一、什么是BSP模型
-
概述
BSP(Bulk Synchronous Parallel,整体同步并行计算模型)是一种并行计算模型,由英国计算机科学家Viliant在上世纪80年代提出。Google发布的一篇论文(《Pregel: A System for Large-Scale Graph Processing》)使得这一概念被更多人所认识,据说在Google 80%的程序运行在MapReduce上,20%的程序运行在Pregel上。和MapReduce一样,Google并没有开源Pregel,Apache按Pregel的思想提供了类似框架Hama。
-
并行计算模型介绍
并行计算模型通常指从并行算法的设计和分析出发,将各种并行计算机(至少某一类并行计算机)的基本特征抽象出来,形成一个抽象的计算模型。从更广的意义上说,并行计算模型为并行计算提供了硬件和软件界面,在该界面的约定下,并行系统硬件设计者和软件设计者可以开发对并行性的支持机制,从而提高系统的性能。
常用的并行计算模型有:PRAM模型、LogP模型、BSP模型、C3模型、BDM模型。
二、BSP模型基本原理
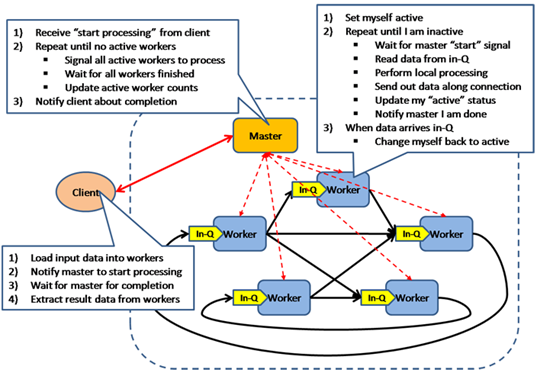
BSP模型是一种异步MIMD-DM模型(DM: distributed memory,SM: shared memory),BSP模型支持消息传递系统,块内异步并行,块间显式同步,该模型基于一个master协调,所有的worker同步(lock-step)执行, 数据从输入的队列中读取,该模型的架构如图所示:
另外,BSP并行计算模型可以用 p/s/g/I 4个参数进行描述:
-
P为处理器的数目(带有存储器)。
-
s为处理器的计算速度。
-
g为每秒本地计算操作的数目/通信网络每秒传送的字节数,称之为选路器吞吐率,视为带宽因子 (time steps/packet)=1/bandwidth。
-
i为全局的同步时间开销,称之为全局同步之间的时间间隔 (Barrier synchronization time)。
那么假设有p台处理器同时传送h个字节信息,则gh就是通信的开销。同步和通信的开销都规格化为处理器的指定条数。
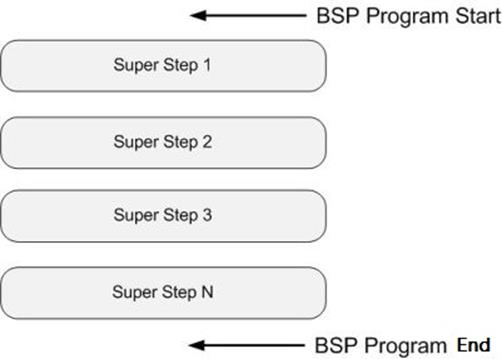
BSP计算模型不仅是一种体系结构模型,也是设计并行程序的一种方法。BSP程序设计准则是整体同步(bulk synchrony),其独特之处在于超步(superstep)概念的引入。一个BSP程序同时具有水平和垂直两个方面的结构。从垂直上看,一个BSP程序由一系列串行的超步(superstep)组成,如图所示:
这种结构类似于一个串行程序结构。从水平上看,在一个超步中,所有的进程并行执行局部计算。一个超步可分为三个阶段,如图所示:
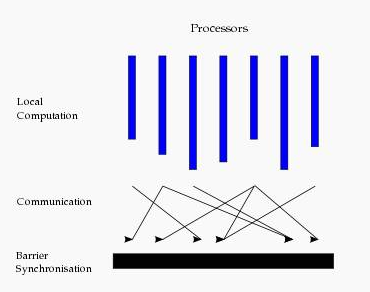
-
本地计算阶段,每个处理器只对存储本地内存中的数据进行本地计算。
-
全局通信阶段,对任何非本地数据进行操作。
-
栅栏同步阶段,等待所有通信行为的结束。
-
三、BSP模型特点
1. BSP模型将计算划分为一个一个的超步(superstep),有效避免死锁。
2. 它将处理器和路由器分开,强调了计算任务和通信任务的分开,而路由器仅仅完成点到点的消息传递,不提供组合、复制和广播等功能,这样做既掩盖具体的互连网络拓扑,又简化了通信协议;
3. 采用障碍同步的方式以硬件实现的全局同步是在可控的粗粒度级,从而提供了执行紧耦合同步式并行算法的有效方式,而程序员并无过分的负担;
4. 在分析BSP模型的性能时,假定局部操作可以在一个时间步内完成,而在每一个超级步中,一个处理器至多发送或接收h条消息(称为h-relation)。假定s是传输建立时间,所以传送h条消息的时间为gh+s,如果 ,则L至少应该大于等于gh。很清楚,硬件可以将L设置尽量小(例如使用流水线或大的通信带宽使g尽量小),而软件可以设置L的上限(因为L越大,并行粒度越大)。在实际使用中,g可以定义为每秒处理器所能完成的局部计算数目与每秒路由器所能传输的数据量之比。如果能够合适的平衡计算和通信,则BSP模型在可编程性方面具有主要的优点,而直接在BSP模型上执行算法(不是自动的编译它们),这个优点将随着g的增加而更加明显;
