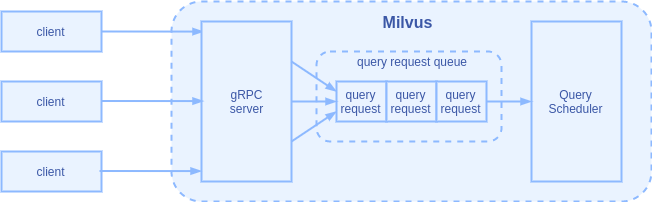
| 查询请求队列
Milvus 的连接层使用 gRPC 对外提供 RPC 服务,以及 oatpp 框架对外提供 RESTful 服务。服务端的 gRPC 连接池设置的最大连接数是 20,多个客户端同时发过来的查询请求被异步接收。但由于每个查询请求需要大量的计算资源,如果多个查询同时执行就会互相争抢资源。因此,连接层会把查询请求放入一个队列中,让后台的查询调度器(Query Scheduler)从队列末尾取出查询请求并一个个执行。
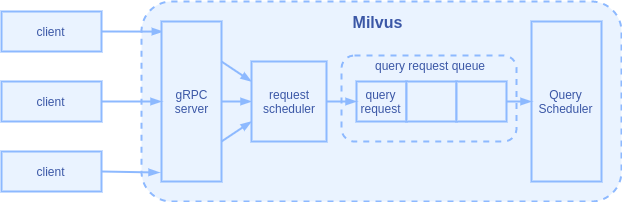
| 查询合并
为了提高 QPS(Query Per Second),从 0.8.0 版本开始,Milvus 在接收到查询请求后,会尝试对查询请求做合并处理。
合并查询能够提高查询效率的主要依据是:对于 nq(目标向量数)较小的查询,CPU/GPU 的并行度不高,计算资源部分闲置;如果将多个查询的目标向量合在一起计算,则能够提高计算资源的使用率。
在客户端请求进入队列之前,增加了一个请求调度的环节,可根据不同的策略对请求进行预处理。
对于查询请求的预处理是:先检查队列中是否仍然存在还未被取走的查询请求;如果有,则将上一次进入队列的查询请求与新的查询请求做比对;如果满足合并的条件,则将两者合并成为一个请求放入队列,并将上一次的查询请求移出队列:
查询请求的合并允许多个合并,具体能够合并的请求数目由 Milvus 运行时的状态决定。多个查询合并需满足如下几个条件:
-
查询目标为同一个集合,并且在相同的分区内查询
-
topk 参数相差不超过 200
-
合并的目标向量数量最多不超过 200
-
其他和索引相关的查询参数必须相同,比如 nprobe
以下是一组示例:
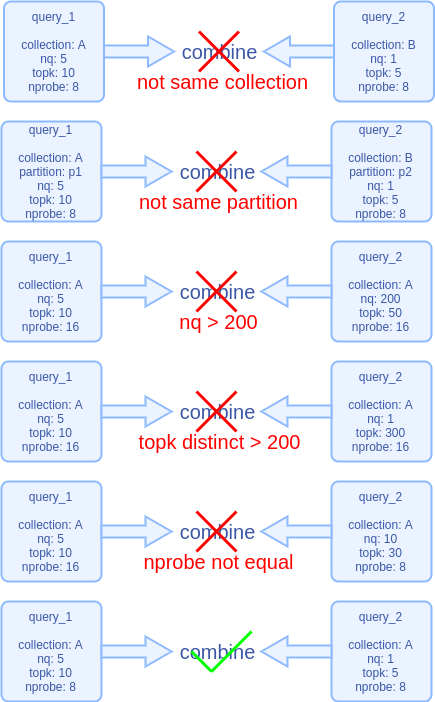
如果对向量搜索原理有了解,就不难理解设置这些合并条件的原因:
-
同一个集合,相同的分区限定了搜索的范围,只有在相同的范围内搜索,多个查询才不会互相干扰。
-
nq 小于200是为了计算的耗时不要太长,以免单个请求等待太长时间。
-
topk 相差小于 200 是出于对结果集处理的方便性考虑。
-
跟索引相关的查询参数要相同,因为这样才能在内部 ANNS 库计算时采取相同的流程。
| 合并查询对查询效率的提升
下面我们使用 pymilvus 对合并查询的效果做一个测试。
| 硬件环境 | Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz 12 核 |
| Milvus 版本 | 0.9.1 GPU version |
| 测试数据集 | 1000 万条 128 维随机生成的向量 |
| 索引 | IVFSQ8,nlist 为 2048 |
| 查询参数 | 执行 1000 次查询,nq 为 1,topk 为 10,nprobe 为 16 |
客户端单线程执行 1000 次查询的脚本:
import time
import threading
import numpy as np
from milvus import Milvus, IndexType
from milvus.client.types import MetricType
SERVER_ADDR = "127.0.0.1"
SERVER_PORT = '19530'
COLLECTION_DIMENSION = 128
COLLECTION_NAME = "TEST"
INDEX_TYPE = IndexType.IVF_SQ8
INDEX_PARAM = {'nlist': 2048}
SEARCH_PARAM = {'nprobe': 16}
TOPK = 10
MILVUS = Milvus(host=SERVER_ADDR, port=SERVER_PORT)
def gen_vec_list(nb, seed=np.random.RandomState(1234)):
xb = seed.rand(nb, COLLECTION_DIMENSION).astype("float32")
vec_list = xb.tolist()
return vec_list
def search(vec_list):
status, result = MILVUS.search(collection_name=COLLECTION_NAME, top_k=TOPK,
