不一样的获取数据方式——爬虫学习(1)
不一样的获取数据方式——爬虫学习(2)
不一样的获取数据方式——爬虫学习(3)
之前讲的所有内容基本都是围绕着requests这个库来处理的,很多网站都具有加密机制,所以在使用request获取到数据之后还得解密才能拿到真正的数据,这个过程过于麻烦。所以便有了selenium这个库。selenium原本是自动化测试工具,可以打开浏览器然后像人一样操作浏览器并直接提取网页上的各种信息。使用selenium连接浏览器,先等浏览器把所有东西解密后再直接接收最终的结果。
目录
- 1 环境搭建
- 2 selenium基本操作
- 2.1 打开浏览器
- 2.2 寻找网页中的元素并触发相应的事件
- 2.3 在输入框输入文字并回车
- 2.4 切换窗口
- 2.5 处理iframe
- 2.6 处理下拉列表
- 2.7 不弹出浏览器窗口
- 2.8 获取Elements中的源代码
- 3 被识别出使用selenium解决方法
1 环境搭建
- 下载selenium第三方库:pip install selenium
- 下载浏览器驱动:如果是谷歌浏览器可以点击此处下载。下载前要先确定当前使用的浏览器是什么版本的。下载之后把解压缩后的文件移动到python解释器所在的文件夹,如果不知道在哪就先用pycharm随便运行一个程序,控制台的第一行就是python解释器的位置。
2 selenium基本操作
2.1 打开浏览器
- 首先使用selenium需要先把包导进去:from selenium.webdriver import 浏览器名字。如果是谷歌浏览器就是Chrome;火狐浏览器就是Firefox,依此类推
- 导入的包其实是每个浏览器对应的类,只需要创建这个类的对象就相当于模拟了一个对浏览器的操作
- 创建完对象之后只需要调用 get(url字符串) 方法便可自动打开一个浏览器
from selenium.webdriver import Chrome # 用什么浏览器就导入对应名字的类
web = Chrome() # 创建一个操作浏览器的对象
web.get("https://baidu.com") # 打开指定的网站

打开之后发现浏览器提示正在受到自动测试软件的控制就说明成功了
2.2 寻找网页中的元素并触发相应的事件
有的网页打开可能会让你点击某个选项,或者需要在输入框内打字,这个时候就需要找到对应的元素然后触发相应的事件
-
寻找元素:可以调用浏览器对象的find_element一系列的方法,只需要根据开发调试工具找到对应元素的一些特征就可以定位。一般使用xpath来定位是最方便的
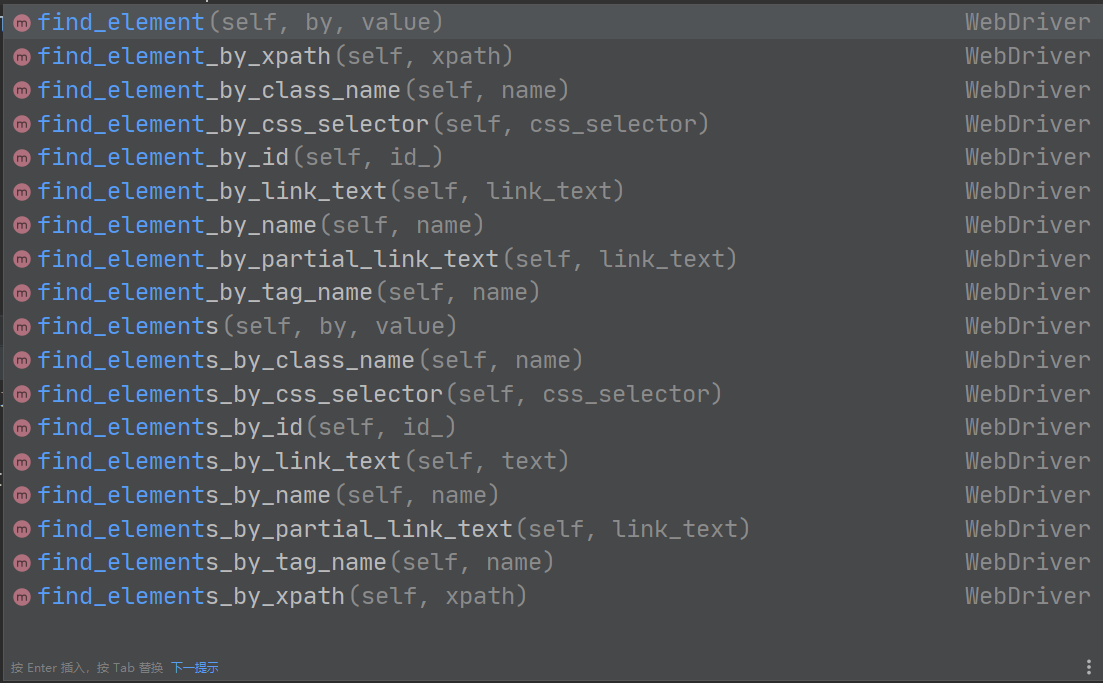
-
触发事件:找到对应的元素之后就可以调用一些方法触发事件,例如我们找到的元素是一个按钮就可以触发点击事件click()
from selenium.webdriver import Chrome # 用什么浏览器就导入对应名字的类
web = Chrome() # 创建一个操作浏览器的对象
web.get("https://lagou.com") # 打开指定的网站
el = web.find_element_by_xpath('//*[@id="changeCityBox"]/p[1]/a') # 根据xpath找元素
el.click() # 触发点击事件
2.3 在输入框输入文字并回车
和上一个内容一样,也是找到对应输入框元素然后调用对应的方法输入内容。
