Scrapy-Redis 分布式
1 分布式概述
1.0 scrapy-redis是什么
之前我们已经学习了Scrapy,它是一个通用的爬虫框架,能够耗费很少的时间就能够写出爬虫代码
Scrapy-redis是scrapy的一个组件,它使用了Redis数据库做为基础,目的为了更方便地让Scrapy实现分布式爬取
Scrapy能做的事情很多,但是要做到大规模的分布式应用则捉襟见肘。有能人改变了Scrapy的队列调度,将起始的网址从start_urls里分离出来,改为从redis读取,多个客户端可以同时读取同一个redis,从而实现了分布式的爬虫。
1.1 分布式简介
分布式爬虫用一个共同的爬虫程序,同时部署到多台电脑上运行,这样可以 提高爬虫速度,实现分布式爬虫
大型分布式爬虫主要分为以下3个层级:分布式数据中心、分布式抓取服务器及分布式爬虫程序
分布式爬虫的前提:
- 要保证每一台计算机都能够正常的执行scrapy命令,能够启动爬虫,这是对计算机硬件的最低水平、计算机系统环境和网络等多方面的基本需求,不再赘述。
- 要保证所有的爬虫程序可以访问同一个队列
分布式思路:
1.在存入数据的时候,我们可以规定一台电脑是主机,所有人都链接这个电脑数据库存入数据。
2.数据都是重复的。——怎么让数据不重复,就可以实现分布式。
如果实现分布式,我们需要建立一个公共的区域,让多台电脑去公共区域里面拿任务,这个思想和多线程任务分配很像。
通过公共管理对象,来约束每一个相互独立的资源或者程序
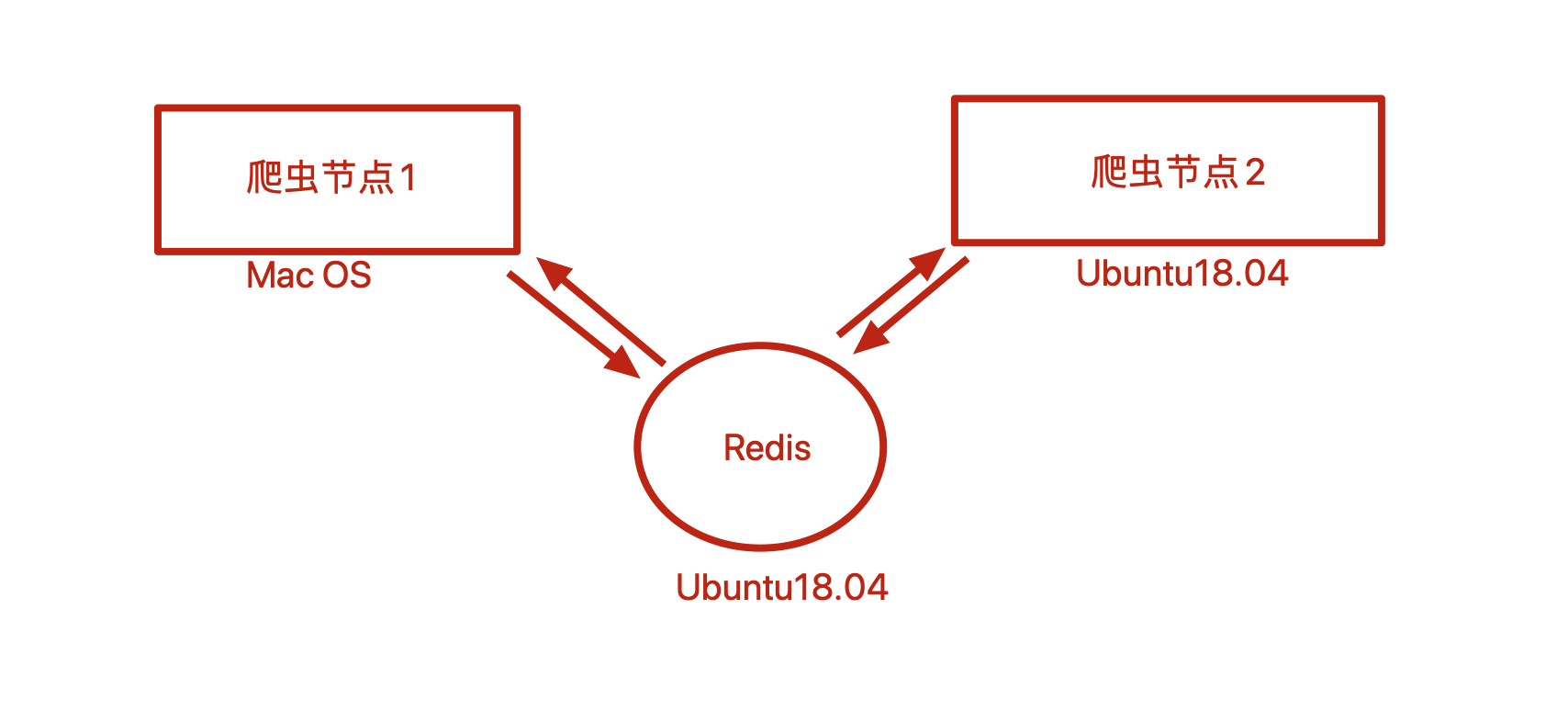
Master端(核心服务器) :使用ubuntu18,搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储Slaver端(爬虫程序执行端) :使用Mac OS X、Ubuntu 18.04, 负责执行爬虫程序,运行过程中提交新的Request给Master
1.2 框架简介
1.2.1 环境建设
- 开源地址: https://github.com/rmax/scrapy-redis.git
pip install scrapy-redis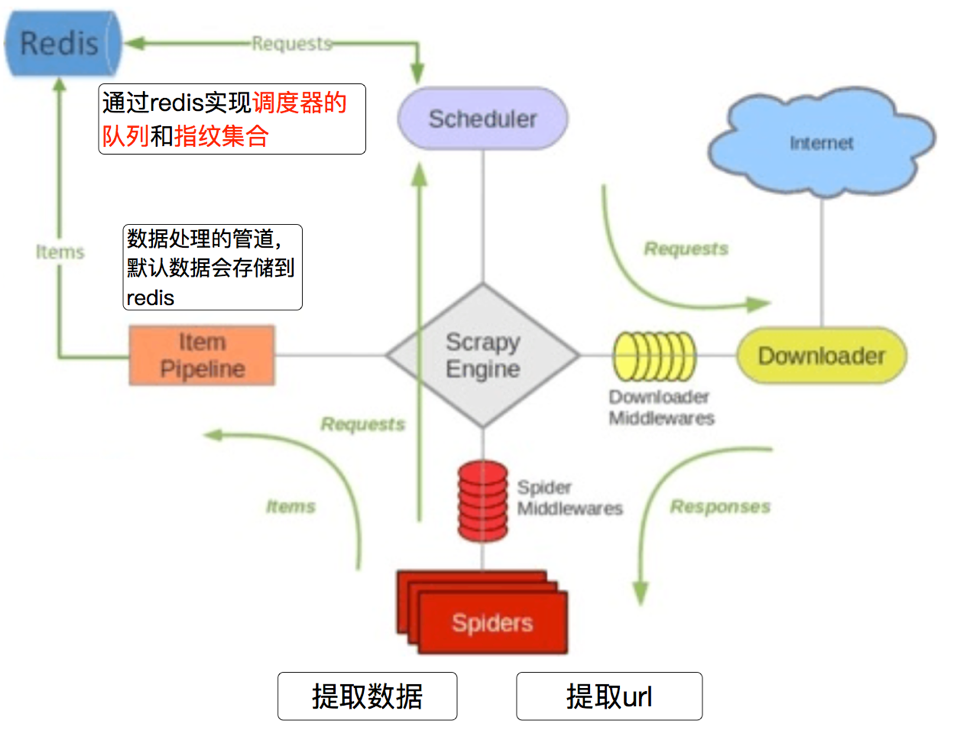
1.2.2 scrapy-redis组件
1. Scheduler(调度):
scrapy改造了python本来的collection.deque(双向队列)形成了自己scrapy queue,而scrapy-redis 的解决是把这个scrapy queue换成redis数据库,从同一个redis-server存放要爬取的request,便能让多个spider去同一个数据库里读取。
2. Duplication Filter(去重):
scrapy-redis中由Duplication Filter组件来实现去重,它通过redis的set不重复的特性,巧妙的实现了DuplicationFilter去重。
