前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站:https://www.captainai.net/dongkelun
前言
上一篇文章Hudi Spark源码学习总结-spark.read.format(“hudi”).load分析了load方法直接查询Hudi表路径的源码逻辑,那么Spark SQL select 表名的方式和load最终走的逻辑是一样的吗?本文带着这个疑问来分析一下select查询Hudi表的源码逻辑
版本
Spark 2.4.4
Hudi master 0.12.0-SNAPSHOT 最新代码
(可以借助Spark3 planChangeLog 打印日志信息查看哪些规则生效,Spark3和Spark2生效的规则大致是一样的)
示例代码
先Create Table,再Insert几条数据
spark.sql(s"select id, name, price, ts, dt from $tableName").show()
打印执行计划
同样的我们也可以先打印一下计划,方便我们分析
== Parsed Logical Plan ==
'Project ['id, 'name, 'price, 'ts, 'dt]
+- 'UnresolvedRelation `h0`
== Analyzed Logical Plan ==
id: int, name: string, price: double, ts: bigint, dt: string
Project [id#5, name#6, price#7, ts#8L, dt#9]
+- SubqueryAlias `default`.`h0`
+- Relation[_hoodie_commit_time#0,_hoodie_commit_seqno#1,_hoodie_record_key#2,_hoodie_partition_path#3,_hoodie_file_name#4,id#5,name#6,price#7,ts#8L,dt#9] parquet
== Optimized Logical Plan ==
Project [id#5, name#6, price#7, ts#8L, dt#9]
+- Relation[_hoodie_commit_time#0,_hoodie_commit_seqno#1,_hoodie_record_key#2,_hoodie_partition_path#3,_hoodie_file_name#4,id#5,name#6,price#7,ts#8L,dt#9] parquet
== Physical Plan ==
*(1) Project [id#5, name#6, price#7, ts#8L, dt#9]
+- *(1) FileScan parquet default.h0[id#5,name#6,price#7,ts#8L,dt#9] Batched: true, Format: Parquet, Location: HoodieFileIndex[file:/tmp/hudi/h0], PartitionCount: 3, PartitionFilters: [], PushedFilters: [], ReadSchema: struct<id:int,name:string,price:double,ts:bigint>
根据打印信息我们看到,parsing阶段返回的是Project(UnresolvedRelation),analysis阶段将子节点UnresolvedRelation转变为了SubqueryAlias(Relation),最后的planning和load一样返回flleScan,Location 也为HoodieFileIndex,我们只需要将这些关键点搞明白就可以了
spark.sql
def sql(sqlText: String): DataFrame = {
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}
前面的文章讲过了,parsePlan对应的为parsing阶段,根据打印信息我们知道parsePlan的返回值为
'Project ['id, 'name, 'price, 'ts, 'dt]
+- 'UnresolvedRelation `h0`
