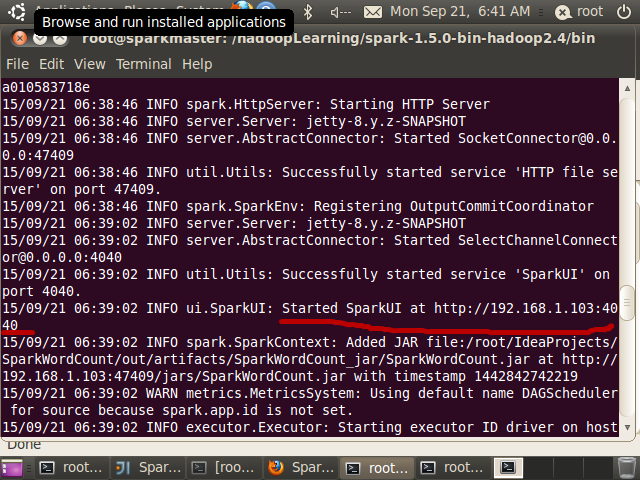
也可以指定为cluster deploy mode,例如:
root@sparkmaster:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/bin# ./spark-submit
--master spark://sparkmaster:7077
--deploy-mode cluster
--supervise --class SparkWordCount --executor-memory 1g
/root/IdeaProjects/SparkWordCount/out/artifacts/SparkWordCount_jar/SparkWordCount.jar
file:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md
file:/SparkWordCountResult3与 clinet deploy mode不同的是 cluster deploy mode中的SparkContext在集群内部创建。
(3)Yarn运行方式
采用Yarn作为底层资源管理器
//Yarn Cluster
root@sparkmaster:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/bin#
./spark-submit --master yarn-cluster
--class org.apache.spark.examples.SparkPi