3. Item Pipline(管道):
引擎将(Spider返回的)爬取到的Item给Item Pipeline,scrapy-redis 的Item Pipeline将爬取到的 Item 存⼊redis的 items queue。修改过Item Pipeline可以很方便的根据key从items queue提取item,从而实现 items processes集群。
4. Base Spider(爬虫):
不再使用scrapy原有的Spider类,重写的RedisSpider继承了Spider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类。
2 分布式配置
2.1 redis配置
默认情况下,Redis服务只允许本地电脑访问,即Redis运行在哪台电脑就只允许这台电脑上的软件连接试用它
既然我们要做分布式爬取,就意味着别的电脑也需要访问Redis,因此需要对Redis进行配置
配置参考地址:https://www.cnblogs.com/masonblog/p/12726914.html
-
别忘了修改爬虫的配置文件
settings.py,将Redis服务器地址改为你运行Redis的服务器的ip -
服务器安装:https://blog.csdn.net/m0_60028455/article/details/125316625
2.2 核心配置
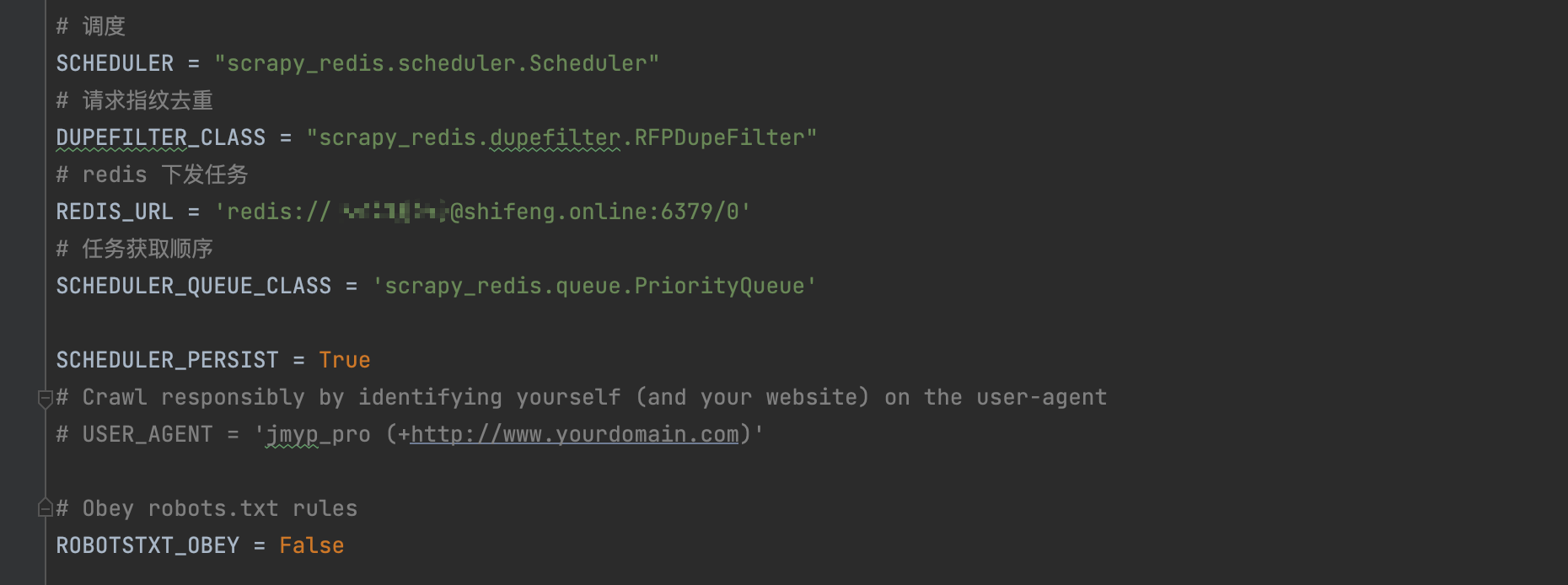
首先最主要的是,需要将调度器的类和去重的类替换为 Scrapy-Redis 提供的类,在 settings.py 里面添加如下配置即可:
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"直接在 settings.py 里面配置为 REDIS_URL 变量即可:
redis://[:password]@host:port/db
REDIS_URL = 'redis://172.25.197.89:6379/0'2.2.1 配置调度队列
此项配置是可选的,默认使用 PriorityQueue。如果想要更改配置,可以配置 SCHEDULER_QUEUE_CLASS 变量,如下所示:
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 使用有序集合来存储
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue' # 先进先出
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue' # 先进后出、后进先出2.2.2 配置持久化
此配置是可选的,默认是 False。Scrapy-Redis 默认会在爬取全部完成后清空爬取队列和去重指纹集合。