让我们来看一下它是如何返回的
parsing
singleStatement
根据文章Hudi Spark SQL源码学习总结-Create Table的逻辑,可知select对应Spark源码里的SqlBase.g4(即Hudi g4文件中没有重写select),那么parsePlan方法最终走到AbstractSqlParser.parsePlan
override def parsePlan(sqlText: String): LogicalPlan = parse(sqlText) { parser =>
astBuilder.visitSingleStatement(parser.singleStatement()) match {
case plan: LogicalPlan => plan
case _ =>
val position = Origin(None, None)
throw new ParseException(Option(sqlText), "Unsupported SQL statement", position, position)
}
}
override def visitSingleStatement(ctx: SingleStatementContext): LogicalPlan = withOrigin(ctx) {
visit(ctx.statement).asInstanceOf[LogicalPlan]
}
因为select 对应的嵌套逻辑比较复杂,我们可以利用IDEA里的ANTLR插件测试一下singleStatement对应的规则,我们只需要输入对应的sql,就可以得到它的parse tree
安装插件
Test Rule singleStatement
将鼠标放到singleStatement处,右键点击 Test Rule singleStatement
输入sql
输入sqlSELECT ID, NAME, PRICE, TS, DT FROM H0,这里需要大写才能识别
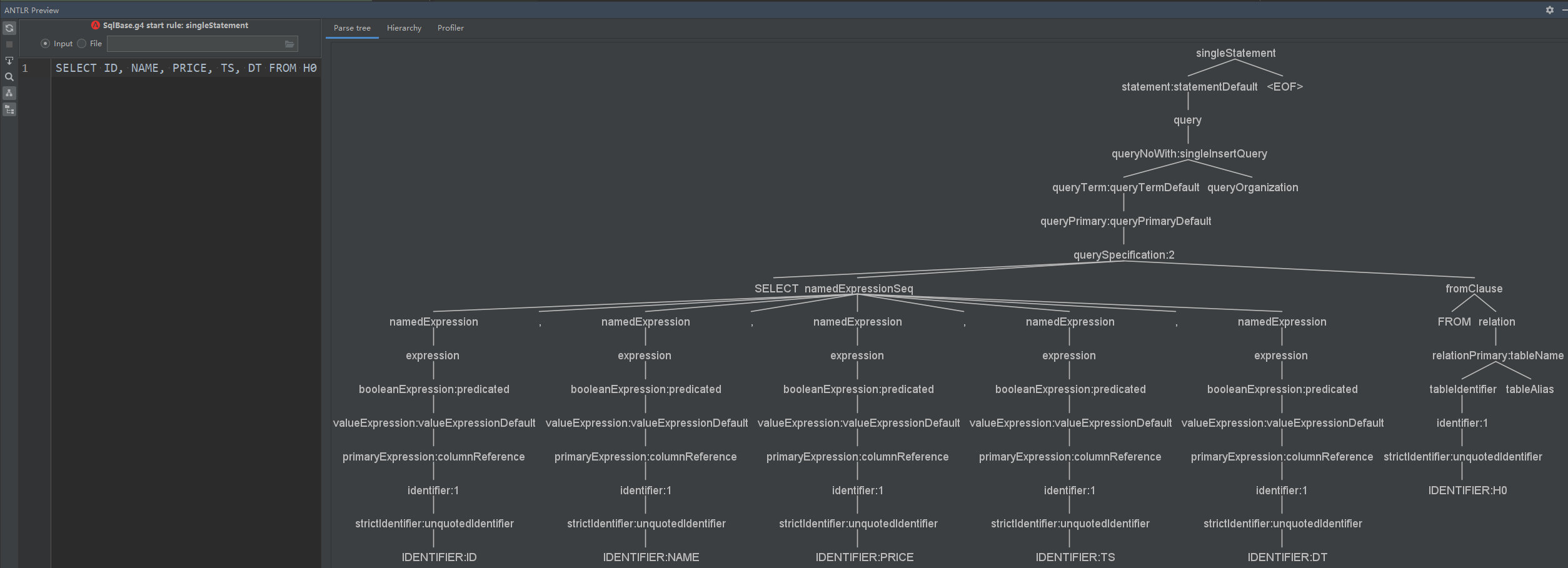
根据得到的parseTree,我们就知道g4文件中对应的大概逻辑了
singleStatement
: statement EOF
;
statement
: query #statementDefault
| USE db=identifier #use
query
: ctes? queryNoWith
;
queryNoWith
: insertInto? queryTerm queryOrganization #singleInsertQuery
| fromClause multiInsertQueryBody+ #multiInsertQuery
;
queryTerm
: queryPrimary #queryTermDefault
queryPrimary
: querySpecification #queryPrimaryDefault
querySpecification
: (((SELECT kind=TRANSFORM '(' namedExpressionSeq ')'
| kind=MAP namedExpressionSeq
| kind=REDUCE namedExpressionSeq))
inRowFormat=rowFormat?
(RECORDWRITER recordWriter=STRING)?
USING script=STRING
(AS (identifierSeq | colTypeList | ('(' (identifierSeq | colTypeList) ')')))?
outRowFormat=rowFormat?
(RECORDREADER recordReader=STRING)?
fromClause?
(WHERE where=booleanExpression)?)
| ((kind=SELECT (hints+=hint)* setQuantifier? namedExpressionSeq fromClause?
| fromClause (kind=SELECT setQuantifier? namedExpressionSeq)?)
lateralView*
(WHERE where=booleanExpression)?
aggregation?