5. 为PRAM模型所设计的算法,都可以采用在每个BSP处理器上模拟一些PRAM处理器的方法来实现。
四、BSP模型的评价
1. 在并行计算时,Valiant试图也为软件和硬件之间架起一座类似于冯·诺伊曼机的桥梁,它论证了BSP模型可以起到这样的作用,正是因为如此,BSP模型也常叫做桥模型。
2. 一般而言,分布存储的MIMD模型的可编程性比较差,但在BSP模型中,如果计算和通信可以合适的平衡(例如g=1),则它在可编程方面呈现出主要的优点。
3. 在BSP模型上,曾直接实现了一些重要的算法(如矩阵乘、并行前序运算、FFT和排序等),他们均避免了自动存储管理的额外开销。
4. BSP模型可以有效的在超立方体网络和光交叉开关互连技术上实现,显示出,该模型与特定的技术实现无关,只要路由器有一定的通信吞吐率。
5. 在BSP模型中,超级步的长度必须能够充分的适应任意的h-relation,这一点是人们最不喜欢的。
6. 在BSP模型中,在超级步开始发送的消息,即使网络延迟时间比超级步的长度短,该消息也只能在下一个超级步才能被使用。
7. BSP模型中的全局障碍同步假定是用特殊的硬件支持的,但很多并行机中可能没有相应的硬件。
五、BSP与MapReduce对比
执行机制:MapReduce是一个数据流模型,每个任务只是对输入数据进行处理,产生的输出数据作为另一个任务的输入数据,并行任务之间独立地进行,串行任务之间以磁盘和数据复制作为交换介质和接口。
BSP是一个状态模型,各个子任务在本地的子图数据上进行计算、通信、修改图的状态等操作,并行任务之间通过消息通信交流中间计算结果,不需要像MapReduce那样对全体数据进行复制。
迭代处理:MapReduce模型理论上需要连续启动若干作业才可以完成图的迭代处理,相邻作业之间通过分布式文件系统交换全部数据。BSP模型仅启动一个作业,利用多个超步就可以完成迭代处理,两次迭代之间通过消息传递中间计算结果。由于减少了作业启动、调度开销和磁盘存取开销,BSP模型的迭代执行效率较高。
数据分割:基于BSP的图处理模型,需要对加载后的图数据进行一次再分布的过程,以确定消息通信时的路由地址。例如,各任务并行加载数据过程中,根据一定的映射策略,将读入的数据重新分发到对应的计算任务上(通常是放在内存中),既有磁盘I/O又有网络通信,开销很大。但是一个BSP作业仅需一次数据分割,在之后的迭代计算过程中除了消息通信之外,不再需要进行数据的迁移。而基于MapReduce的图处理模型,一般情况下,不需要专门的数据分割处理。但是Map阶段和Reduce阶段存在中间结果的Shuffle过程,增加了磁盘I/O和网络通信开销。
MapReduce的设计初衷:解决大规模、非实时数据处理问题。"大规模"决定数据有局部性特性可利用(从而可以划分)、可以批处理;"非实时"代表响应时间可以较长,有充分的时间执行程序。而BSP模型在实时处理有优异的表现。这是两者最大的一个区别。
六、BSP模型的实现
1.Pregel
Google的大规模图计算框架,首次提出了将BSP模型应用于图计算,具体请看Pregel——大规模图处理系统,不过至今未开源。
http://blog.csdn.net/strongwangjiawei/article/details/8120318
2.Apache Giraph
ASF社区的Incubator项目,由Yahoo!贡献,是BSP的java实现,专注于迭代图计算(如pagerank,最短连接等),每一个job就是一个没有reducer过程的hadoop job。http://giraph.apache.org/
3.Apache Hama
也是ASF社区的Incubator项目,与Giraph不同的是它是一个纯粹的BSP模型的java实现,并且不单单是用于图计算,意在提供一个通用的BSP模型的应用框架。http://hama.apache.org/