调用的方法是 send_keys(输入内容, 键盘指令) 这个函数的重点是第二个参数,比如说想要实现在一个搜索框内输入内容后按下回车键进行搜索,那么回车的这个动作是一个键盘上的指令,想要模拟这个过程就要再导入一个包 from selenium.webdriver.common.keys import Keys,这个包里就包含了很多键盘上会用到的按键的指令编码,使用的时候直接输入Keys.ENTER就代表了回车
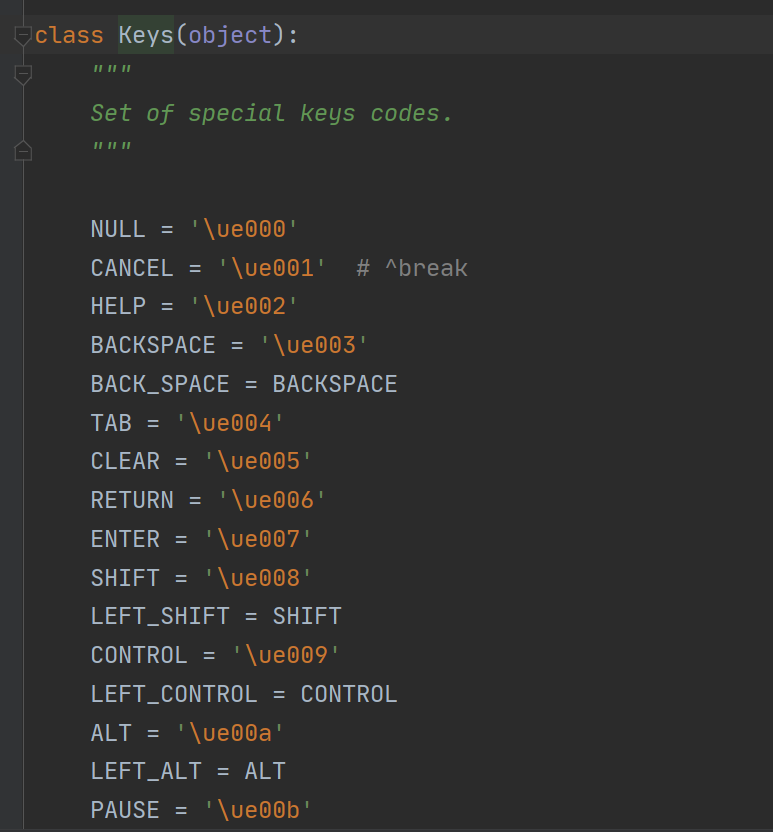
查看Keys的源代码可以看到平时会用到的按键基本都有对应的编码
from selenium.webdriver import Chrome # 用什么浏览器就导入对应名字的类
from selenium.webdriver.common.keys import Keys # 记录每个键盘按键的编码
import time
web = Chrome() # 创建一个操作浏览器的对象
web.get("https://lagou.com") # 打开指定的网站
el = web.find_element_by_xpath('//*[@id="changeCityBox"]/p[1]/a') # 根据xpath找元素
el.click() # 触发点击事件
time.sleep(1) # 防止浏览器加载没有程序执行快而报错
web.find_element_by_xpath('//*[@id="search_input"]').send_keys("python", Keys.ENTER) # 在输入框输入内容并回车
time.sleep(1)
# 开始爬取想要的内容
li_list = web.find_elements_by_xpath('//*[@id="s_position_list"]/ul/li')
for li in li_list:
name = li.find_element_by_tag_name('h3').text # 根据标签名找数据
price = li.find_element_by_xpath("./div/div/div[2]/div/span").text # 根据xpath找数据
company = li.find_element_by_xpath("./div/div[2]/div/a").text
print(company, name, price)
通过实际运行这个代码就会发现一个问题,selenium运行的速度非常慢,这就会存在一个很大的问题,如果按顺序执行多个操作的话页面可能会刷新,有的内容可能需要重新加载,而加载的速度可能太慢而导致你的程序已经在执行下一个操作了而浏览器的内容还没有加载出来从而报错。所以为了防止出现这种情况最好使用time.sleep()让程序暂停几秒然后再接着执行下一个指令
2.4 切换窗口
有时候点击网页上的某个链接不是加载对应的新内容而是跳出一个新的窗口出来。在selenium中新窗口默认是不会自动切换的,如果要实现切换窗口就可以使用方法 switch_to.window()
from selenium.webdriver import Chrome # 用什么浏览器就导入对应名字的类
from selenium.webdriver.common.keys import Keys # 记录每个键盘按键的编码
import time
web = Chrome() # 创建一个操作浏览器的对象
web.get("https://lagou.com") # 打开指定的网站
el = web.find_element_by_xpath('//*[@id="changeCityBox"]/p[1]/a') # 根据xpath找元素
el.click() # 触发点击事件
time.sleep(1) # 防止浏览器加载没有程序执行快而报错
