通过对华盛顿的部分自行车租赁情况数据进行分析,对测试集的自行车租赁数目进行预测。
导入数据
train = read.csv("train.csv")
test = read.csv("test.csv")str(train)
str(test)分别对两组数据进行概览,可以发现数据集存在以下特征:
$ datetime : 日期
$ season : 季节,1—4分别代表春夏秋冬
$ holiday : 是否是假期,0代表否,1代表是(注意,假期区别于周末,类似于节假日,如圣诞节)
$ workingday: 是否是工作日,0代表否,1代表是
$ weather : 天气情况,可以理解为从1—4分别代表天气越来越恶劣的情况
$ temp : 温度
$ atemp : 体感温度
$ humidity : 湿度
$ windspeed : 风速情况
$ casual : 非注册用户数
$ registered: 注册用户数
$ count : 总用户数
其中test数据集缺少后三项,即需要预测的是非注册和注册用户总数。
数据预处理
对数据集中的时间进行处理,提取出新特征。此处用用lubridate包处理时间(很实用,学习了)。
library(lubridate)
library(dplyr)
library(fasttime)train$hour = hour(train$datetime)
train$wday = wday(train$datetime)
test$hour = hour(test$datetime)
test$wday = wday(test$datetime)
train$hour = factor(train$hour)
train$wday = factor(train$wday)
test$hour = factor(test$hour)
test$wday = factor(test$wday)
这样就给train和test集分别添加了两列,hour表示当时为一天中的24小时制的几点,wday则表示星期几,并将其转换为因子。
library(mice)
md.pattern(train)
md.pattern(test)检查缺失值,发现数据集不存在缺失值。
探索性分析
分别作出非注册用户和注册用户与时间和星期几的箱线图。
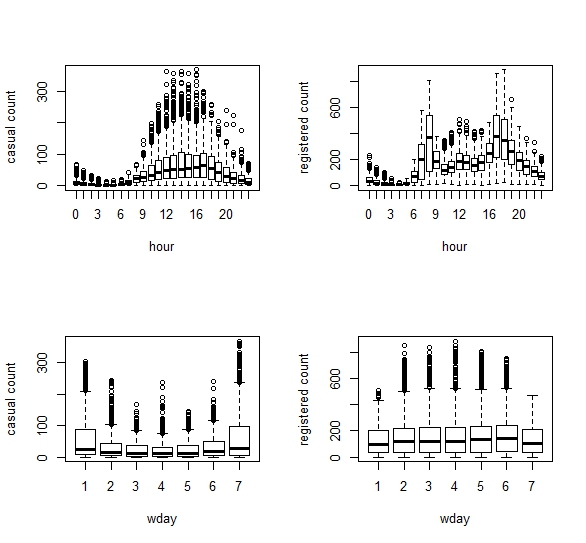
可以看出非注册用户使用自行车的时间主要集中于白天,且在下午时达到顶峰;注册用户使用自行车的时间高峰主要集中于上下班的时间。同时可以看到非注册用户在周末使用自行车比工作日要多,注册用户在一周内使用自行车的频数都较高。
train_data = train[,c(6,7,8,9,10,11,12)]
cor(train_data)作出温度、湿度等数值变量与用户数的相关系数矩阵
temp atemp humidity windspeed casual registered count
temp 1.00000000 0.98494811 -0.06494877 -0.01785201 0.46709706 0.31857128 0.3944536
atemp 0.98494811 1.00000000 -0.04353571 -0.05747300 0.46206654 0.31463539 0.3897844
humidity -0.06494877 -0.04353571 1.00000000 -0.31860699 -0.34818690 -0.26545787 -0.3173715