如果不想自动清空爬取队列和去重指纹集合,可以增加如下配置:
SCHEDULER_PERSIST = True # 底层 就是监听爬虫信号 触发redis指令 清空数据库2.2.3 配置重爬
此配置是可选的,默认是 False。如果配置了持久化或者强制中断了爬虫,那么爬取队列和指纹集合不会被清空,爬虫重新启动之后就会接着上次爬取。如果想重新爬取,我们可以配置重爬的选项
SCHEDULER_FLUSH_ON_START = True这样将 SCHEDULER_FLUSH_ON_START 设置为 True 之后,爬虫每次启动时,爬取队列和指纹集合都会清空。所以要做分布式爬取,我们必须保证只能清空一次,否则每个爬虫任务在启动时都清空一次,就会把之前的爬取队列清空,势必会影响分布式爬取。
3 项目实战
3.1 目标地址
- 首页:http://gz.jumei.com/
- 数据:http://search.jumei.com/?filter=0-11-1&search=保湿&from=search_toplist_保湿_word_pos_1&cat=
3.2 项目分析
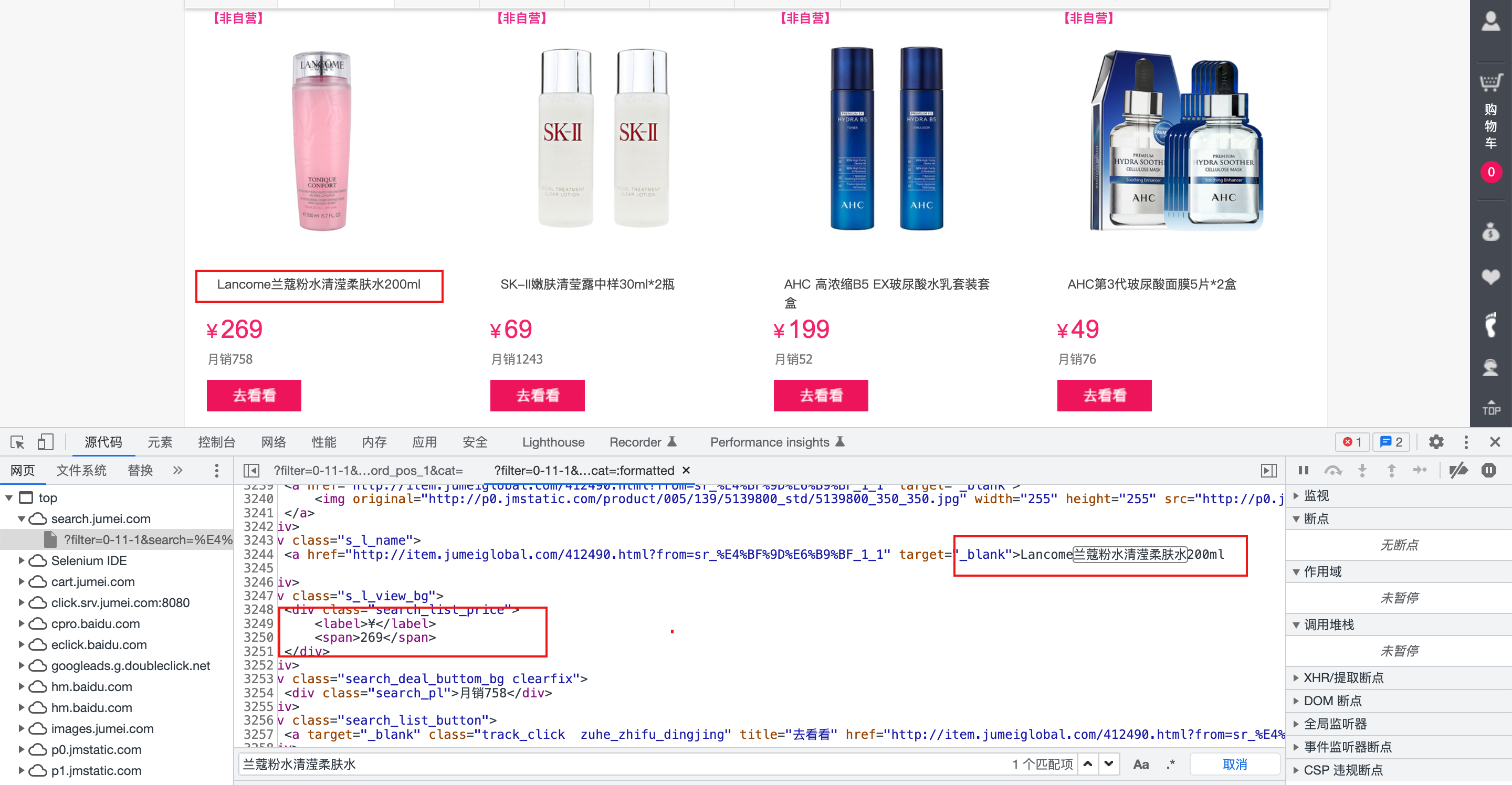
数据页面,从图可以看出,数据全在html页面里面,可以使用xpath进行提取
3.3 项目结构
改写spider文件
import scrapy
from lxml import etree
from scrapy_redis.spiders import RedisSpider
from jmyp.items import JmypItem
from scrapy_redis.dupefilter import RFPDupeFilter
from scrapy_redis.scheduler import Scheduler
from scrapy_redis.queue import PriorityQueue,LifoQueue,FifoQueue
class MmSpider(RedisSpider):
name = 'mm'
# allowed_domains = ['jumei.com']
# start_urls = ['http://gz.jumei.com/']
# keyword = ['保湿','香水']
redis_key = 'lisi'
# lpush lisi http://search.jumei.com/?filter=0-11-1&search=香水
# def start_requests(self):
# for i in self.keyword[1:]:
# url = f'http://search.jumei.com/?filter=0-11-1&search={i}'
# yield scrapy.Request(url=url)
rules = {
'title': './/div[@class="s_l_name"]/a//text()',
