我是靠谱客的博主 端庄大门,这篇文章主要介绍Spark persist MEMORY_AND_DISK & DISK_ONLY1 Overview2 Summary,现在分享给大家,希望可以做个参考。
文章目录
- 1 Overview
- 2 Summary
1 Overview
假设程序中需要对一个接近 3T 的模型文件进行 cache。
3T 的文件: hdfs://xxx:9000/xxx_graph
object Persona {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName("模型 cache 测试")
.getOrCreate()
val actions = spark.sparkContext.textFile(args(0)).persist(StorageLevel.MEMORY_AND_DISK).setName("model")
// 触发 cache,没有实际意义
println(s"number of actions: ${actions.count()}")
// 10 mins
Thread.sleep(1000 * 60 * 10)
}
}
测试思路,3T 的模型,如果要 cache 住,50G 的 Executor,至少需要 3T * 1024G/T / 50G * 2 = 125个左右。(乘以2是因为 Executor 的 JVM 默认大概会用 50% 的 Host 内存)。测试中使用20个。
代码如果使用 StorageLevel.MEMORY_AND_DISK,会有个问题,因为20个 Executor,纯内存肯定是不能 Cache 整个模型的,模型数据会 spill 到磁盘,同时 JVM 会处于经常性的 GC,这样这个操作肯定是非常耗时的。
如下图,560G 基本是可用于 Cache 的内存了,其余时间一直在刷盘。

所有 Executor 一直处于频繁的 GC。
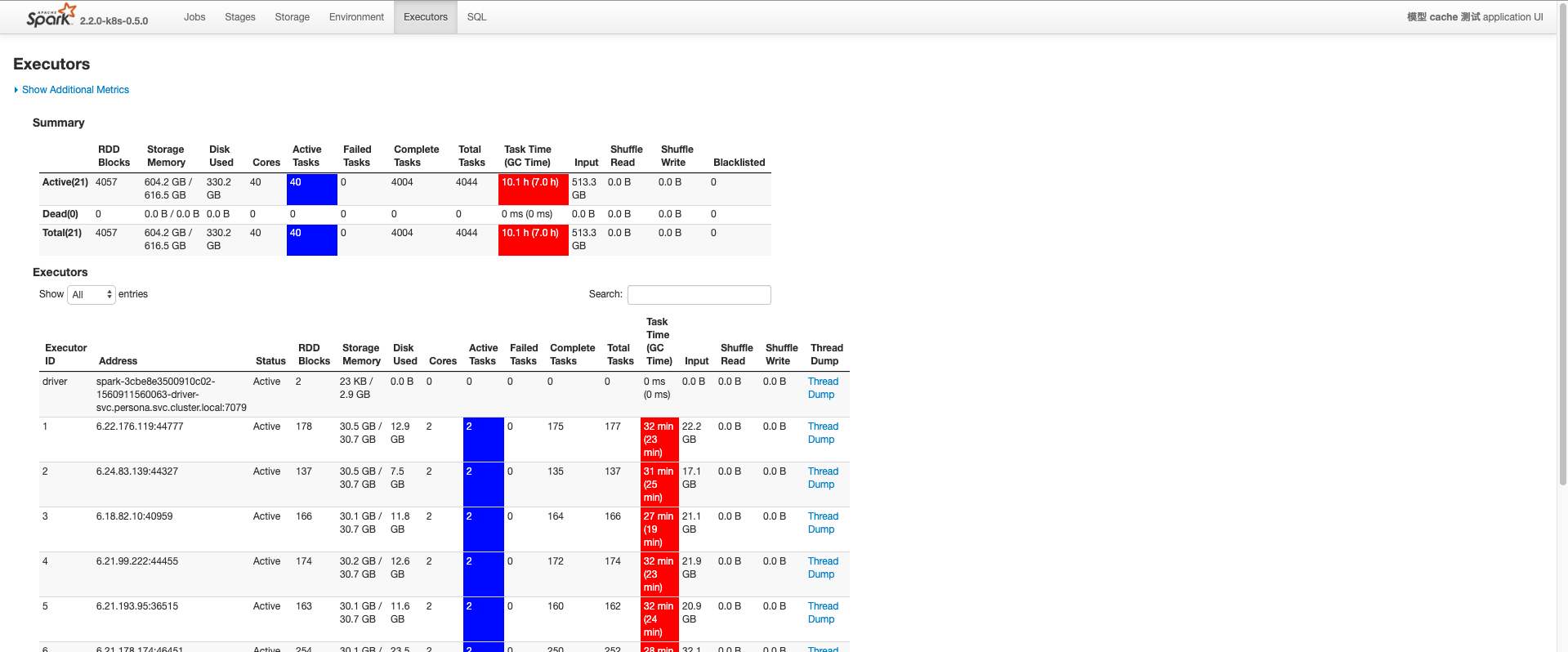
Memory 撑爆,CPU 一直繁忙。
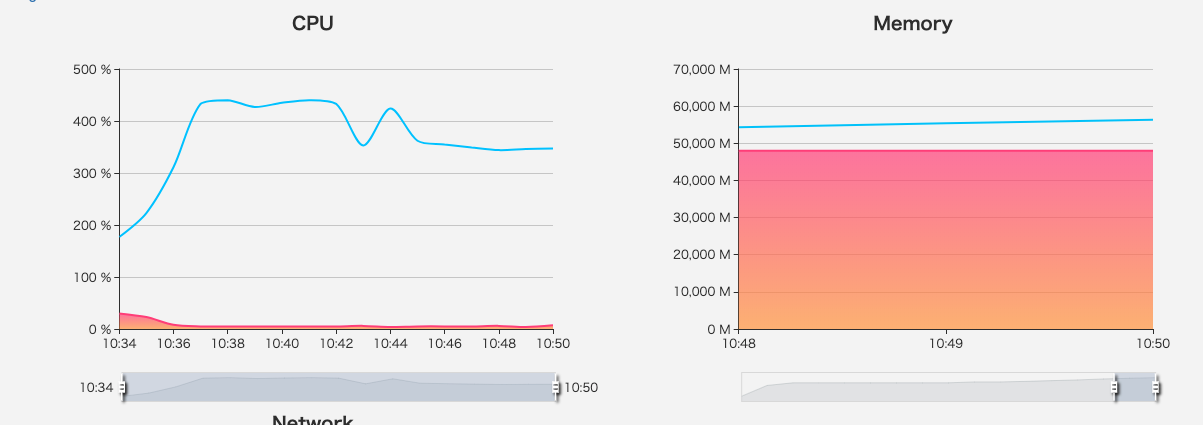
光是一个 Job 引发的 cache 模型,目测至少需要一个小时。