--executor-memory 1g
/root/IdeaProjects/SparkWordCount/out/artifacts/SparkWordCount_jar/SparkWordCount.jar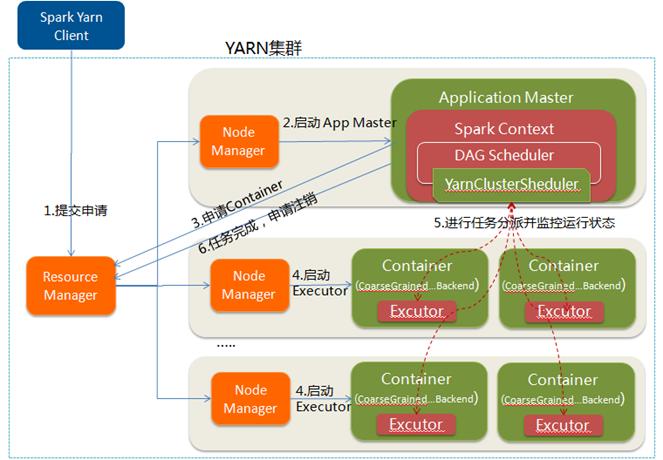
图片来源:http://blog.csdn.net/yirenboy/article/details/47441465
//Yarn Client
root@sparkmaster:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/bin#
./spark-submit --master yarn-client
--class org.apache.spark.examples.SparkPi
--executor-memory 1g
/root/IdeaProjects/SparkWordCount/out/artifacts/SparkWordCount_jar/SparkWordCount.jar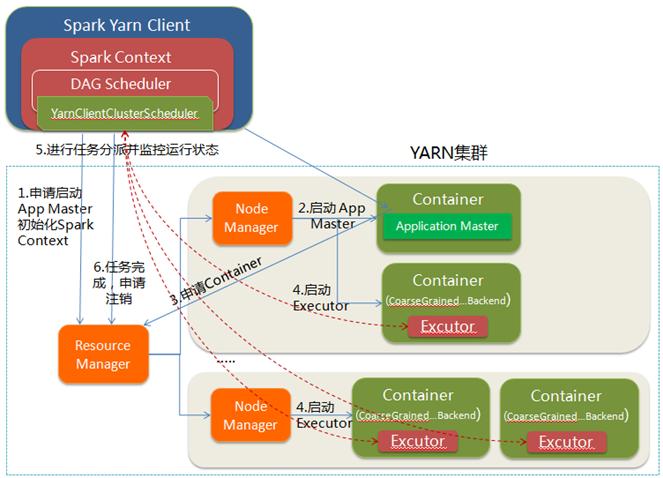
图片来源:http://blog.csdn.net/yirenboy/article/details/47441465
//Yarn Client运行效果图
2. Spark运行原理解析
(1)窄依赖与宽依赖