4.GraphLab
CMU的一个迭代图计算框架,C++实现的一个BSP模型应用框架,不过对BSP模型做了一定的修改,比如每一个超步之后并不设置全局同步点,计算可以完全异步进行,加快了任务的完成时间。http://graphlab.org/
5.Spark
加州大学伯克利分校实现的一个专注于迭代计算的应用框架,用Scala语言写就,提出了RDD(弹性分布式数据集)的概念,每一步的计算数据都从上一步结果精简而来,大大降低了网络传输,同时保证了血统的纯正性(即出错只需返回上一步即可),增强了容错功能。Spark论文里也基于此框架实现了BSP模型(叫Bagel)。值得一提的是国内的豆瓣也基于该思想用Python实现了这样一个框架叫Dpark,并且已经开源。https://github.com/douban/dpark
6.Trinity
这是微软的一个图计算平台,C#开发的,它是为了提供一个专用的图计算应用平台,包括底层的存储到上层的应用,应该是可以实现BSP模型的,文章发在SIGMOD13上,可恨的是也不开源。
主页http://research.microsoft.com/en-us/projects/trinity/
以下几个也是一些BSP的实现,不过关注度不是很高,基本都是对Pregel的开源实现:
7.GoldenOrb
另一个BSP模型的java实现,是对Pregel的一个开源实现,应用在hadoop上。
官网:http://www.goldenorbos.org/(要FQ)
源码:https://github.com/jzachr/goldenorb
8.Phoebus
Erlang语言实现的BSP模型,也是对Pregel的一个开源实现。
https://github.com/xslogic/phoebus
9.Rubicon
Pregel的开源实现。https://launchpad.net/rubicon
10.Signal/Collect
也是一个Scala版的BSP模型实现。http://code.google.com/p/signal-collect/
11.PEGASUS
在hadoop上实现的一个java版的BSP模型,发表在SIGKDD2011上。
http://www.cs.cmu.edu/~pegasus/index.htm
七、Apache Hama简介
-
Hama概述
背景:
2008年5月Hama被视为Apache众多项目中一个被孵化的项目,作为Hadoop项目中的一个子项目,BSP模型是Hama计算的核心,并且实现了分布式的计算框架,采用这个框架可以用于矩阵计算(matrix)和面向图计算(graph)、网络计算(network)。
Hama是建立在Hadoop上的分布式并行计算模型。基于Map/Reduce 和 Bulk Synchronous的实现框架。运行环境需要关联Zookeeper、Hbase、HDFS组件。集群环境中的系统架构由BSPMaster/GroomServer(Computation Engine)、Zookeeper(Distributed Locking)、HDFS/Hbase(Storage Systems)这3大块组成。Hama中有2个主要的模型: 矩阵计算(Matrix package)和 面向图计算(Graph package)。
Hama的主要应用领域是:矩阵计算、面向图计算、PageRank、排序计算、BFS。
-
Hama Architecture
Hama系统架构
Apache的Hama主要由三个部分组成:BSPMaster,GroomServers和Zookeeper,下面这张图主要概述了Hama的整体系统架构,并且描述了系统模块之间的通讯与交互。Hama的集群中需要有HDFS的运行环境负责持久化存储数据(例如:job.jar),BSPMaster负责进行对Groom Server 进行任务调配,groom Server 负责进行对BSPPeers进行调用程序进行具体的调用,Zookeeper负责对Groom Server 进行失效转发。
