依赖环境:
redis >=2.8
scrapy >=1.1
分布式爬虫:将一个项目拷贝到多台电脑上,同时爬取数据。
1.必须保证所有电脑上的代码是相同的配置。
2.在其中一台电脑上启动redis和MySQL的数据库服务。
3.同时将所有的爬虫项目运行起来。
4.在启动redis和MySQL的电脑上, 向redis中添加起始的url。
q = queue()
url = q.get() # 如果队列是空的,那么get()方法会一直阻塞,直到能取到url,才会继续向下执行。
单机爬虫:一台电脑运行一个项目。去重采用了set()和queue(),但是这两个都是在内存中存在的。
1>其他电脑是无法获取另外一台电脑内存中的数据的。
2>程序终止,内存消失。
分布式问题:
1.多台电脑如何统一的对URL进行去重?
2.多台电脑之间如何共用相同的队列?多台电脑获取的request,如何在多台电脑之间进行同步?
3.多台电脑运行同一个爬虫项目,如果有机器爬虫意外终止,如何保证可以继续从队列中获取新的request,而不是从头开始爬取?
前两个问题可以基于Redis实现。相当于将set()和queue()从scrapy框架中抽离出来,将其保存在一个公共的平台中(Redis)。
第三个问题:scrapy_redis已经实现了,重启爬虫不会从头开始重新爬取,而是会继续从队列中获取request。不用担心爬虫意外终止。
scrapy_redis第三方库实现分布的部署:
分布式爬虫:只需要在众多电脑中,选择其中一台开启redis服务,目的就是在redis中创建公用的queue和公用的set,然后剩余电脑只需要连接redis服务即可,剩余电脑不需要开启redis-server服务。
步骤:
1>在虚拟环境中安装pip install redis
2>去github上搜索scrapy_redis库,解压,保存到项目根目录下。根据提供的用例,配置我们的项目,大致三部分:
1.settings.py文件;
# 配置scrapy_redis第三方库 # 所有电脑配置调度器,这个调度器重写了scrapy框架内置的调度器。
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 所有电脑配置去重, 这个也是重写了scrapy内置的去重。
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 所有电脑配置redis的连接地址,设置局域网IP或者公网IP,保证所有电脑都能连接到同一个redis。6379是redis的默认端口号。
# redis数据库默认只允许本地连接localhost,如需配置远程连接,需要修改redis的配置文件。修改完成以后,要重启redis-server服务。
# 1. (A B C) 如果用的是局域网部署的分布式,选择其中一台电脑(A)开启redis-server服务,REDIS_URL就配置成A电脑的局域网IP地址。如果B电脑开启redis-server->REDIS_URL B电脑的IP地址。
# 2. (A B C) 如果用的是公网IP(阿里云),那么所有电脑都不需要开启redis-server服务,只需要将REDIS_URL的主机地址配置成公网IP即可。 # myroot: 自定义的redis链接(可不写)。IP:开启redis-server服务的这台电脑的IP
REDIS_URL = 'redis://myroot:@192.168.40.217:6379'