(HAVING having=booleanExpression)?
windows?)
;
namedExpressionSeq
: namedExpression (',' namedExpression)*
;
namedExpression
: expression (AS? (identifier | identifierList))?
;
expression
: booleanExpression
;
......
但是逻辑还是比较复杂,我可以在IDEA了调试一下,看看ctx.statement的值
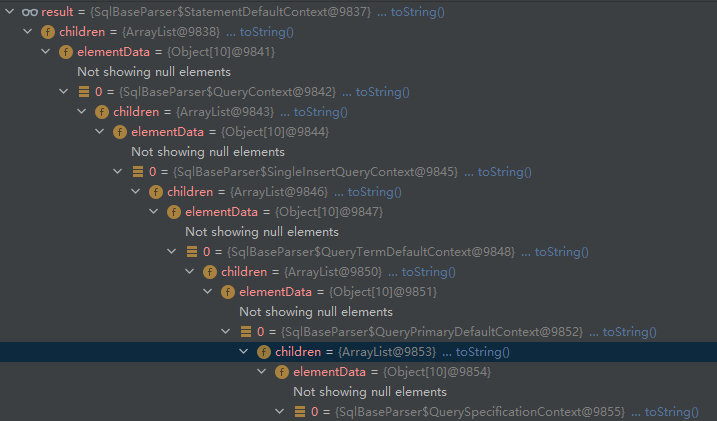
主要代码
对应的主要代码为:
StatementDefaultContext
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof SqlBaseVisitor ) return ((SqlBaseVisitor<? extends T>)visitor).visitStatementDefault(this);
else return visitor.visitChildren(this);
}
Override public T visitStatementDefault(SqlBaseParser.StatementDefaultContext ctx) { return visitChildren(ctx); }
override def visitChildren(node: RuleNode): AnyRef = {
if (node.getChildCount == 1) {
node.getChild(0).accept(this)
} else {
null
}
}
QueryContext
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof SqlBaseVisitor ) return ((SqlBaseVisitor<? extends T>)visitor).visitQuery(this);
else return visitor.visitChildren(this);
}
override def visitQuery(ctx: QueryContext): LogicalPlan = withOrigin(ctx) {
val query = plan(ctx.queryNoWith)
// Apply CTEs
query.optional(ctx.ctes) {
val ctes = ctx.ctes.namedQuery.asScala.map { nCtx =>
val namedQuery = visitNamedQuery(nCtx)
(namedQuery.alias, namedQuery)
}
// Check for duplicate names.
checkDuplicateKeys(ctes, ctx)
With(query, ctes)
}
}
plan
protected def plan(tree: ParserRuleContext): LogicalPlan = typedVisit(tree)
protected def typedVisit[T](ctx: ParseTree): T = {
ctx.accept(this).asInstanceOf[T]
}
SingleInsertQueryContext
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof SqlBaseVisitor ) return ((SqlBaseVisitor<? extends T>)visitor).visitSingleInsertQuery(this);
else return visitor.visitChildren(this);
}
override def visitSingleInsertQuery(
ctx: SingleInsertQueryContext): LogicalPlan = withOrigin(ctx) {
plan(ctx.queryTerm).
// Add organization statements.
optionalMap(ctx.queryOrganization)(withQueryResultClauses).
// Add insert.