在前面讲的Spark编程模型当中,我们对RDD中的常用transformation与action 函数进行了讲解,我们提到RDD经过transformation操作后会生成新的RDD,前一个RDD与tranformation操作后的RDD构成了lineage关系,也即后一个RDD与前一个RDD存在一定的依赖关系,根据tranformation操作后RDD与父RDD中的分区对应关系,可以将依赖分为两种:宽依赖(wide dependency)和窄依赖(narrow dependency),如下图所示:
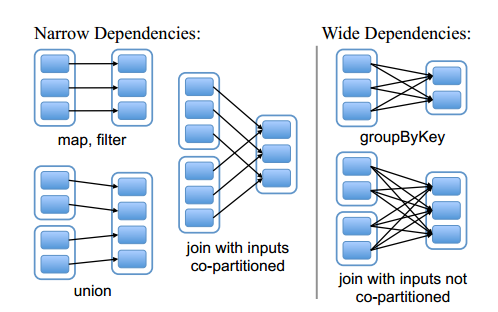
图中的实线空心矩形代表一个RDD,实线空心矩形中的带阴影的小矩形表示分区(partition)。从上图中可以看到, map,filter、union等transformation操作后的RDD仅依赖于父RDD的固定分区,它们是窄依赖的;而groupByKey后的RDD的分区与父RDD所有的分区都有依赖关系,此时它们就是宽依赖的。join操作存在两种情况,如果分区仅仅依赖于父RDD的某一分区,则是窄依赖的,否则就是宽依赖。
(2)Spark job运行原理
spark-submit提交Spark应用程序后,其执行流程如下:
1 创建SparkContext对象,然后SparkContext会向Clutser Manager(集群资源管理器),例如Yarn、Standalone、Mesos等申请资源
2 资源管理器在worker node上创建executor并分配资源(CPU、内存等),后期excutor会定时向资源管理器发送心跳信息
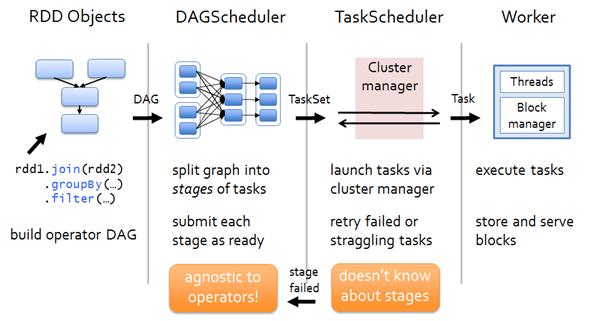
