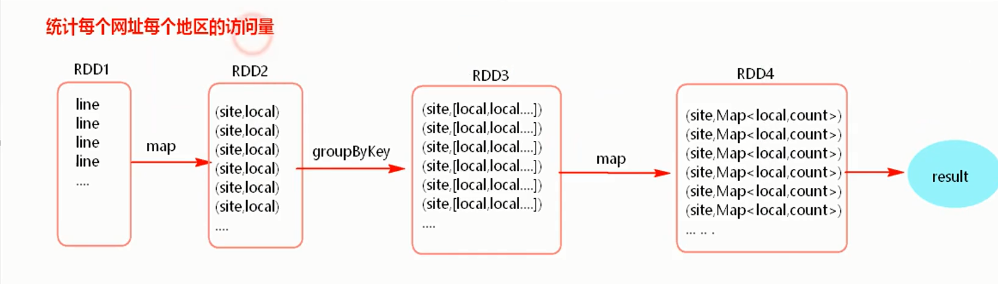
图示:
代码:
package ddd.henu.pvuv
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
import scala.collection.mutable.ListBuffer
object RegionScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("test")
val sc = new SparkContext(conf)
val lines = sc.textFile("./data/pvuvdata")
//每个网址的每个地区访问量 ,由大到小排序
val site_local = lines.map(line=>{(line.split("t")(5),line.split("t")(1))})
val site_localIterable = site_local.groupByKey()
val result = site_localIterable.map(one => {
val localMap = mutable.Map[String, Int]()
val site = one._1
val localIter = one._2.iterator
while (localIter.hasNext) {
val local = localIter.next()
if (localMap.contains(local)) {
val value = localMap.get(local).get
localMap.put(local, value + 1)
} else {
localMap.put(local, 1)
}
}
val tuples: List[(String, Int)] = localMap.toList.sortBy(one => {
one._2
})
if(tuples.size>3){
val returnList = new ListBuffer[(String, Int)]()
for(i <- 0 to 2){
returnList.append(tuples(i))
}
(site, returnList)
}else{
(site, tuples)
}
})
result.foreach(println)
/**
* (www.suning.com,ListBuffer((海南,509), (甘肃,512), (浙江,514)))
* (www.gome.com.cn,ListBuffer((浙江,489), (贵州,501), (云南,504)))
* (www.jd.com,ListBuffer((青海,492), (浙江,499), (甘肃,510)))
* (www.dangdang.com,ListBuffer((河北,490), (云南,520), (黑龙江,521)))
* (www.taobao.com,ListBuffer((台湾,493), (青海,496), (浙江,504)))
* (www.mi.com,ListBuffer((安徽,486), (河北,489), (浙江,496)))
* (www.baidu.com,ListBuffer((辽宁,509), (天津,510), (甘肃,511)))
*/
}
}
最后
以上就是热情小鸽子最近收集整理的关于Spark _12_每个网址的每个地区访问量 ,由大到小排序的全部内容,更多相关Spark内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复