# item_pipelines可以配置,也可以不用配置。如果配置的话:所有下载的item,除了会被保存在数据库MySQL中,还会被保存在Redis数据库中。没有配置:所有的item不会存储在Redis数据库中
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
# 配置HOST为局域网IP,或者公网IP
MYSQL_HOST = '192.168.70.246'
MYSQL_DB = 'jobbole'
MYSQL_USER = 'myroot'
MYSQL_PASSWD = '123456'
MYSQL_CHARSET = 'utf8'
MYSQL_PORT = 3306
# 配置scrapy_redis第三方库
# 所有电脑配置调度器,这个调度器重写了scrapy框架内置的调度器。
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 所有电脑配置去重, 这个也是重写了scrapy内置的去重。
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 所有电脑配置redis的连接地址,设置局域网IP或者公网IP,保证所有电脑都能连接到同一个redis。6379是redis的默认端口号。
# redis数据库默认只允许本地连接localhost,如需配置远程连接,需要修改redis的配置文件。修改完成以后,要重启redis-server服务。
# 1. (A B C) 如果用的是局域网部署的分布式,选择其中一台电脑(A)开启redis-server服务,REDIS_URL就配置成A电脑的局域网IP地址。如果B电脑开启redis-server->REDIS_URL B电脑的IP地址。
# 2. (A B C) 如果用的是公网IP(阿里云),那么所有电脑都不需要开启redis-server服务,只需要将REDIS_URL的主机地址配置成公网IP即可。
REDIS_URL = 'redis://@192.168.70.246:6379'
# 可以配置,也可以不用配置。如果配置的话:所有下载的item,除了会被保存在数据库MySQL中,还会被保存在Redis数据库中。没有配置:所有的item不会存储在Redis数据库中。
# ITEM_PIPELINES = {
# 'scrapy_redis.pipelines.RedisPipeline': 300
# }
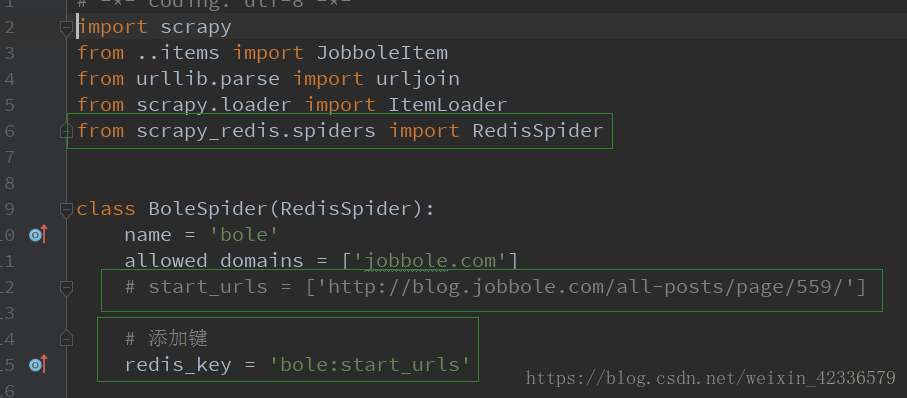
2.jobbole.py文件;
from scrapy_redis.spiders import RedisSpider
class JobboleSpider(RedisSpider):