optionalMap(ctx.insertInto())(withInsertInto)
}
QueryTermDefaultContext
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof SqlBaseVisitor ) return ((SqlBaseVisitor<? extends T>)visitor).visitQueryTermDefault(this);
else return visitor.visitChildren(this);
}
QueryPrimaryDefaultContext
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof SqlBaseVisitor ) return ((SqlBaseVisitor<? extends T>)visitor).visitQueryPrimaryDefault(this);
else return visitor.visitChildren(this);
}
QuerySpecificationContext
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof SqlBaseVisitor ) return ((SqlBaseVisitor<? extends T>)visitor).visitQuerySpecification(this);
else return visitor.visitChildren(this);
}
override def visitQuerySpecification(
ctx: QuerySpecificationContext): LogicalPlan = withOrigin(ctx) {
val from = OneRowRelation().optional(ctx.fromClause) {
visitFromClause(ctx.fromClause)
}
withQuerySpecification(ctx, from)
}
override def visitQuerySpecification(
ctx: QuerySpecificationContext): LogicalPlan = withOrigin(ctx) {
val from = OneRowRelation().optional(ctx.fromClause) {
visitFromClause(ctx.fromClause)
}
withQuerySpecification(ctx, from)
}
/**
* Add a query specification to a logical plan. The query specification is the core of the logical
* plan, this is where sourcing (FROM clause), transforming (SELECT TRANSFORM/MAP/REDUCE),
* projection (SELECT), aggregation (GROUP BY ... HAVING ...) and filtering (WHERE) takes place.
*
* Note that query hints are ignored (both by the parser and the builder).
*/
private def withQuerySpecification(
ctx: QuerySpecificationContext,
relation: LogicalPlan): LogicalPlan = withOrigin(ctx) {
import ctx._
// WHERE
def filter(ctx: BooleanExpressionContext, plan: LogicalPlan): LogicalPlan = {
Filter(expression(ctx), plan)
}
def withHaving(ctx: BooleanExpressionContext, plan: LogicalPlan): LogicalPlan = {
// Note that we add a cast to non-predicate expressions. If the expression itself is
// already boolean, the optimizer will get rid of the unnecessary cast.
val predicate = expression(ctx) match {
case p: Predicate => p
case e => Cast(e, BooleanType)
}
Filter(predicate, plan)
}
// Expressions.
val expressions = Option(namedExpressionSeq).toSeq
.flatMap(_.namedExpression.asScala)
.map(typedVisit[Expression])
// Create either a transform or a regular query.
val specType = Option(kind).map(_.getType).getOrElse(SqlBaseParser.SELECT)
specType match {
case SqlBaseParser.MAP | SqlBaseParser.REDUCE | SqlBaseParser.TRANSFORM =>
// Transform
// Add where.
val withFilter = relation.optionalMap(where)(filter)
// Create the attributes.
val (attributes, schemaLess) = if (colTypeList != null) {
// Typed return columns.
(createSchema(colTypeList).toAttributes, false)
} else if (identifierSeq != null) {
// Untyped return columns.
val attrs = visitIdentifierSeq(identifierSeq).map { name =>
AttributeReference(name, StringType, nullable = true)()
}
(attrs, false)
} else {
(Seq(AttributeReference("key", StringType)(),
AttributeReference("value", StringType)()), true)
}
// Create the transform.
ScriptTransformation(
expressions,
string(script),
attributes,
withFilter,
withScriptIOSchema(
ctx, inRowFormat, recordWriter, outRowFormat, recordReader, schemaLess))
case SqlBaseParser.SELECT =>
// Regular select
// Add lateral views.
val withLateralView = ctx.lateralView.asScala.foldLeft(relation)(withGenerate)
// Add where.
val withFilter = withLateralView.optionalMap(where)(filter)
// Add aggregation or a project.
val namedExpressions = expressions.map {
case e: NamedExpression => e
case e: Expression => UnresolvedAlias(e)
}
def createProject() = if (namedExpressions.nonEmpty) {
Project(namedExpressions, withFilter)
} else {
withFilter
}
val withProject = if (aggregation == null && having != null) {
if (conf.getConf(SQLConf.LEGACY_HAVING_WITHOUT_GROUP_BY_AS_WHERE)) {
// If the legacy conf is set, treat HAVING without GROUP BY as WHERE.
withHaving(having, createProject())
} else {
// According to SQL standard, HAVING without GROUP BY means global aggregate.
withHaving(having, Aggregate(Nil, namedExpressions, withFilter))
}
} else if (aggregation != null) {
val aggregate = withAggregation(aggregation, namedExpressions, withFilter)
aggregate.optionalMap(having)(withHaving)
} else {
// When hitting this branch, `having` must be null.
createProject()
}
// Distinct
val withDistinct = if (setQuantifier() != null && setQuantifier().DISTINCT() != null) {
Distinct(withProject)
} else {
withProject
}
// Window
val withWindow = withDistinct.optionalMap(windows)(withWindows)
// Hint
hints.asScala.foldRight(withWindow)(withHints)
}
}
visitFromClause
* Create a logical plan for a given 'FROM' clause. Note that we support multiple (comma
* separated) relations here, these get converted into a single plan by condition-less inner join.
