- RDD通过persist方法或cache方法可以将前面的计算结果缓存,默认情况下 persist() 会把数据以序列化的形式缓存在 JVM 的堆空间中。
- 但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。

- 通过查看源码发现cache最终也是调用了persist方法,默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在object StorageLevel中定义的。

在存储级别的末尾加上“_2”来把持久化数据存为两份
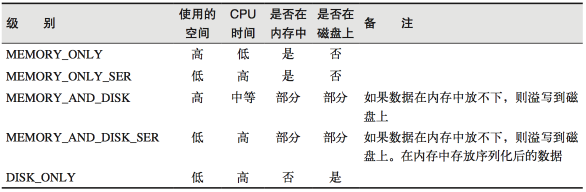
缓存有可能丢失,或者存储存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
(1)创建一个RDD
scala> val rdd = sc.makeRDD(Array("atguigu"))
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[19] at makeRDD at <console>:25
(2)将RDD转换为携带当前时间戳不做缓存
scala> val nocache = rdd.map(_.toString+System.currentTimeMillis)
nocache: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[20] at map at <console>:27
(3)多次打印结果
scala> nocache.collect
res0: Array[String] = Array(atguigu1538978275359)
scala> nocache.collect
res1: Array[String] = Array(atguigu1538978282416)
scala> nocache.collect
res2: Array[String] = Array(atguigu1538978283199)
(4)将RDD转换为携带当前时间戳并做缓存
scala> val cache = rdd.map(_.toString+System.currentTimeMillis).cache
cache: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[21] at map at <console>:27
(5)多次打印做了缓存的结果
scala> cache.collect
res3: Array[String] = Array(atguigu1538978435705)
scala> cache.collect
res4: Array[String] = Array(atguigu1538978435705)
scala> cache.collect
res5: Array[String] = Array(atguigu1538978435705)
最后
以上就是俏皮大侠最近收集整理的关于SparkCore之RDD缓存的全部内容,更多相关SparkCore之RDD缓存内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复