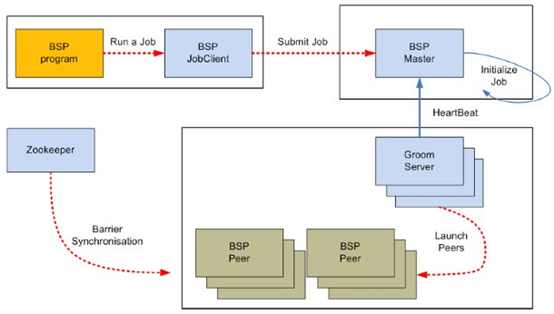
BSPMaster(划分计算到Groom,管理Groom,类似MapReduce的JobTracker)
在Apache Hama中BSPMaster模块是系统中的一个主要角色,他主要负责的是协同各个计算节点之间的工作,每一个计算节点在其注册到master上来的时候会分配到一个唯一的ID。Master内部维护着一个计算节点列表,表明当前哪些计算节点出于alive状态,该列表中就包括每个计算节点的ID和地址信息,以及哪些计算节点上被分配到了整个计算任务的哪一部分。Master中这些信息的数据结构大小取决于整个计算任务被分成多少个partition。因此,一台普通配置的BSPMaster足够用来协调对一个大型计算。
下面我们来看看BSPMaster做了哪些工作:
-
- 维护着Groom服务器的状态。
- 控制在集群环境中的superstep。
- 维护在groom中job的工作状态信息。
- 分配任务、调度任务到所有的groom服务器节点。
- 广播所有的groom服务器执行。
- 管理系统节点中的失效转发。
- 提供用户对集群环境的管理界面。
一个BSPMaster或者多个grooms服务器是通过脚本启动的,在Groom服务器中还包含了BSPeer的实例,在启动GroomServer的时候就会启动了BSPPeer,BSPPeer是整合在GrommServer中的,GrommServer通过PRC代理与BSPmaster连接。当BSPmaster、GroomServer启动完毕以后,每个GroomServer的生命周期通过发送"心跳"信息给BSPmaster服务器,在这个"心跳"信息中包含了GrommServer服务器的状态,这些状态包含了能够处理任务的最大容量,和可用的系统内存状态,等等。
BSPMaster的绝大部分工作,如input ,output,computation,saving以及resuming from checkpoint,都将会在一个叫做barrier的地方终止。Master会在每一次操作都会发送相同的指令到所有的计算节点,然后等待从每个计算节点的回应(response)。每一次的BSP主机接收心跳消息以后,这个信息会带来了最新的groom服务器状态,BSPMaster服务器对给出一个回应的信息,BSPMaster服务器将会与groom 服务器进行确定活动的groom server空闲状态,也就是groom 服务器可资源并且对其进行任务调度和任务分配。BSPMaster与Groom Server两者之间通讯使用非常简单的FIFO(先进先出)原则对计算的任务进行分配、调度。
GroomServer
一个Groom服务器对应一个处理BSPMaster分配的任务,每个groom都需要与BSPMaster进行通讯,处理任务并且想BSPMaster处理报告状态,集群状态下的Groom Server需要运行在HDFS分布式存储环境中,而且对于Groom Server来说一个groom 服务器对应一个BSPPeer节点,需要运行在同一个物理节点上。
Zookeeper
在Apache HaMa项目中zookeeper是用来有效的管理BSPPeer节点之间的同步间隔(barrier synchronization),同时在系统失效转发的功能上发挥了重要的作用。
-
-
Apache Hama作业流程
-
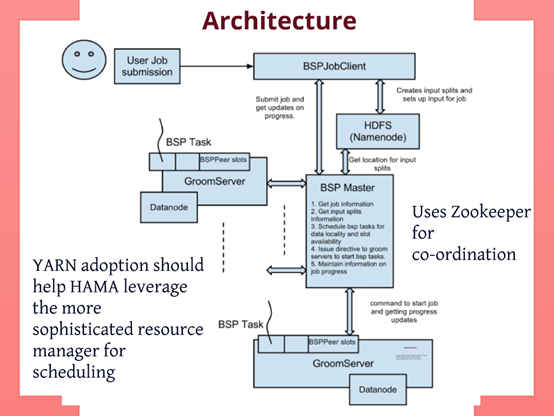
-
一个新的job被提交后,BSPJobClient先做一些初始化Job的工作:准备好作业的输入资源、代码等。
-
BSPMaster将Job划分为一个个的task,将task分配给GroomServer去执行,执行过程中维护GroomServer的进度与状态。GroomServer发送心跳给BSPMaster来保持通信。超级步的控制是由BSPMaster完成的。
-