*/
override def visitFromClause(ctx: FromClauseContext): LogicalPlan = withOrigin(ctx) {
val from = ctx.relation.asScala.foldLeft(null: LogicalPlan) { (left, relation) =>
// relation为RelationContext
// relation.relationPrimary为TableNameContext
val right = plan(relation.relationPrimary)
val join = right.optionalMap(left)(Join(_, _, Inner, None))
withJoinRelations(join, relation)
}
if (ctx.pivotClause() != null) {
if (!ctx.lateralView.isEmpty) {
throw new ParseException("LATERAL cannot be used together with PIVOT in FROM clause", ctx)
}
withPivot(ctx.pivotClause, from)
} else {
ctx.lateralView.asScala.foldLeft(from)(withGenerate)
}
}
TableNameContext
@Override
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof SqlBaseVisitor ) return ((SqlBaseVisitor<? extends T>)visitor).visitTableName(this);
else return visitor.visitChildren(this);
}
override def visitTableName(ctx: TableNameContext): LogicalPlan = withOrigin(ctx) {
val tableId = visitTableIdentifier(ctx.tableIdentifier)
val table = mayApplyAliasPlan(ctx.tableAlias, UnresolvedRelation(tableId))
table.optionalMap(ctx.sample)(withSample)
}
最终是通过withQuerySpecification的createProject方法返回的Project(namedExpressions, withFilter),其中的withFilter是通过visitFromClause返回的UnresolvedRelation(tableId),所以在parsing阶段返回
'Project ['id, 'name, 'price, 'ts, 'dt]
+- 'UnresolvedRelation `h0`
analysis
ResolveRelations
它的子节点为UnresolvedRelation,会匹配到第二个,调用resolveRelation
def apply(plan: LogicalPlan): LogicalPlan = plan.resolveOperatorsUp {
case i @ InsertIntoTable(u: UnresolvedRelation, parts, child, _, _) if child.resolved =>
EliminateSubqueryAliases(lookupTableFromCatalog(u)) match {
case v: View =>
u.failAnalysis(s"Inserting into a view is not allowed. View: ${v.desc.identifier}.")
case other => i.copy(table = other)
}
case u: UnresolvedRelation => resolveRelation(u)
}
resolveRelation
因为我们没有指定database,所以isRunningDirectlyOnFiles返回false,匹配到第一个
def resolveRelation(plan: LogicalPlan): LogicalPlan = plan match {
case u: UnresolvedRelation if !isRunningDirectlyOnFiles(u.tableIdentifier) =>
val defaultDatabase = AnalysisContext.get.defaultDatabase
val foundRelation = lookupTableFromCatalog(u, defaultDatabase)
resolveRelation(foundRelation)
// The view's child should be a logical plan parsed from the `desc.viewText`, the variable
// `viewText` should be defined, or else we throw an error on the generation of the View
// operator.
case view @ View(desc, _, child) if !child.resolved =>
// Resolve all the UnresolvedRelations and Views in the child.
val newChild = AnalysisContext.withAnalysisContext(desc.viewDefaultDatabase) {
if (AnalysisContext.get.nestedViewDepth > conf.maxNestedViewDepth) {
view.failAnalysis(s"The depth of view ${view.desc.identifier} exceeds the maximum " +
s"view resolution depth (${conf.maxNestedViewDepth}). Analysis is aborted to " +
s"avoid errors. Increase the value of ${SQLConf.MAX_NESTED_VIEW_DEPTH.key} to work " +
"around this.")