web.find_element_by_xpath('//*[@id="search_input"]').send_keys("python", Keys.ENTER) # 在输入框输入内容并回车
time.sleep(1)
# 打开新窗口
web.find_element_by_xpath('//*[@id="s_position_list"]/ul/li[1]/div[1]/div[1]/div[1]/a/h3').click()
web.switch_to.window(web.window_handles[-1]) # 切换到最后一个窗口
web.close() # 关闭当前窗口
web.switch_to.window(web.window_handles[0]) # 返回第一个窗口
在该代码中选择跳转到哪个窗口使用的是window_handles,里面存了每一个窗口的信息,想要跳转到第几个窗口就输入几
如果要关闭当前的窗口则调用close()方法,虽然能够关闭但不会自动跳回到原来的窗口,还是得再变更selenium视角进行一次窗口切换回到原来的页面
2.5 处理iframe
基本的流程是:
- 找到iframe标签:正常寻找元素的方法一样,调用find_element系列的方法即可
- 切换视角进入iframe:和切换窗口类似,调用 switch_to.frame(找到的iframe) 即可
- 拿数据:正常根据元素找数据即可
- 返回原页面:调用 switch_to.default_content() 即可返回原页面
iframe = web.find_element_by_xpath('//*[@id“”player_ifram]')
web.switch_to.frame(iframe)
tx = web.find_element_by_xpath('//*[@id="mian]/h3[1]').text
print(tx)
web.switch_to.default_content()
2.6 处理下拉列表
-
首先要导入一个包 from selenium.webdriver.support.select import Select ,这个包是用来处理下拉列表Select的类
-
先找到下拉列表的标签所在位置,把这个标签元素作为参数创建一个Select类的对象
-
由于下拉列表中有多个选项,选择不同选项可以通过下标顺序、value属性值、文本值来选择,一般可以通过一个循环根据下标顺序遍历所有选项

-
选择某个选项之后页面会重新加载,然后再根据新的内容获取数据即可
import time
from selenium.webdriver import Chrome
from selenium.webdriver.support.select import Select
web = Chrome()
web.get("https://www.endata.com.cn/BoxOffice/BO/Year/index.html")
sel_el = web.find_element_by_xpath('//*[@id="OptionDate"]') # 找到下拉列表的标签元素
sel = Select(sel_el) # 创建下拉列表对象
for i in range(len(sel.options)):
sel.select_by_index(i) # 根据下标顺序选择对应的选项
time.sleep(2) # 防止重新加载过慢而报错
# 获取数据
table = web.find_element_by_xpath('//*[@id="TableList"]/table')
print(table.text)
2.7 不弹出浏览器窗口