windspeed -0.01785201 -0.05747300 -0.31860699 1.00000000 0.09227619 0.09105166 0.1013695
casual 0.46709706 0.46206654 -0.34818690 0.09227619 1.00000000 0.49724969 0.6904136
registered 0.31857128 0.31463539 -0.26545787 0.09105166 0.49724969 1.00000000 0.9709481
count 0.39445364 0.38978444 -0.31737148 0.10136947 0.69041357 0.97094811 1.0000000
根据结果,温度(含体感温度)与使用人数呈正相关,说明人们偏好于在温暖的天气骑车;湿度与用户数负相关,说明雾天、下雨等天气会造成使用人数下降;风速对用户数影响较小。
建立模型
注意要将部分变量变为因子类变量,如天气、季节、是否是假期等。
for (i in 2:5) {
train[,i] = factor(train[,i])
test[,i] = factor(test[,i])
}为test数据集添加非注册用户数和注册用户数两列
test$casual = rep(1,6493)
test$registered = rep(1,6493)注意由于结果判定是采用RMSLE方法,需要将用户人数进行对数化计算。
for (i in 10:11) {
train[,i] = log(train[,i])
}rf_cas = randomForest(casual~season + holiday + workingday + weather + temp + atemp + humidity + windspeed+hour+wday,data = train)
rf_reg = randomForest(registered~season + holiday + workingday + weather + temp + atemp + humidity + windspeed+hour+wday,data = train)分别对非注册用户和注册用户建立随机森林模型。
分别作出对非注册用户和注册用户建立的预测模型的变量重要性的直方图。
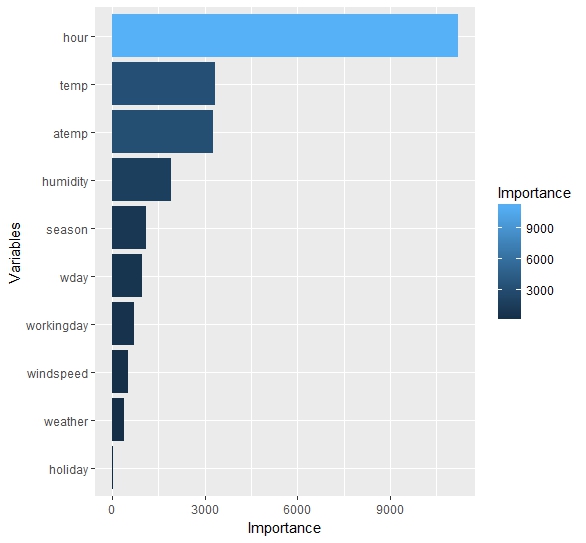
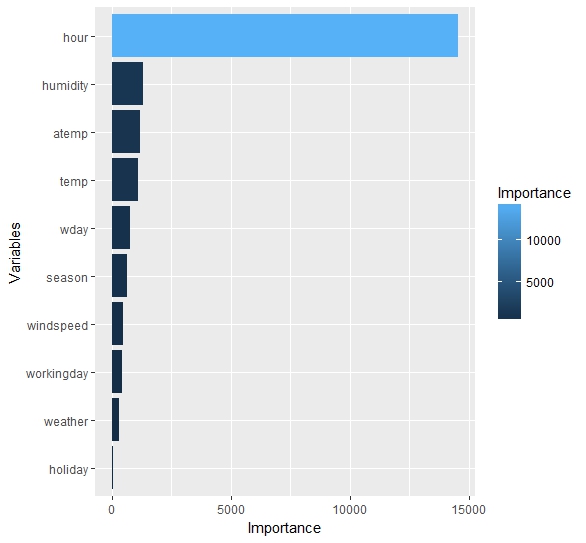
可以看出,对于两种用户来说,处于一天中的几点是最重要的决定性因素。对于非注册用户,温度的影响较大;而对于注册用户,温度的影响不及湿度。对于两种用户,是否是假期的影响都是最小的。
计算出测试集的结果,写入csv。
pred_cas = predict(object = rf_cas,newdata = test)
pred_reg = predict(object = rf_reg,newdata = test)
test$count = (exp(pred_cas)-1) + (exp(pred_reg)-1)
submit = data.frame(datetime = test$datetime,count = test$count)
write.csv(submit,file = "submit.csv",row.names = F)
得分为0.45472,得分还是比较高的。
最后
以上就是怕黑热狗最近收集整理的关于Bike Sharing 案例的全部内容,更多相关Bike内容请搜索靠谱客的其他文章。








发表评论 取消回复