}
executeSameContext(child)
}
view.copy(child = newChild)
case p @ SubqueryAlias(_, view: View) =>
val newChild = resolveRelation(view)
p.copy(child = newChild)
case _ => plan
}
// If the database part is specified, and we support running SQL directly on files, and
// it's not a temporary view, and the table does not exist, then let's just return the
// original UnresolvedRelation. It is possible we are matching a query like "select *
// from parquet.`/path/to/query`". The plan will get resolved in the rule `ResolveDataSource`.
// Note that we are testing (!db_exists || !table_exists) because the catalog throws
// an exception from tableExists if the database does not exist.
private def isRunningDirectlyOnFiles(table: TableIdentifier): Boolean = {
table.database.isDefined && conf.runSQLonFile && !catalog.isTemporaryTable(table) &&
(!catalog.databaseExists(table.database.get) || !catalog.tableExists(table))
}
lookupTableFromCatalog
private def lookupTableFromCatalog(
u: UnresolvedRelation,
defaultDatabase: Option[String] = None): LogicalPlan = {
val tableIdentWithDb = u.tableIdentifier.copy(
database = u.tableIdentifier.database.orElse(defaultDatabase))
try {
catalog.lookupRelation(tableIdentWithDb)
} catch {
case e: NoSuchTableException =>
u.failAnalysis(s"Table or view not found: ${tableIdentWithDb.unquotedString}", e)
// If the database is defined and that database is not found, throw an AnalysisException.
// Note that if the database is not defined, it is possible we are looking up a temp view.
case e: NoSuchDatabaseException =>
u.failAnalysis(s"Table or view not found: ${tableIdentWithDb.unquotedString}, the " +
s"database ${e.db} doesn't exist.", e)
}
}
lookupRelation
返回SubqueryAlias(table, db, UnresolvedCatalogRelation(metadata))
def lookupRelation(name: TableIdentifier): LogicalPlan = {
synchronized {
val db = formatDatabaseName(name.database.getOrElse(currentDb))
val table = formatTableName(name.table)
if (db == globalTempViewManager.database) {
globalTempViewManager.get(table).map { viewDef =>
SubqueryAlias(table, db, viewDef)
}.getOrElse(throw new NoSuchTableException(db, table))
} else if (name.database.isDefined || !tempViews.contains(table)) {
val metadata = externalCatalog.getTable(db, table)
if (metadata.tableType == CatalogTableType.VIEW) {
val viewText = metadata.viewText.getOrElse(sys.error("Invalid view without text."))
// The relation is a view, so we wrap the relation by:
// 1. Add a [[View]] operator over the relation to keep track of the view desc;
// 2. Wrap the logical plan in a [[SubqueryAlias]] which tracks the name of the view.
val child = View(
desc = metadata,
output = metadata.schema.toAttributes,
child = parser.parsePlan(viewText))
SubqueryAlias(table, db, child)
} else {
SubqueryAlias(table, db, UnresolvedCatalogRelation(metadata))
}
} else {
SubqueryAlias(table, tempViews(table))
}
}
}
FindDataSourceTable
上面讲了在ResolveRelations返回UnresolvedCatalogRelation,所以匹配到第三个,调用readDataSourceTable
override def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperators {
case i @ InsertIntoTable(UnresolvedCatalogRelation(tableMeta), _, _, _, _)
if DDLUtils.isDatasourceTable(tableMeta) =>
i.copy(table = readDataSourceTable(tableMeta))
case i @ InsertIntoTable(UnresolvedCatalogRelation(tableMeta), _, _, _, _) =>
i.copy(table = readHiveTable(tableMeta))
case UnresolvedCatalogRelation(tableMeta) if DDLUtils.isDatasourceTable(tableMeta) =>
readDataSourceTable(tableMeta)
case UnresolvedCatalogRelation(tableMeta) =>
readHiveTable(tableMeta)
}
readDataSourceTable
private def readDataSourceTable(table: CatalogTable): LogicalPlan = {
val qualifiedTableName = QualifiedTableName(table.database, table.identifier.table)
val catalog = sparkSession.sessionState.catalog
catalog.getCachedPlan(qualifiedTableName, new Callable[LogicalPlan]() {
override def call(): LogicalPlan = {
val pathOption = table.storage.locationUri.map("path" -> CatalogUtils.URIToString(_))
val dataSource =
DataSource(
sparkSession,
// In older version(prior to 2.1) of Spark, the table schema can be empty and should be
// inferred at runtime. We should still support it.