query_records=vec_list, params=SEARCH_PARAM)
def multi_search():
time_start = time.time()
SEARCH_COUNT = 1000
vec_list = gen_vec_list(1)
for k in range(SEARCH_COUNT):
search(vec_list=vec_list)
time_end = time.time()
total_cost = time_end - time_start
print("search total cost", total_cost, 'sec')
print('QPS = ', SEARCH_COUNT/total_cost)
if __name__ == "__main__":
multi_search()
执行脚本 3 次,取平均值:
-
1000 次查询的总耗时:7.18 秒
-
QPS:139.24
客户端多线程执行 1000 次查询的脚本:
import time
import threading
import numpy as np
from milvus import Milvus, IndexType
from milvus.client.types import MetricType
SERVER_ADDR = "127.0.0.1"
SERVER_PORT = '19530'
COLLECTION_DIMENSION = 128
COLLECTION_NAME = "TEST"
INDEX_TYPE = IndexType.IVF_SQ8
INDEX_PARAM = {'nlist': 2048}
SEARCH_PARAM = {'nprobe': 16}
TOPK = 10
MILVUS = Milvus(host=SERVER_ADDR, port=SERVER_PORT)
def gen_vec_list(nb, seed=np.random.RandomState(1234)):
xb = seed.rand(nb, COLLECTION_DIMENSION).astype("float32")
vec_list = xb.tolist()
return vec_list
def search(vec_list):
status, result = MILVUS.search(collection_name=COLLECTION_NAME, top_k=TOPK,
query_records=vec_list, params=SEARCH_PARAM)
def multi_search():
time_start = time.time()
SEARCH_COUNT = 1000
threads = []
vec_list = gen_vec_list(1)
for k in range(SEARCH_COUNT):
x = threading.Thread(target=search, args=(vec_list,))
threads.append(x)
x.start()
for th in threads:
th.join()
time_end = time.time()
total_cost = time_end - time_start
print("search total cost", total_cost, 'sec')
print('QPS = ', SEARCH_COUNT/total_cost)
if __name__ == "__main__":
multi_search()
执行脚本 3 次,取平均值:
-
1000 次查询的总耗时:4.93 秒
-
QPS:202.79
| 欢迎加入 Milvus 社区
github.com/milvus-io/milvus | 源码
milvus.io | 官网
milvusio.slack.com | Slack 社区
zhihu.com/org/zilliz-11/columns | 知乎
zilliz.blog.csdn.net | CSDN 博客
space.bilibili.com/478166626 | Bilibili

最后
以上就是动听乌龟最近收集整理的关于Milvus 查询合并机制的全部内容,更多相关Milvus内容请搜索靠谱客的其他文章。








发表评论 取消回复