GroomServer启动BSPPeer,由BSPPeer来具体执行task。GroomServer主要任务是BSPPeer的启动和停止,维护任务的执行状态,向BSPMaster报告状态。一个GroomServer可运行多个task。类似于MapReduce的tasktracker的任务槽。所有的task有一个masterTask,masterTask在整个计算开始和结束时分别调用setup()和cleanup()。如果该GroomServer下的一个task失败,GroomServer会重新启动这个task,如果3次重启task都失败,则GroomServer向BSPMaster汇报该任务失败。
-
BSPeer在计算期间间的通信是P2P方式进行的,由zookeeper负责调度。在一个超步中BSPeer只能发消息或者处理上一个超步中接收到的消息。例:A发送消息给B—>栅栏—>本次超级步结束 下一个超级步开始—>B接收到A发送的消息—>……
另外,默认配置下Hama是将要发送的和接收到的消息都缓存在内存中,所以hama本身的同步通信功能不适合做大量数据传递,它只适合在同步计算过程中发送少量的消息。
-
在整个计算过程中,zookeeper负责栅栏同步,将来会用于容错机制。
-
Apache Hama与Google Pregel
Hama类似Google发明的Pregel,如果你听过Google Pregel这个利器的话,那么就对BSP计算模型不会陌生,Google的Pregel也是基于BSP模型,在Google的整个计算体系中有20%的计算是依赖于Pregel的计算模型,Google利用Pregel实现了图遍历(BFS)、最短路径(SSSP)、PageRank计算,我猜想 Google的Google Me 产品很有可能会大量采用Pregel的计算方式,用Pregel来绘制Google Me产品中SNS的关系图。
Google的Pregel是采用GFS或BigTable进行持久存储,Google的Pregel是一个Master-slave主从结构,有一个节点扮演master角色,其它节点通过name service定位该顶点并在第一次时进行注册,master负责对计算任务进行切分到各节点(也可以自己指定,考虑load balance等因素),根据顶ID哈希分配顶点到机器(一个机器可以有多个节点,通过name service进行逻辑区分),每个节点间异步传输消息,通过checkpoint机制实行容错(更高级的容错通过confined recovery实现),并且每个节点向master汇报心跳(ping)维持状态。
Hama是Apache中Hadoop的子项,所以Hama可以与Apache的HDFS进行完美的整合,利用HDFS对需要运行的任务和数据进行持久化存储,也可以在任何文件系统和数据库中。当然我们可以相信BSP模型的处理计算能力是相对没有极限的特别对于图计算来说,换句话说BSP模型就像MapReduce一样可以广泛的使用在任何一个分布式系统中,我们可以尝试的对实现使用Hama框架在分布式计算中得到更多的实践,比如:矩阵计算、排序计算、pagerank、BFS 等等。
-
Hama与MapReduce对比
MapReduce的不足:
1. MapReduce 主要针对松耦合型的数据处理应用, 对于不容易分解成众多相互独立子任务的紧耦合型计算任务, 处理效率很低。
2. MapReduce 不能显式的支持迭代计算。
3. MapReduce 是一种离线计算框架, 不适合进行流式计算和实时分析。
Hama的优势:
1. 在科学计算领域的适用性:Hama提供的基础组件能够适应多种需要矩阵和图形计算的应用。MapReduce在单纯的大规模科学计算方面存在不足。比如求一个大型矩阵的逆矩阵,需要进行大量的迭代计算,而读写文件的次数并不多。此时Hama的迭代速度快的优势便体现出来。
2. 兼容性:Hama能利用Hadoop和它相关的所有功能,因为Hama很好的兼容了现有Hadoop接口;