userSpecifiedSchema = if (table.schema.isEmpty) None else Some(table.schema),
partitionColumns = table.partitionColumnNames,
bucketSpec = table.bucketSpec,
className = table.provider.get,
options = table.storage.properties ++ pathOption,
catalogTable = Some(table))
LogicalRelation(dataSource.resolveRelation(checkFilesExist = false), table)
}
})
dataSource.resolveRelation
这里的providingClass我们在前面的几篇文章中讲过了,它是Spark2DefaultDatasource,这里会模式匹配到第一个
def resolveRelation(checkFilesExist: Boolean = true): BaseRelation = {
val relation = (providingClass.newInstance(), userSpecifiedSchema) match {
// TODO: Throw when too much is given.
case (dataSource: SchemaRelationProvider, Some(schema)) =>
dataSource.createRelation(sparkSession.sqlContext, caseInsensitiveOptions, schema)
case (dataSource: RelationProvider, None) =>
dataSource.createRelation(sparkSession.sqlContext, caseInsensitiveOptions)
case (_: SchemaRelationProvider, None) =>
throw new AnalysisException(s"A schema needs to be specified when using $className.")
case (dataSource: RelationProvider, Some(schema)) =>
val baseRelation =
dataSource.createRelation(sparkSession.sqlContext, caseInsensitiveOptions)
if (baseRelation.schema != schema) {
throw new AnalysisException(s"$className does not allow user-specified schemas.")
}
baseRelation
lazy val providingClass: Class[_] =
DataSource.lookupDataSource(className, sparkSession.sessionState.conf)
Spark2DefaultDatasource.createRelation
后面的就和我们之前讲的load方法一样了,返回值为HadoopFsRelation(HoodieFileIndex,),所以readDataSourceTable返回LogicalRelation(HadoopFsRelation(HoodieFileIndex,))
override def createRelation(sqlContext: SQLContext,
optParams: Map[String, String],
schema: StructType): BaseRelation = {
val path = optParams.get("path")
val readPathsStr = optParams.get(DataSourceReadOptions.READ_PATHS.key)
if (path.isEmpty && readPathsStr.isEmpty) {
throw new HoodieException(s"'path' or '$READ_PATHS' or both must be specified.")
}
val readPaths = readPathsStr.map(p => p.split(",").toSeq).getOrElse(Seq())
val allPaths = path.map(p => Seq(p)).getOrElse(Seq()) ++ readPaths
val fs = FSUtils.getFs(allPaths.head, sqlContext.sparkContext.hadoopConfiguration)
val globPaths = if (path.exists(_.contains("*")) || readPaths.nonEmpty) {
HoodieSparkUtils.checkAndGlobPathIfNecessary(allPaths, fs)
} else {
Seq.empty
}
// Add default options for unspecified read options keys.
