读取数据
import keras
from keras import layers
import numpy as np
from matplotlib import pyplot as plt
import pandas as pd
%matplotlib inline
Using TensorFlow backend.
from keras.datasets import mnist as mn
# 读取训练数据和测试数据
(train_img, train_lab), (test_img, test_lab) = mn.load_data()
Downloading data from https://s3.amazonaws.com/img-datasets/mnist.npz
11493376/11490434 [==============================] - 893s 78us/step
train_img.shape, train_lab.shape, test_img.shape, test_lab.shape
((60000, 28, 28), (60000,), (10000, 28, 28), (10000,))
# 绘制一张样本看一下
plt.imshow(train_img[0])
<matplotlib.image.AxesImage at 0x13d3c198>

# 看一下这个数是几
train_lab
array([5, 0, 4, ..., 5, 6, 8], dtype=uint8)
这里是28*28的数据,如果不用CNN而只是用普通的MLP,那要把它Flatten一下,让这两个维度合起来(784)。
建立模型
model = keras.Sequential()
# Flatten层会把除了第一维(样本数)之外的,也就是后面的维度摊平成同一个维度里
model.add(layers.Flatten()) # (60000, 28, 28) => (60000, 28*28)
# 已经不是第一层了,所以不再需要input_dim了,会直接根据前面层的输出来设置
model.add(layers.Dense(64, activation='relu'))
# Softmax多分类,因为一共10种数字,所以输出维度是10
model.add(layers.Dense(10, activation='softmax'))
编译模型
model.compile(
optimizer='adam',
# 注意因为label是顺序编码的,这里用这个
loss='sparse_categorical_crossentropy',
metrics=['acc']
)
训练模型
# 内存/显存容量是有限的,一般一次放一个batch的数据进去训练,而不是每次把整个样本集一起训练一遍
history = model.fit(train_img, train_lab, epochs=50, batch_size=512, validation_data=(test_img, test_lab), verbose=0) # 每批512张图片
WARNING:tensorflow:From E:MyProgramAnacondaenvskrslibsite-packagestensorflowpythonopsmath_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
查看Performance
model.evaluate(train_img, train_lab)
60000/60000 [==============================] - 2s 28us/step
[3.6218268792152406, 0.77455]
model.evaluate(test_img, test_lab)
10000/10000 [==============================] - 0s 26us/step
[3.6389780288696287, 0.7732]
plt.plot(history.epoch, history.history.get('val_acc'), c='g', label='validation acc')
plt.plot(history.epoch, history.history.get('acc'), c='b', label='train acc')
plt.legend()
<matplotlib.legend.Legend at 0x18578fd0>
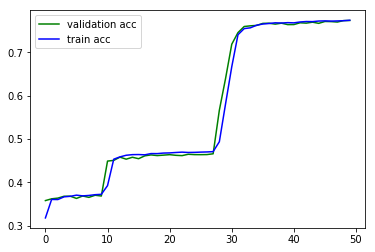
可以看到没有发生过拟合,但预测效果不是很好,Acc不高。
使用模型做预测
# 得到的都是10维的概率向量,用argmax取每行最大值索引即是对应数字
np.argmax(model.predict(test_img[:10]), axis=1)
array([9, 2, 1, 0, 4, 1, 4, 9, 6, 9], dtype=int64)
# 查看一下实际label
test_lab[:10]
array([7, 2, 1, 0, 4, 1, 4, 9, 5, 9], dtype=uint8)
调整超参数以优化模型
总的原则:神经网络的容量足够拟合数据。
比较简单的数据用比较小容量的网络。
如果网络中间突然有容量比较小的层,信息就会丢失,容易引起欠拟合。
先增大网络容量,直到过拟合。再采取措施抑制过拟合。再增大网络容量,直到过拟合。。如此反复。
model = keras.Sequential()
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
# 多加两层隐藏层,以让它过拟合
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc']
)
history = model.fit(train_img, train_lab, epochs=50, batch_size=512, validation_data=(test_img, test_lab), verbose=0)
# 训练集表现
model.evaluate(train_img, train_lab)
60000/60000 [==============================] - 2s 30us/step
[0.03728870131107869, 0.9931333333333333]
# 测试集表现
model.evaluate(test_img, test_lab)
10000/10000 [==============================] - 0s 29us/step
[0.24160608106338732, 0.9685]
plt.plot(history.epoch, history.history.get('val_acc'), c='g', label='validation acc')
plt.plot(history.epoch, history.history.get('acc'), c='b', label='train acc')
plt.legend()
<matplotlib.legend.Legend at 0x1bc82470>
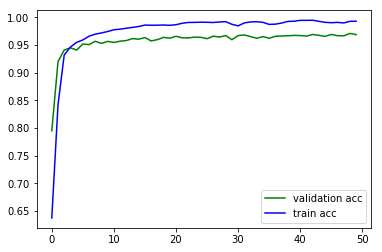
发生了一定程度的过拟合,现在要采取措施去抑制过拟合。不妨添加两个Dropout层(实际上不是层)看一下。
model = keras.Sequential()
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dropout(0.5)) # 添加Dropout
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dropout(0.5)) # 添加Dropout
model.add(layers.Dense(10, activation='softmax'))
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc']
)
# 前面添加了Dropout,在训练时随机断开连接,这样同等epochs下训练强度就变弱了
# 所以这里要增大epochs,考虑到0.5*0.5=0.25也就是1/4,这里不妨把epochs增大4倍到200
history = model.fit(train_img, train_lab, epochs=200, batch_size=512, validation_data=(test_img, test_lab), verbose=0)
WARNING:tensorflow:From E:MyProgramAnacondaenvskrslibsite-packageskerasbackendtensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
# 训练集表现
model.evaluate(train_img, train_lab)
60000/60000 [==============================] - 2s 27us/step
[0.01952453022014009, 0.9959]
# 测试集表现
model.evaluate(test_img, test_lab)
10000/10000 [==============================] - 0s 30us/step
[0.21649456044882537, 0.9703]
plt.plot(history.epoch, history.history.get('val_acc'), c='g', label='validation acc')
plt.plot(history.epoch, history.history.get('acc'), c='b', label='train acc')
plt.legend()
<matplotlib.legend.Legend at 0x1c394cc0>
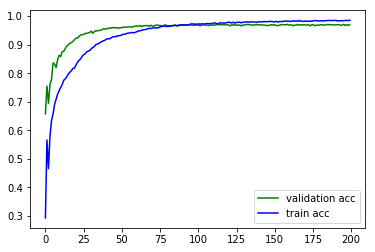
效果提升了!较好的抑制了过拟合,也提升了在测试集上的Performance。
最后
以上就是内向向日葵最近收集整理的关于【Keras学习笔记】9:从MNIST手写数字识别中初识ANN超参数的选择的全部内容,更多相关【Keras学习笔记】9:从MNIST手写数字识别中初识ANN超参数内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复