'price': './/div[@class="search_list_price"]/span/text()',
'link': './/div[@class="s_l_pic"]/a/@href',
}
def parse(self, response):
html = etree.HTML(response.text)
good_list = html.xpath('//div[@class="products_wrap"]/ul/li')
for data in good_list[1:3]:
items = JmypItem()
# items = {}
items['title'] = self.get_title(data)
items['price'] = self.get_price(data)
items['link'] = self.get_link(data)
# print(items)
yield items
next = html.xpath('//ul[@class="page-nav"]/li[@class="last"]')
if next:
page = ''.join(html.xpath('//a[@class="next"]/@href'))
yield scrapy.Request(url=page)
def get_title(self, x):
# 标题
title = ''.join(x.xpath(self.rules['title'])).strip()
return title
def get_price(self,x):
price = ''.join(x.xpath(self.rules['price']))
return price
def get_link(self,x):
link = ''.join(x.xpath(self.rules['link']))
return linkitem文件编写
- 编写item文件,定义数据结构
import scrapy
class JmypItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
link = scrapy.Field()scrapy-redis 改写
ITEM_PIPELINES = {
'jmyp.pipelines.JmypPipeline': 290,
'scrapy_redis.pipelines.RedisPipeline': 300
}
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
REDIS_URL = 'redis://172.25.197.89:6379/0'数据保存到mongo
import pymongo
from jmyp.items import JmypItem
class JmypPipeline:
def __init__(self):
collection = pymongo.MongoClient()
self.conn = collection['xxx']['xx']
def process_item(self, item, spider):
print(item)
if isinstance(item, JmypItem):
self.conn.insert_one(dict(item))
return itemScrapy-redis框架执行过程总结:
- 最后总结一下scrapy-redis的总体思路:这套组件通过重写scheduler和 spider类,实现了调度、spider启动和redis的交互。
- 实现新的dupefilter和queue类,达到了判重和调度容器和redis 的交互,因为每个主机上的爬虫进程都访问同一个redis数据库,所以调度和判重都统一进行统一管理,达到了分布式爬虫的目的。
- 当spider被初始化时,同时会初始化一个对应的scheduler对象,这个调度器对象通过读取settings,配置好自己的调度容器queue和判重工具dupefilter。
- 每当一个spider产出一个request的时候,scrapy引擎会把这个reuqest递交给这个spider对应的scheduler对象进行调度,scheduler对象通过访问redis对request进行判重,如果不重复就把他添加进redis中的调度器队列里。当调度条件满足时,scheduler对象就从redis的调度器队列中取出一个request发送给spider,让他爬取。
- 当spider爬取的所有暂时可用url之后,scheduler发现这个spider对应的redis的调度器队列空了,于是触发信号spider_idle,spider收到这个信号之后,直接连接redis读取start_urls池,拿取新的一批url入口,然后再次重复上边的工作。
4 扩展方面
redis地址
- redis服务:https://blog.csdn.net/weixin_42405819/article/details/125711224
- redis可视化:https://goanother.com/cn/#download
子系统安装:https://blog.csdn.net/m0_60028455/article/details/125316625
注:
-
新的ubuntu在本地连接,需要安装ssh服务端
-
本课程练习,需要在服务器安装redis
-
解释器:https://docs.conda.io/en/latest/miniconda.html#
最后
以上就是可靠冥王星最近收集整理的关于Python爬虫-Scrapy-Redis分布式的全部内容,更多相关Python爬虫-Scrapy-Redis分布式内容请搜索靠谱客的其他文章。








发表评论 取消回复