val parameters = (if (globPaths.nonEmpty) {
Map(
"glob.paths" -> globPaths.mkString(",")
)
} else {
Map()
}) ++ DataSourceOptionsHelper.parametersWithReadDefaults(optParams)
// Get the table base path
val tablePath = if (globPaths.nonEmpty) {
DataSourceUtils.getTablePath(fs, globPaths.toArray)
} else {
DataSourceUtils.getTablePath(fs, Array(new Path(path.get)))
}
log.info("Obtained hudi table path: " + tablePath)
val metaClient = HoodieTableMetaClient.builder().setConf(fs.getConf).setBasePath(tablePath).build()
val isBootstrappedTable = metaClient.getTableConfig.getBootstrapBasePath.isPresent
val tableType = metaClient.getTableType
val queryType = parameters(QUERY_TYPE.key)
// NOTE: In cases when Hive Metastore is used as catalog and the table is partitioned, schema in the HMS might contain
// Hive-specific partitioning columns created specifically for HMS to handle partitioning appropriately. In that
// case we opt in to not be providing catalog's schema, and instead force Hudi relations to fetch the schema
// from the table itself
val userSchema = if (isUsingHiveCatalog(sqlContext.sparkSession)) {
None
} else {
Option(schema)
}
log.info(s"Is bootstrapped table => $isBootstrappedTable, tableType is: $tableType, queryType is: $queryType")
if (metaClient.getCommitsTimeline.filterCompletedInstants.countInstants() == 0) {
new EmptyRelation(sqlContext, metaClient)
} else {
(tableType, queryType, isBootstrappedTable) match {
case (COPY_ON_WRITE, QUERY_TYPE_SNAPSHOT_OPT_VAL, false) |
(COPY_ON_WRITE, QUERY_TYPE_READ_OPTIMIZED_OPT_VAL, false) |
(MERGE_ON_READ, QUERY_TYPE_READ_OPTIMIZED_OPT_VAL, false) =>
resolveBaseFileOnlyRelation(sqlContext, globPaths, userSchema, metaClient, parameters)
case (COPY_ON_WRITE, QUERY_TYPE_INCREMENTAL_OPT_VAL, _) =>
new IncrementalRelation(sqlContext, parameters, userSchema, metaClient)
case (MERGE_ON_READ, QUERY_TYPE_SNAPSHOT_OPT_VAL, false) =>
new MergeOnReadSnapshotRelation(sqlContext, parameters, userSchema, globPaths, metaClient)
case (MERGE_ON_READ, QUERY_TYPE_INCREMENTAL_OPT_VAL, _) =>
new MergeOnReadIncrementalRelation(sqlContext, parameters, userSchema, metaClient)
case (_, _, true) =>
new HoodieBootstrapRelation(sqlContext, userSchema, globPaths, metaClient, parameters)
case (_, _, _) =>
throw new HoodieException(s"Invalid query type : $queryType for tableType: $tableType," +
s"isBootstrappedTable: $isBootstrappedTable ")
}
}
}
optimization 和 planning
optimization 和 planning是在show方法中触发的(只适用于查询),因为前面返回的和load方法返回值一样(有一点不同的是多了一层Project,不过后面会遍历子节点),所以后面的逻辑也和load一样了,大致逻辑 show->showString->getRows->->select Project包装->take->limit->GlobalLimit->withAction->planner.plan->SpecialLimits->CollectLimitExec->FileSourceStrategy->ProjectExec(projectList,FileSourceScanExec(HadoopFsRelation)))->CollapseCodegenStages->WholeStageCodegenExec->collectFromPlan->executeCollect->executeTake->getByteArrayRdd->doExecute->inputRDDs->FileSourceScanExec.inputRDD->createNonBucketedReadRDD->selectedPartitions->HoodieFileIndex.listFiles
总结
通过上面的分析,我们发现Spark查询Hudi表不管是通过load的方式还是通过sql select的方法最终走的逻辑都是一样的。都是先查找source=hudi的DataSource,Spark2对应的为Spark2DefaultDatasource,然后通过Spark2DefaultDatasource的createRelation创建relation,如果使用HadoopFsRelation,则最终调用HoodieFileIndex.listFiles实现hudi自己的查询逻辑,如果使用BaseFileOnlyRelation,则最终调用HoodieBaseRelation.buildScan实现查询Hudi的逻辑,不同点只是入口不同,load是在load函数中查找DataSource,然后在loadV1Source方法中resolveRelation继而createRelation,而sql select的入口则是先通过parsing返回UnresolvedRelation,再在analysis阶段通过规则ResolveRelations和FindDataSourceTable实现创建relation的
相关阅读
- Hudi Spark SQL源码学习总结-Create Table
- Hudi Spark SQL源码学习总结-CTAS
- Hudi Spark源码学习总结-df.write.format(“hudi”).save
- Hudi Spark源码学习总结-spark.read.format(“hudi”).load
- Hudi Spark源码学习总结-spark.read.format(“hudi”).load(2)
最后
以上就是寂寞秋天最近收集整理的关于Hudi Spark SQL源码学习总结-select(查询)的全部内容,更多相关Hudi内容请搜索靠谱客的其他文章。








发表评论 取消回复