3. 可扩展性:得益于Hama的兼容性,Hama能够充分利用大规模分布式接口的基础功能和服务,比如亚马逊EC2可以无需任何修正就可以使用Hama;
4. 编程方式的灵活性:为了保证灵活性来支持不同的计算模式,Hama提供了简单计算引擎接口;任何遵循此接口的计算引擎都能自由接入和退出;
-
Hama亟待解决的问题
-
完善容错能力。
-
NoSQL的输入输出格式
-
无视同步(消除栅栏)
-
使用异步消息:现在消息是在超级步的后期进行传递,在超级步里消息异步发送会带来更多的并发设计。
-
Hama容错机制
BSPMaster出错:
【未解决】https://issues.apache.org/jira/browse/HAMA-509
GroomServer出错:
恢复GroomServer上的task。【未解决】https://issues.apache.org/jira/browse/HAMA-618
task出错:
当BSPMaster发现任务出错时,控制GroomServer恢复task。【已解决】https://issues.apache.org/jira/browse/HAMA-534
task会周期pingGroomServer,如果不能ping通则杀死自己,如果GroomServer长时间收不到某task的ping信息,则检查task是否正常运行。【已解决】https://issues.apache.org/jira/browse/HAMA-498
summarizes:
https://issues.apache.org/jira/browse/HAMA-505
-
Hama API
BSP
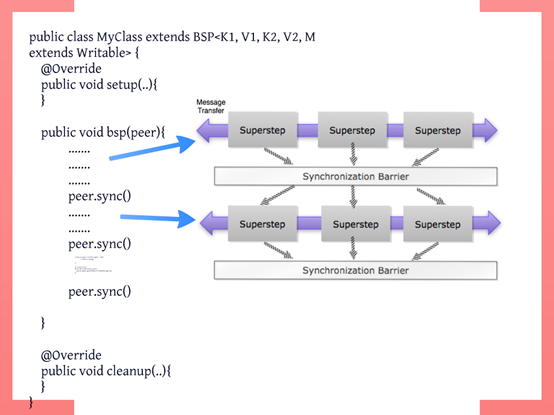
1.编写自己的BSP类需要继承org.apache.hama.bsp.BSP ,并且需要重写bsp()方法,bsp()方法的声明如下:
public abstract void bsp(BSPPeer<K1, V1, K2, V2, M extends Writable> peer) throws IOException, SyncException, InterruptedException;
2.按照我们自己的业务编写bsp()方法,该方法内包含一个或多个超步,栅栏同步接口是peer.sync();
3.进程间通信接口如下:

下面是一个发送接收消息的例子:

4.在我们自己的BSP类中还有setup()和cleanup()两个方法,分别在bsp()方法之前和之后执行,可以对这两个方法重写,完成一些需求。BSP类概要如下图:
Graph
1. hama提供了Graph包,支持顶点为中心的图计算,使用较少的代码就可以实现google Pregel风格的应用。
实现一个Hama Graph应用包括对预定义的Vertex类进行子类化,模板参数涉及3种类型,顶点、边和消息( vertices, edges, and messages ):
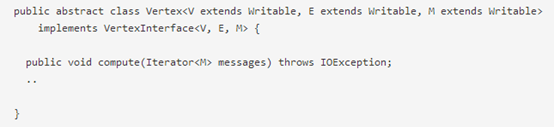
用户重写compute()方法,该方法将在每个超步的活跃顶点中执行。Compute()方法可以查询当前顶点及其边的信息,并向其他顶点发送消息。
2.通过继承 org.apache.hama.graph. VertexInputReader 类,根据自己的文件格式创建自己的 VertexReader,示例如下:

-
-
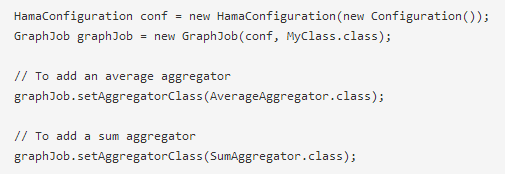
通过继承org.apache.hama.graph.AbstractAggregator类,可以编写自己的聚合器。聚合器用来做全局的通信、监控等。超步内所有的顶点都可以给聚合器一个值,聚合器整合所有点提供的值,在下一个超步每个顶点都可以使用聚合器整合后的值。在一个job里可以使用多个聚合器,只需要在创建job时注册一下即可,注册如下:
-
顶点使用聚合器是按聚合器注册时的顺序(0,1,2,3...)向聚合器发送数据,以及使用聚合器内的数据的api如下:
顶点提供值给聚合器:

顶点使用聚合器:

八、安装Hama
见文章:http://www.cnblogs.com/BYRans/p/4588276.html
九、编写Hama job
在eclipse下新建Java Project,将hama安装时需要的jar包全部导入工程。
官网中计算PI的例子:
(代码见官网文档)
将工程Export成Jar文件,发到集群上运行。运行命令:
$HAMA_HOME/bin/hama jar jarName.jar
输出:

Current supersteps number: 0()
Current supersteps number: 4()
The total number of supersteps: 4(总超级步数目)
Counters: 8(一共8个计数器)
SUPERSTEPS=4(BSPMaster超级步数目)
LAUNCHED_TASKS=3(共多少个task)
org.apache.hama.bsp.BSPPeerImpl$PeerCounter
SUPERSTEP_SUM=12(总共的超级步数目,task数目*BSPMaster超级步数目)
MESSAGE_BYTES_TRANSFERED=48(传输信息字节数)
TIME_IN_SYNC_MS=657(同步消耗时间)
TOTAL_MESSAGES_SENT=6(发送信息条数)
TOTAL_MESSAGES_RECEIVED=6(接收信息条数)
TASK_OUTPUT_RECORDS=2(任务输出记录数)
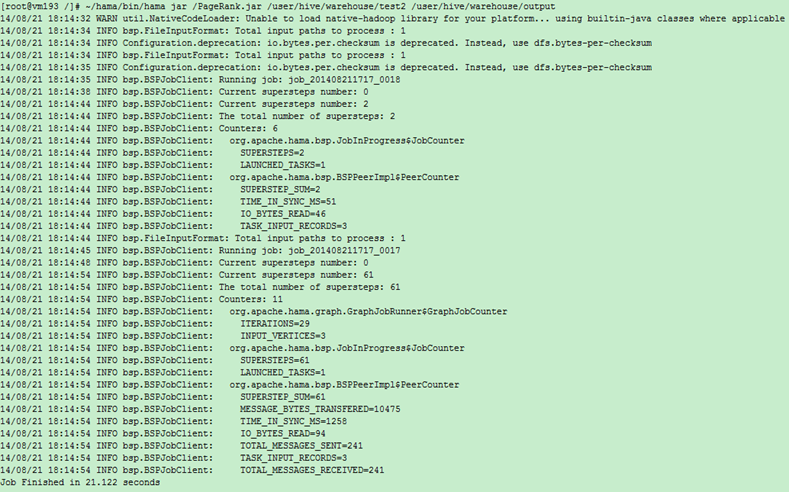
PageRank例子:
(代码见附件)
输出:
十、相关知识介绍
-
PRAM模型
PRAM(Parallel Random Access Machine,随机存取并行机器)模型,也称为共享存储的SIMD模型,是一种抽象的并行计算模型,它是从串行的RAM模型直接发展起来的。在这种模型中,假定存在一个容量无限大的共享存储器,有有限个或无限个功能相同的处理器,且他们都具有简单的算术运算和逻辑判断功能,在任何时刻个处理器都可以通过共享存储单元相互交互数据。
PRAM模型的优点:
PRAM模型特别适合于并行算法的表达、分析和比较,使用简单,很多关于并行计算机的底层细节,比如处理器间通信、存储系统管理和进程同步都被隐含在模型中;易于设计算法和稍加修改便可以运行在不同的并行计算机系统上;根据需要,可以在PRAM模型中加入一些诸如同步和通信等需要考虑的内容。
PRAM模型的缺点:
1. 模型中使用了一个全局共享存储器,且局存容量较小,不足以描述分布主存多处理机的性能瓶颈,而且共享单一存储器的假定,显然不适合于分布存储结构的MIMD机器;
2. PRAM模型是同步的,这就意味着所有的指令都按照锁步的方式操作,用户虽然感觉不到同步的存在,但同步的存在的确很耗费时间,而且不能反映现实中很多系统的异步性;
3. PRAM模型假设了每个处理器可在单位时间访问共享存储器的任一单元,因此要求处理机间通信无延迟、无限带宽和无开销,假定每个处理器均可以在单位时间内访问任何存储单元而略去了实际存在的,合理的细节,比如资源竞争和有限带宽,这是不现实的;
4. 未能描述多线程技术和流水线预取技术,而这两种技术又是当今并行体系结构用的最普遍的技术。
-
LogP模型
由Culler(1993)年提出的,是一种分布存储的、点到点通讯的多处理机模型,其中通讯由一组参数描述,实行隐式同步。
LogP模型是一种分布存储的、点到点通信的多处理机模型,其中通信网络由4个主要参数来描述:
1. L(Latency) 表示源处理机与目的处理机进行消息(一个或几个字)通信所需要的等待或延迟时间的上限,表示网络中消息的延迟。
2. o(overhead)表示处理机准备发送或接收每个消息的时间开销(包括操作系统核心开销和网络软件开销),在这段时间里处理不能执行其它操作。
3. g(gap)表示一台处理机连续两次发送或接收消息时的最小时间间隔,其倒数即微处理机的通信带宽。
4. P(Processor)处理机/存储器模块个数。
LogP模型的特点:
1. 抓住了网络与处理机之间的性能瓶颈。g反映了通信带宽,单位时间内最多有L/g个消息能进行处理机间传送。
2. 处理机之间异步工作,并通过处理机间的消息传送来完成同步。
3. 对多线程技术有一定反映。每个物理处理机可以模拟多个虚拟处理机(VP),当某个VP有访问请求时,计算不会终止,但VP的个数受限于通信带宽和上下文交换的开销。VP受限于网络容量,至多有L/g个VP。
4. 消息延迟不确定,但延迟不大于L。消息经历的等待时间是不可预测的,但在没有阻塞的情况下,最大不超过L。
5. LogP模型鼓励编程人员采用一些好的策略,如作业分配,计算与通信重叠以及平衡的通信模式等。
6. 可以预估算法的实际运行时间。
LogP模型的不足之处:
1. 对网络中的通信模式描述的不够深入。如重发消息可能占满带宽、中间路由器缓存饱和等未加描述。
2. LogP模型主要适用于消息传递算法设计,对于共享存储模式,则简单地认为远地读操作相当于两次消息传递,未考虑流水线预取技术、Cache引起的数据不一致性以及Cache命中率对计算的影响。
3. 未考虑多线程技术的上下文开销。
4. LogP模型假设用点对点消息路由器进行通信,这增加了编程者考虑路由器上相关通信操作的负担。
-
C3模型
C3模型假定处理机不能同时发送和接收消息,它对超步的性能分析分为两部分:计算单元CU,依赖于本地计算量;通信单元COU,依赖与处理机发送和接收数据的多少、消息的延迟及通信引起的拥挤量。该模型考虑了两种路由(存储转发路由和虫蚀寻径路由)和两种发送/接收原语(阻塞和无阻塞)对COU的影响。
C3 模型的特点:
- 用Cl和Cp来度量网络的拥挤对算法性能的影响;
- 考虑了不同路由和不同发送或接收原语对通信的影响;
- 不需要用户指定调度细节,就可以评估超步的时间复杂性;
- 类似于H-PRAM模型的层次结构,C3模型给编程者提供了K级路由算法的思路,即系统被分为K级子系统,各级子系统的操作相互独立,用超步代替了H-PRAM中的Sub PRAM进行分割。
C3 模型的不足之处:
-
- Cl度量的前题假设为同一通信对中的2个处理机要分别位于网络对分后的不同子网络内;
- 模型假设了网络带宽等于处理机带宽,这影响了正确描述可扩展系统;
- 在K级算法中,处理机间顺序可以由多种排列,但C3模型不能区分不同排列的难易程度。
-
BDM模型
1996年J.F.JaJa等人提出了一种块分布存储模型(BDM, Block Distributed Model)。它是共享存储编程模式与基于消息传递的分布存储系统之间的桥梁模型。主要有4个参数:
1. P处理器个数。
2.τ处理机从发出访问请求到得到远程数据的最大延迟时间(包括准备请求时间、请求包在网络中路由的时间、目的处理机接收请求的时间以及将包中M个连续字返回给原处理机的时间)。
3. M局部存储器中连续的M个字。
4.σ处理机发送数据到网络或从网络接收数据的时间。
BDM模型的特点:
- 用M反映出空间局部性特点,提供了一种评价共享主存算法的性能方法,度量了因远程访问引起的处理间的通信;
- BDM认可流水线技术。某个处理机的K次预取所需的时间为τ+KMσ (否则为K(τ+Mσ))
- 可编程性好;
- 考虑了共享主存中的存储竞争问题;
- 可以用来分析网络路由情况。
BDM模型的不足:
- 认为初始数据置于局存中,对于共享主存程序的编程者来说,需要额外增加数据移动操作;
- 未考虑网络中影响延迟的因素(如处理机的本地性、网络重拥挤等);
- 未考虑系统开销。
转载于:https://www.cnblogs.com/BYRans/p/4682282.html
最后
以上就是负责海燕最近收集整理的关于从BSP模型到Apache Hama一、什么是BSP模型二、BSP模型基本原理三、BSP模型特点四、BSP模型的评价五、BSP与MapReduce对比六、BSP模型的实现七、Apache Hama简介十、相关知识介绍的全部内容,更多相关从BSP模型到Apache内容请搜索靠谱客的其他文章。








发表评论 取消回复