3 SparkContext启动DAGScheduler,将提交的作业(job)转换成若干Stage,各Stage构成DAG(Directed Acyclic Graph有向无环图),各个Stage包含若干相task,这些task的集合被称为TaskSet
4 TaskSet发送给TaskSet Scheduler,TaskSet Scheduler将Task发送给对应的Executor,同时SparkContext将应用程序代码发送到Executor,从而启动任务的执行
5 Executor执行Task,完成后释放相应的资源。
下图给出了DAGScheduler的工作原理:
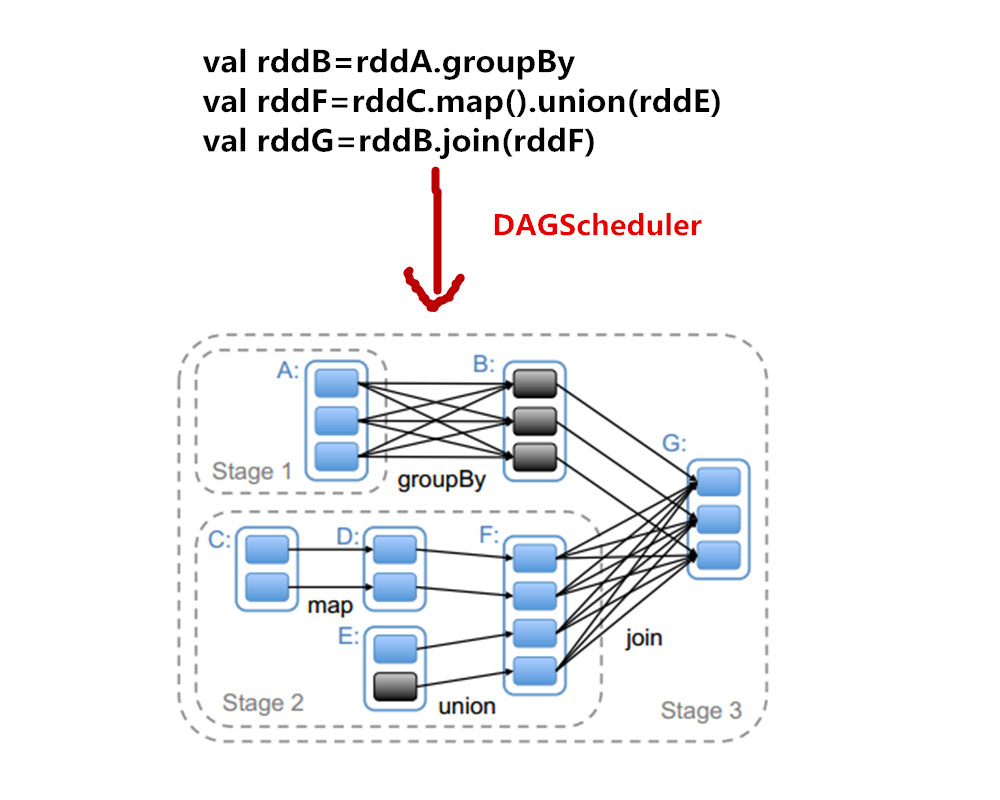
当RDDG触发相应的action操作(如collect)后,DAGScheduler会根据程序中的transformation类型构造相应的DAG并生成相应的stage,所有窄依赖构成一个stage,而单个宽依赖会生成相应的stage。上图中的黑色矩形表示这些RDD被缓存过,因此上图中的只需要计算stage2、 stage3即可
前面我们提到各Stage由若干个task组成,这些task构建taskset,最终交给Task Scheduler进行调度,最终将task发送到executor上执行,如下图所示 。
(3)spark-Shell jobs调度演示
在spark-master上,启动spark-shell
