Keras实现NNLM神经网络语言模型
- 一、NNML的效果
- 二、一些问题
- 三、实现代码及解释
- 四、最终效果
一、NNML的效果
较为权威的说法为:输入词序列,求出输出值的概率值,表示根据输入预测出下一个词概率。
简单的说:预测下一个词
实现效果:感觉与索引差不多,唯一不同可能是词向量的存在即索引该词的概率
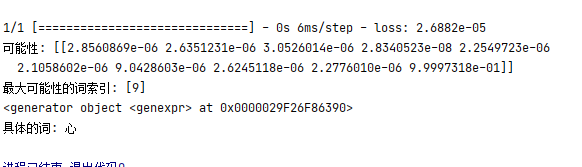
二、一些问题
参照的文章为金多:《神经网络语言模型 NNLM (Keras实现)》链接: 神经网络语言模型 NNLM (Keras实现).
总裁余(余登武):《NNLM语言模型python实现(例子:基于中文语料)》链接: NNLM语言模型python实现(例子:基于中文语料).
第一篇文章语料是英文的,而且代码第44行后的一段有些繁琐,看的头疼;而第二篇文章没有使用keras文本预处理方法。所以我试图综合这两篇文章,利用keras文本预处理方法实现nnlm。在这一过程的发现之前学习中有些细节没有掌握,所以记录一下。
1、原本以为embedding中使用的是one-hot即如[[0,0,0,0,01],[0,0,0,1,0]这种张量形式。但是在跑代码过程种,发现one-hot似乎不能嵌入embedding,embedding只能嵌入索引即sequences这种字典索引结构的方式
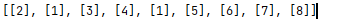
或许这就是词嵌入。
2、tokenizer 的作用
tokenizer = Tokenizer()
tokenizer.fit_on_texts(words)
无论是希望获得one-hot编码还是sequence都必须经过这一步,
因为token是分词,必须要有字典,才能形成sequence序列,one-hot也可以直接得到,通过
from keras.preprocessing.text import one_hot
也可以,但是还是要指定词汇表的大小,所以经过tokenizer是必须的,除非数据很少可以直接数出来如我当前的这段话sentences = [ “我爱你”, “李爱国”, “范冰心”],这样就可以不用tokenizer,因为可以手动分词
3、喂入数据的格式
上述那篇使用embedding的数据是生成器格式的,由于数据极少,之前试图整个喂入,但是一致报数据格式的问题,之后才发现embedding数据格式需要为2D张量,如果整个喂入就会变成3D张量,如果整个以2D张量形式喂入又会和embedding格式不一致;除非向第二篇博客一样使用dense全连接层。
4、句子的预处理
英文会以空格隔开,而tokenizer的分词也会如此,因而形如[ “我爱你”, “李爱国”, “范冰心”]在字典处理时需要拆成一个一个的字,
但在预测是标签y=你、国、心,x= “我爱”, “李爱”, "范冰,
即分词时
words = [word for words in sentences for word in list(words)]
tokenizer.fit_on_texts(words)
文本向量化时
for sentence in sentences:
inputs = [[tokenizer.word_index[n] for n in sentence[:-1]]]
targets = tokenizer.word_index[sentence[-1]]
三、实现代码及解释
# -*- coding: utf-8 -*-
# Author: cao wang
# Datetime : 2020
# software: PyCharm
# 收获:emebedding使用的是字典索引输入,用one-hot不能用emebedding;x,y为一句号中的上下文,分词必须在形成字典后
from keras.models import Sequential
from keras.layers import Dense, Embedding, LSTM
from keras.utils import np_utils
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer
import numpy as np
#文本
sentences = [ "我爱你", "李爱国", "范冰心"]
#分词实例化
tokenizer = Tokenizer()
"""此处意在按照字来构造字典,否者就会按照以上三个字组成的词构造句子如:{'我爱你': 1, '李爱国': 2, '范冰心': 3}"""
words = [word for words in sentences for word in list(words)]
tokenizer.fit_on_texts(words)
print(tokenizer.word_index)
#输出为分词后的字典{'爱': 1, '我': 2, '你': 3, '李': 4, '国': 5, '范': 6, '冰': 7, '心': 8}
#变成字典的索引,数字化
sequences = tokenizer.texts_to_sequences(words)
print(sequences)
#输出为:[[2], [1], [3], [4], [1], [5], [6], [7], [8]]
word_length = 4#字长度,可以自行设置
dict_length = len(tokenizer.word_index)+1#字典长度
#将[ "我爱你", "李爱国", "范冰心"],变成inputs_sequence为我爱(注此处最终要变成索引)
def generate_data(sentences, word_length, dict_length):
for sentence in sentences:
#索引化,与之前不同在于分为x,y,之前是一个一个的字
inputs = [[tokenizer.word_index[n] for n in sentence[:-1]]]
targets = tokenizer.word_index[sentence[-1]]
#y向量化,x进行裁剪
y = np_utils.to_categorical([targets], dict_length)
inputs_sequence = sequence.pad_sequences(inputs, maxlen=word_length)
yield (inputs_sequence, y)
#模型
model = Sequential()
model.add(Embedding(dict_length, 128, input_length=word_length))
model.add(LSTM(128, return_sequences=False))
model.add(Dense(dict_length, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adadelta')
for x, y in generate_data(sentences, word_length, dict_length):
model.fit(x, y,epochs=1000)
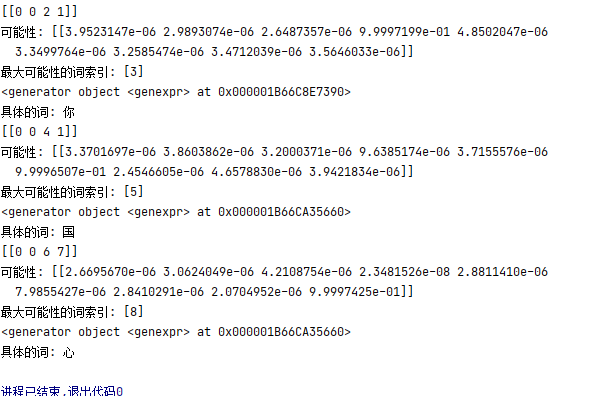
predict=model.predict(x)
print("可能性:",predict)
predict=np.argmax(predict,1)#求取最大值索引
print("最大可能性的词索引:",predict)
print(sen[:2] for sen in sentences)
"""为了后面的反向索引预测的字,因为输出的是字典索引,要输出字就是反向找键"""
number_dict = {str(w): i for i, w in tokenizer.word_index.items()}
print("具体的词:",number_dict[str(predict[0])])
四、最终效果
最后
以上就是柔弱滑板最近收集整理的关于Keras实现NNLM神经网络语言模型一、NNML的效果二、一些问题三、实现代码及解释四、最终效果的全部内容,更多相关Keras实现NNLM神经网络语言模型一、NNML内容请搜索靠谱客的其他文章。








发表评论 取消回复