不弹出浏览器窗口就是让它载后台运行,不显示出浏览器画面,这个操作也叫做无头浏览器
具体的操作就是在创建浏览器对象的时候进行参数配置
- 首先导入一个包 from selenium.webdriver.chrome.options import Options ,通过这个类可以添加一些浏览器的配置参数
- 创建Option对象,往里面添加 “–headless” 和 ***"–disbale-gpu"***这两个参数
- 将Option对象作为参数,在创建浏览器对象的时候传递进去即可
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
opt = Options() # 创建配置对象
# 添加配置参数
opt.add_argument("--headless")
opt.add_argument("--disbale-gpu")
web = Chrome(options=opt) # 在创建浏览器对象的时候加入配置参数
2.8 获取Elements中的源代码
有的网站直接查看页面源代码,很多信息是不会显示出来的,而开发调试工具中的Elements却能显示出来,这是js等运行完之后的包含所有信息的代码,如果想能够获取到这个源代码的话对于爬虫也能方便很多。要实现这个就可以调用selenium中浏览器对象的 page_source() 方法即可
web = Chrome(options=opt) # 在创建浏览器对象的时候加入配置参数
web.get("https://www.endata.com.cn/BoxOffice/BO/Year/index.html")
print(web.page_source)
3 被识别出使用selenium解决方法
服务器识别当前是否是用selenium程序在访问的最简单方法就是通过webdriver,打开开发调试工具的Console,输入window.navigator.webdriver,如果是正常使用浏览器的话会返回false,如果是用selenium打开的话会返回true。所以一般遇到被拦截的情况就要考虑是不是这个问题。
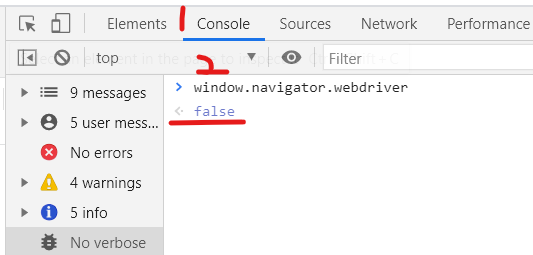
- 如果谷歌浏览器的版本小于88:在启动浏览器的时候(此时没有加载任何网页内容),向页面嵌入js代码去掉webdriver
web = Chrome() # 创建浏览器对象
# 先嵌入js代码去掉webdriver
web.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
window.navigator.webdriver = undefined
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
# 之后便可以正常执行操作
web.get(xxxxxx)
- 如果谷歌浏览器的版本大于88:直接添加一个浏览器配置即可
opt = Options() # 创建配置对象
opt.add_argument("--disable-blink-features=AutomationControlled") # 添加配置参数
web = Chrome(options=opt) # 在创建浏览器对象的时候加入配置参数
# 之后便可以正常执行操作
web.get(xxxxx)
最后
以上就是开朗皮带最近收集整理的关于不一样的获取数据方式——爬虫学习(4)1 环境搭建2 selenium基本操作3 被识别出使用selenium解决方法的全部内容,更多相关不一样的获取数据方式——爬虫学习(4)1内容请搜索靠谱客的其他文章。








发表评论 取消回复