root@sparkmaster:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/bin#
./spark-shell --master spark://sparkmaster:7077
--executor-memory 1g
打开浏览器,输入: http://sparkmaster:4040/,并点击executors,可以查看集群中所有的executor,如下图所示
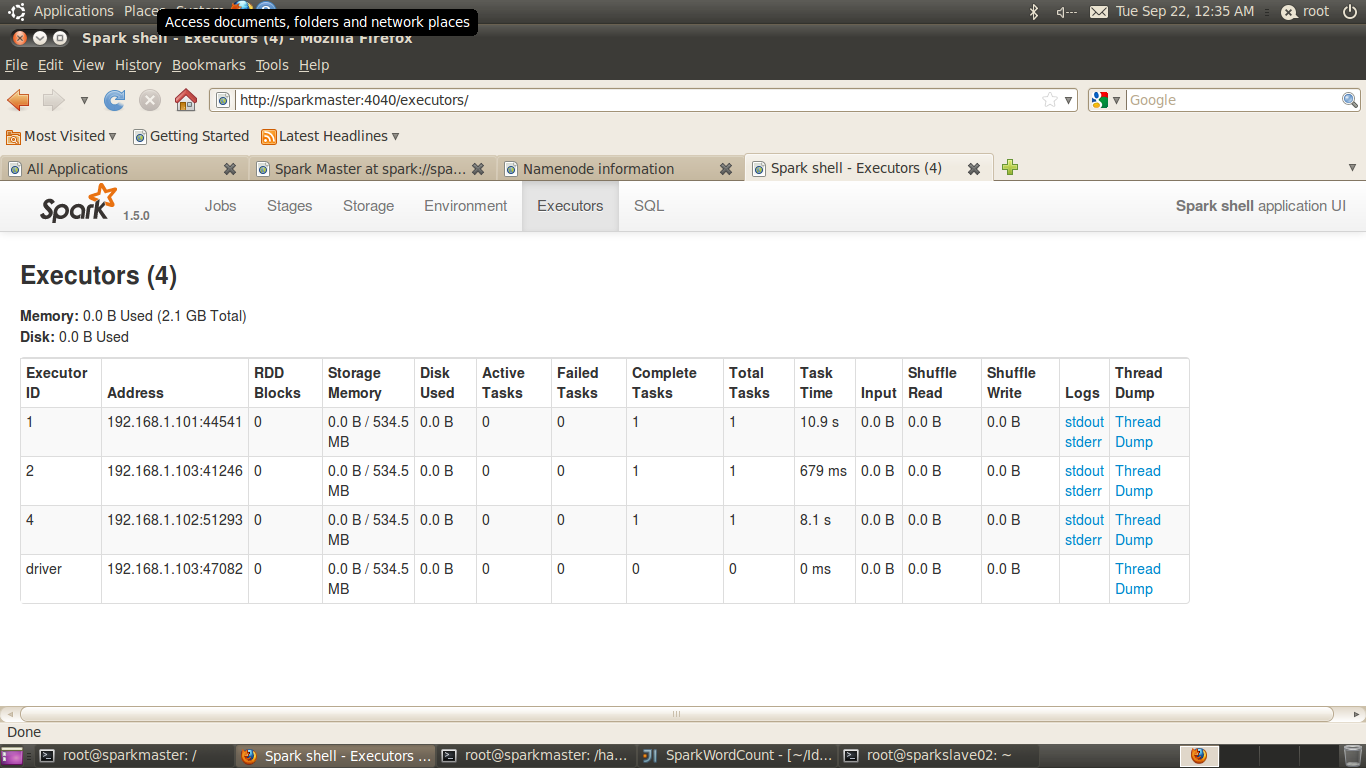
从图中可以看到sparkmaster除了是一个executor之外,它还是一个driver即(standalone clinet模式)
val rdd1= sc.textFile("/README.md")
.flatMap(line => line.split(" "))
.map(word => (word, 1))
.groupByKey().reduceByKey((a,b)=>a+b)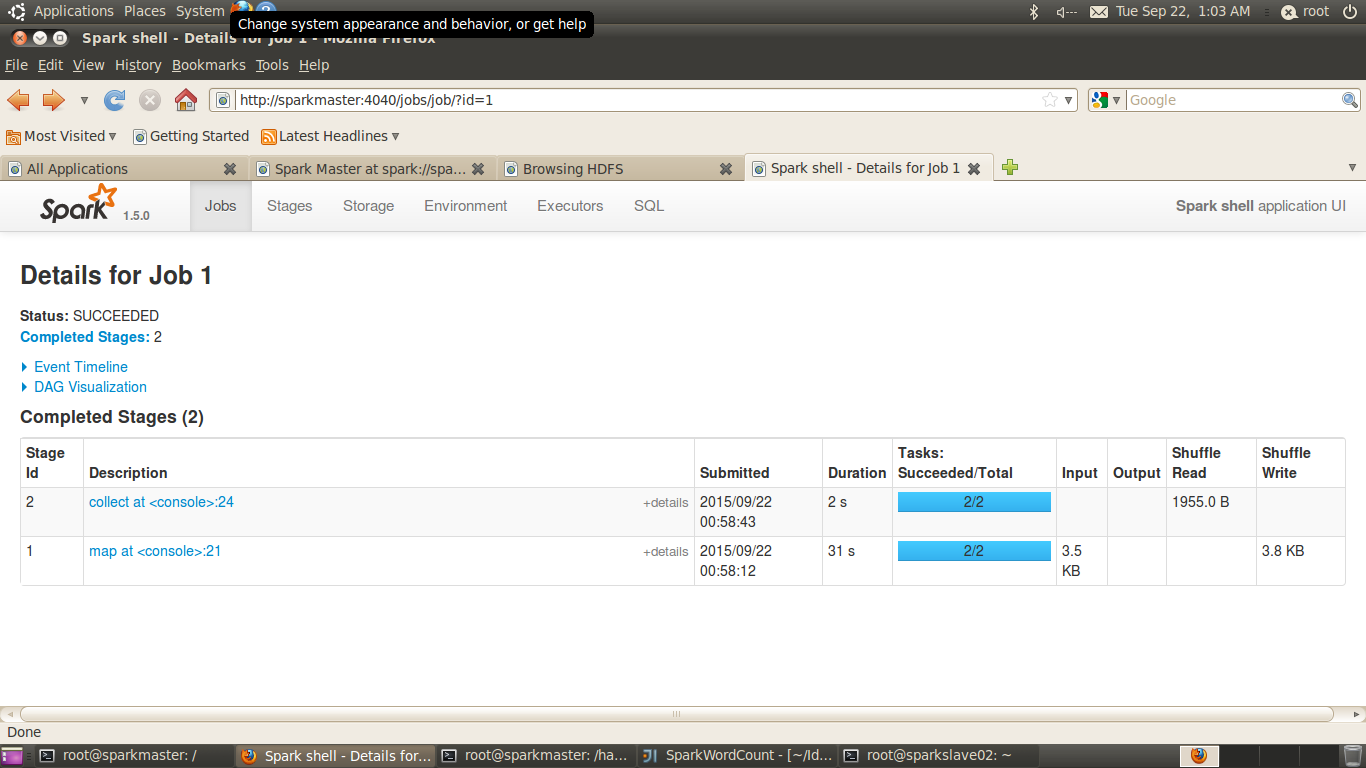
点击stage 1 对应的的map,查看该stage中对应的task信息及在对应的executor上的执行情况:
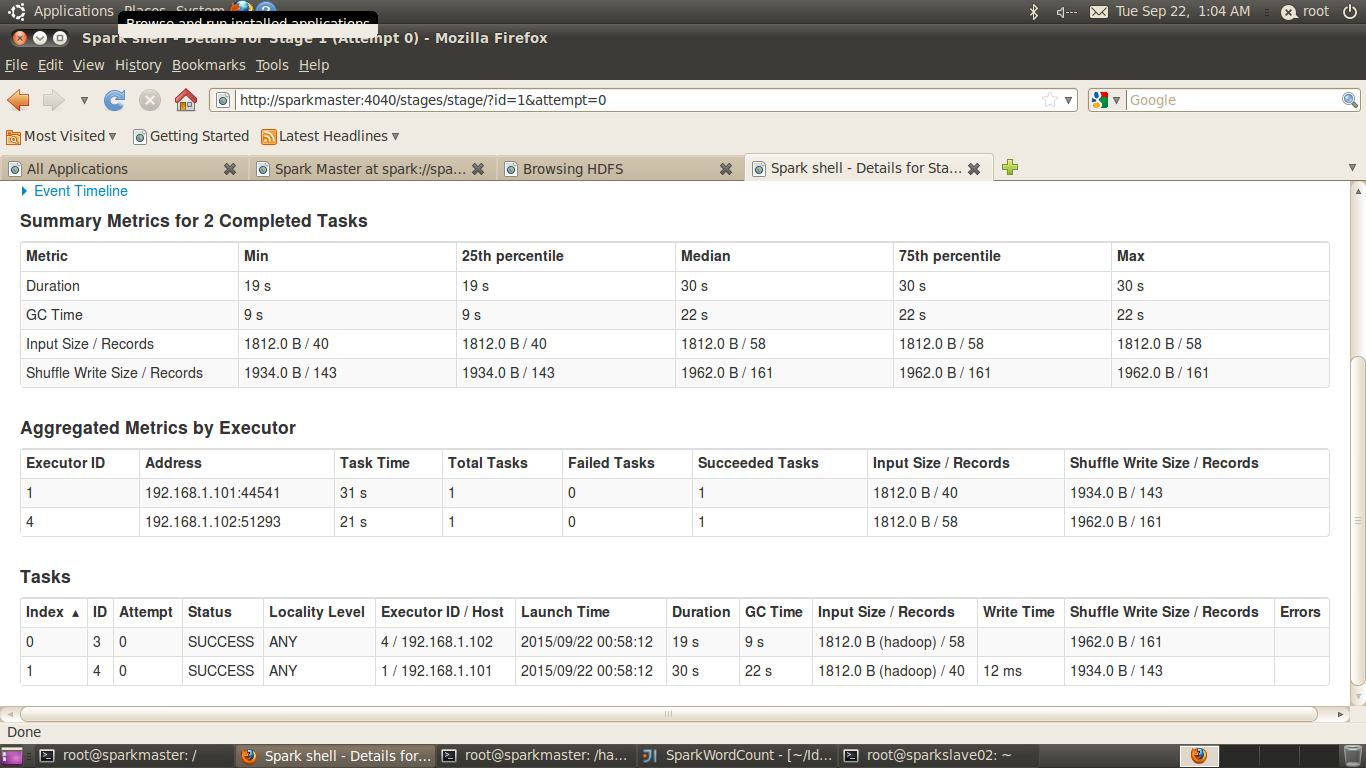
最后
以上就是甜蜜茉莉最近收集整理的关于Spark修炼之道(进阶篇)——Spark入门到精通:第七节 Spark运行原理的全部内容,更多相关Spark修炼之道(进阶篇)——Spark入门到精通:第七节内容请搜索靠谱客的其他文章。








发表评论 取消回复