name = 'jobbole'
allowed_domains = ['jobbole.com']
# start_urls = ['http://blog.jobbole.com/all-posts/']
# 添加键
redis_key = 'jobbole:start_urls'
3.有关数据库部分;
首先要把MySQL添加到环境变量中
第一步:通过mysql -uroot -p登录MySQL服务。
第二步:通过grant all privileges on *.* to 'myroot'@'%' identified by '123456';(注意一定要带上分号)。
# *.* 表示所有数据库中的所有表,都能够被远程连接
# '%' 表示任意IP都可以进行链接
# 'myroot' 具有远程链接权限的用户名,自定义。之后就使用这个User进行链接数据库
mysql->grant all privileges on *.* to 'myroot'@'%' identified by '123456'; 回车即可
第三步:再去修改爬虫项目(settings.py)中有关数据库的配置。
MYSQL_HOST = '192.168.40.217'
MYSQL_DBNAME = 'article_db'
MYSQL_USER = 'myroot'
MYSQL_PASSWORD = '123456'
MYSQL_CHARSET = 'utf8'
然后在数据库中新建连接,连接名随便起,主机名或IP地址要与settings.py中配置的一致,即开启redis-server服务的这台电脑 的IP,用户名和密码与settings.py 一致。
3>将配置好的项目,拷贝到不同的机器中;
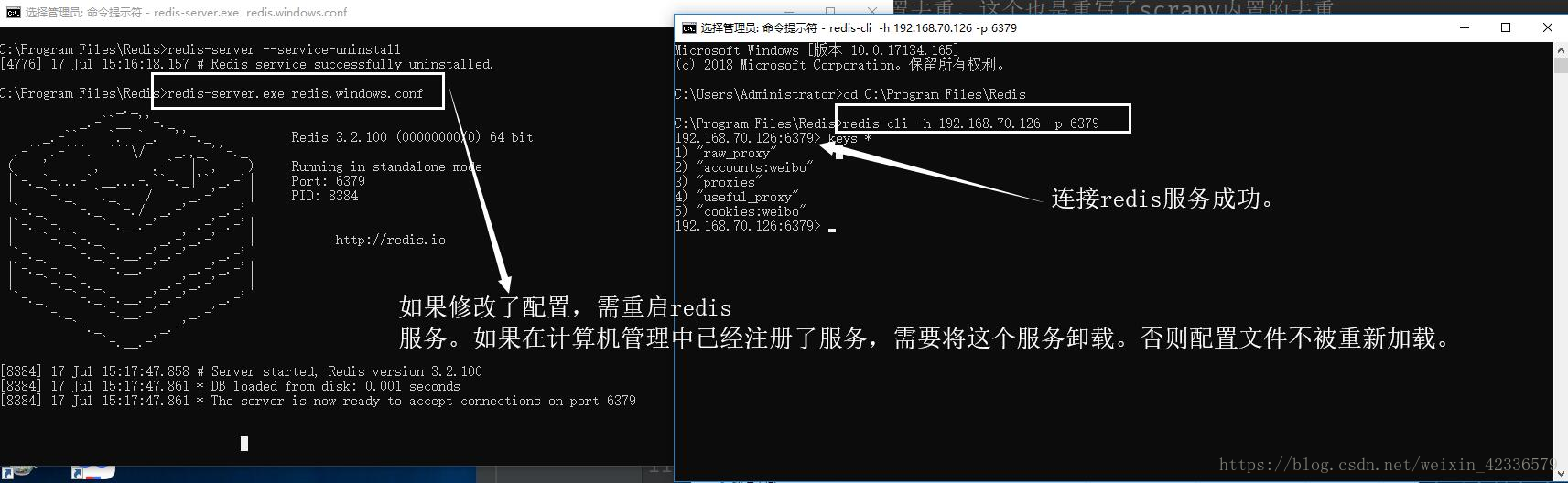
4>选择其中一台机器,开启redis-server服务,并修改redis.windows.conf配置文件:
# 配置远程IP地址,供其他的电脑进行连接redis
bind: (当前电脑IP) 192.168.40.217
# 关闭redis保护模式
protected-mode: no
5>其中一台电脑启动redis-server服务
6>让所有爬虫项目都运行起来,由于没有起始的url,所有爬虫会暂时处于停滞状态
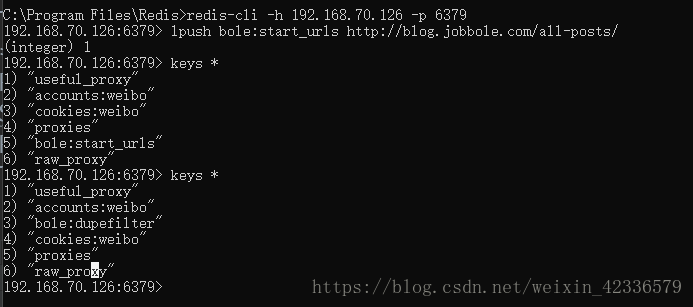
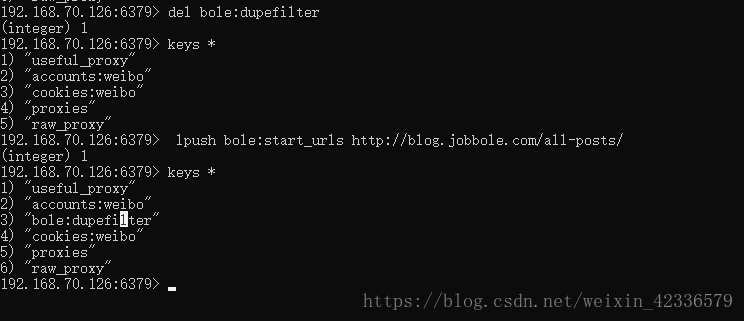
7>所有爬虫都启动之后,部署redis-server服务的电脑,通过命令redis-cli lpush jobbole:start_urls http://blog.jobbole.com/all-posts/向redis的queue中添加起始的url
8>所有爬虫开始运行,爬取数据,同时所有的数据都会保存到该爬虫所连接的远程数据库以及远程redis中
最后
以上就是听话篮球最近收集整理的关于分布式爬虫配置(伯乐在线为例)的全部内容,更多相关分布式爬虫配置(伯乐在线为例)内容请搜索靠谱客的其他文章。








发表评论 取消回复