以下是调整了 cache 级别,改为 StorageLevel.DISK_ONLY。没有了 GC 消耗。
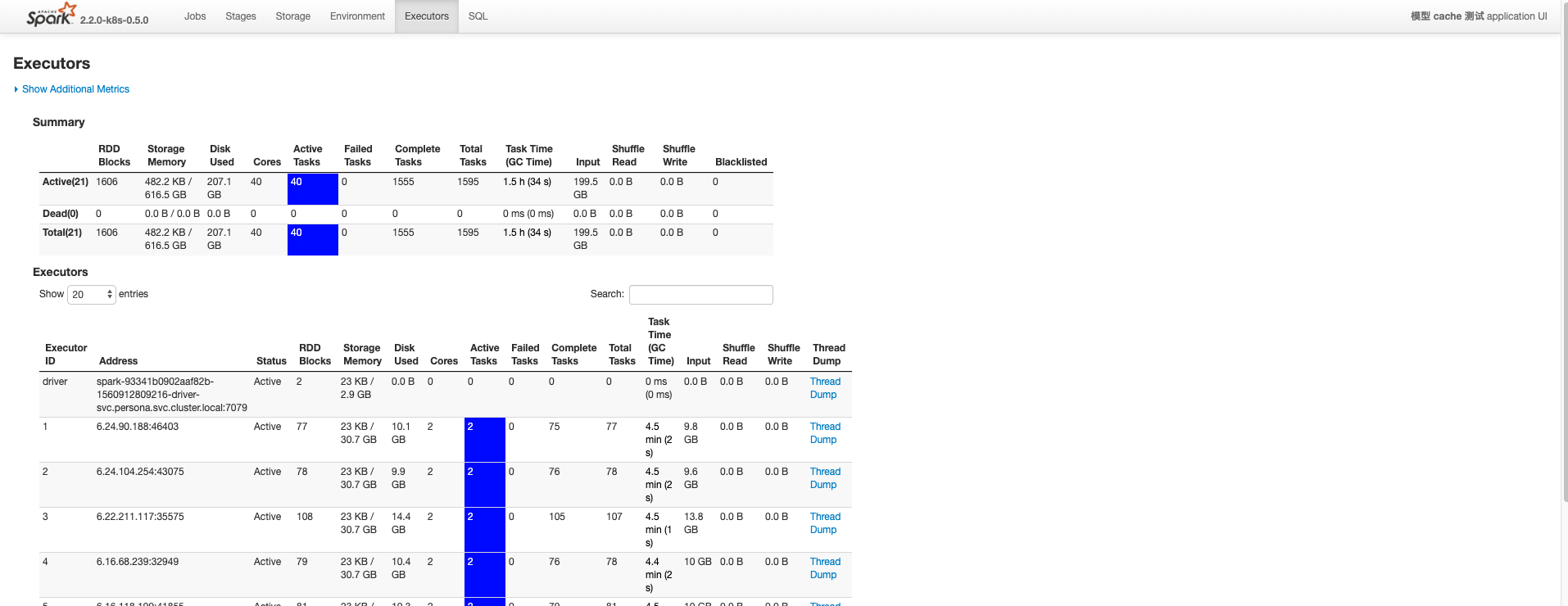
10分钟已经完成30%的 task 了。

2 Summary
针对大数据集,如果在 Memory 不足够的情况下(TB 级别的基本都很难有匹配的资源),可以让其直接落到磁盘,通过减少 GC Time 来改善程序的 Performance。
最后
以上就是端庄大门最近收集整理的关于Spark persist MEMORY_AND_DISK & DISK_ONLY1 Overview2 Summary的全部内容,更多相关Spark内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复