问题描述
在Spark安装成功后,无论是通过spark-submit工具还是通过Intellij IDEA提交任务,只要在Spark应用程序运行期间,都可以通过WebUI控制台页面来查看具体的运行细节,在浏览器中通过地址:http://<driver-node>:4040即可查看当前的运行状态。但是一旦应用程序运行结束,该Web界面也就失效了,无法继续查看监控集群信息。无法回顾刚刚运行的程序细节,进而定向做出优化,肯定极为不便。
这时候就需要为集群配置Spark History Server了。
注:<driver-node>可以是主机名,如master,也可以是主机名对应的IP。
Spark History Server
Spark History Server可以很好地解决上面的问题。
通过配置,我们可以在Spark应用程序运行完成后,将应用程序的运行信息写入知道目录,而Spark History Server可以将这些信息装在并以Web形式供用户浏览。
要使用Spark History Server,对于提交应用程序的客户端需要配置以下参数。
Spark History Server配置(只需要在master主机进行配置)
下面以Standalone模式为例说明配置信息。更多扩展细节可以根据自己的需求在此基础上添加配置项。
1、首先配置$SPARK_HOME$/conf目录下的spark-defaults.conf文件。
默认spark-defaults.conf是不存在的,我们可以根据Spark提供的template文件新建之。
root@master:/usr/local/spark/spark-1.6.2-bin-hadoop2.6/conf# mv spark-defaults.conf.template spark-defaults.conf
root@master:/usr/local/spark/spark-1.6.2-bin-hadoop2.6/conf# vim spark-defaults.conf并修改文件内容为:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop01:8020/spark_event_data
spark.eventLog.compress true属性说明
(1) spark.eventLog.enabled。
是否记录Spark事件,用于应用程序在完成后查看WebUI。
(2) spark.eventLog.dir。
设置spark.eventLog.enabled为true后,该属性为记录spark时间的根目录。在此根目录中,Spark为每个应用程序创建分目录,并将应用程序的时间记录到此目录中。用户可以将此属性设置为HDFS目录,以便History Server读取。
(3) spark.eventLog.compress。
否压缩记录Spark事件,前提spark.eventLog.enabled为true,默认使用的是snappy。
2、在hdfs中建立存放目录。
root@master:~# hadoop fs -mkdir /spark_event_data
之后的历史记录都会被存放到这里。
3、配置spark-env.sh文件。
在之前的配置项后面
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://hadoop01:8020/spark_event_data"
属性说明
(1) spark.history.ui.port
WebUI的端口号。默认为18080,也可以自行设置。
(2) spark.history.retainedApplications
设置缓存Cache中保存的应用程序历史记录的个数,默认50,如果超过这个值,旧的将被删除。
注:缓存文件数不表示实际显示的文件总数。只是表示不在缓存中的文件可能需要从硬盘读取,速度稍有差别。
(3) spark.history.fs.logDirectory
存放历史记录文件的目录。可以是Hadoop APIs支持的任意文件系统。
启动
启动Spark的start-all.sh后,再运行start-history-server.sh文件即可启动历史服务。
root@master:/usr/local/spark/spark-1.6.2-bin-hadoop2.6/sbin# ./start-history-server.sh
启动后的效果如下(此时尚未运行程序,没有记录显示出来):
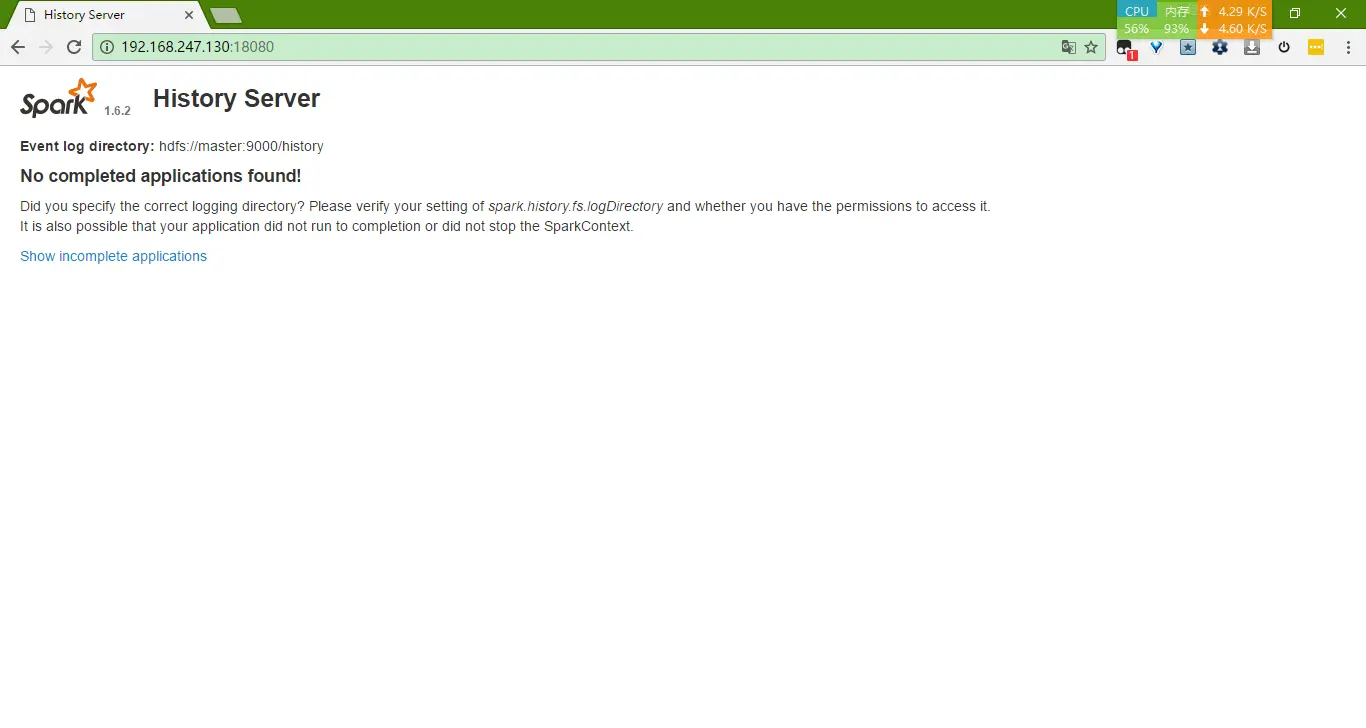
之后在每次应用程序运行结束后,就可以在这里观察刚刚程序的细节了。
小结
应用程序运行时的4040和历史记录的18080WebUI配合使用,可以让我们在运行Spark应用的时候随时监测程序运行状态,并作相应的优化和调节,效果显著。
最后
以上就是唠叨烤鸡最近收集整理的关于spark history server配置使用问题描述Spark History Server小结的全部内容,更多相关spark内容请搜索靠谱客的其他文章。








发表评论 取消回复