1 RDD创建
RDD创建有两种形式,1:从外部读取数据源,外部可指本地系统、HDFS系统等;2:调用SparkContext的parallelize方法,在Driver中一个已经存在的集合(数组)上创建。
1.1 演示前提
启动hadoop和spark-shell
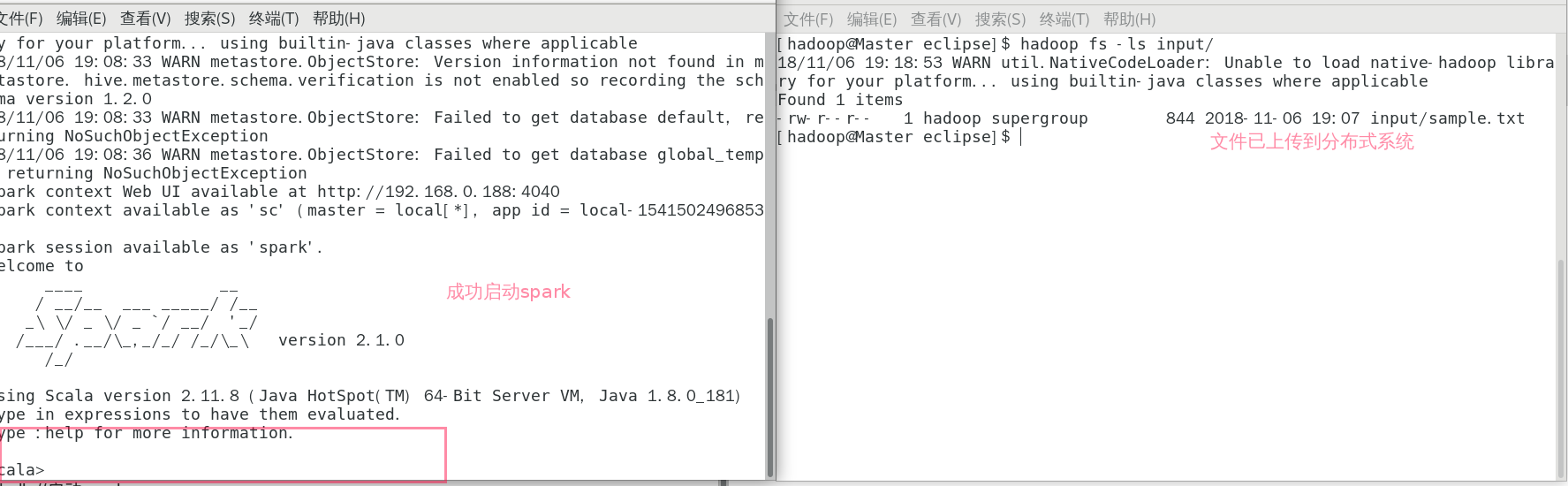
>>start-dfs.sh //启动hadoop
>>sprak-shell //启动spark
>>hadoop fs -copyFromLocal /home/hadoop/sample.txt input
//将本地文件上传到分布式系统
1.2 从文件系统中加载数据创建RDD

1.3 通过并行集合创建RDD

2 RDD操作
RDD操作一般为转换和行动操作,转换表示一种RDD转换为另一种RDD,行动表示在RDD上进行非修改性操作。
| 常用转换操作: | 说明 |
|---|---|
| filter(func) | 筛选出满足函数func的元素,并返回一个新的数据。 |
| map(func) | 将每个元素传递到函数func中,并将结果返回为一个新的数据集 |
| flatMap(func) | 与map()相似,但每个输入元素都可以映射到0或多个输出结果 |
| groupByKey() | 应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集 |
| reduceByKey(func) | 应用于(K,V)键值对的数据集时,返回一个新的(K,V)形式的数据集,其中的每个值是将每个key传递到函数func中进行聚合. |
| 常用行动操作: | 说明 |
|---|---|
| count() | 返回数据集中的元素个数 |
| collect() | 以数组的形式返回数据集中的所有元素 |
| first() | 返回数据集中的第一个元素 |
| take(n) | 以数组的形式返回数据集中的前n个元素 reduce(func) 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素 |
| foreach(func) | 将数据集中的每个元素传递到函数func中运行*: |
2.1 reduceByKey(func)演示
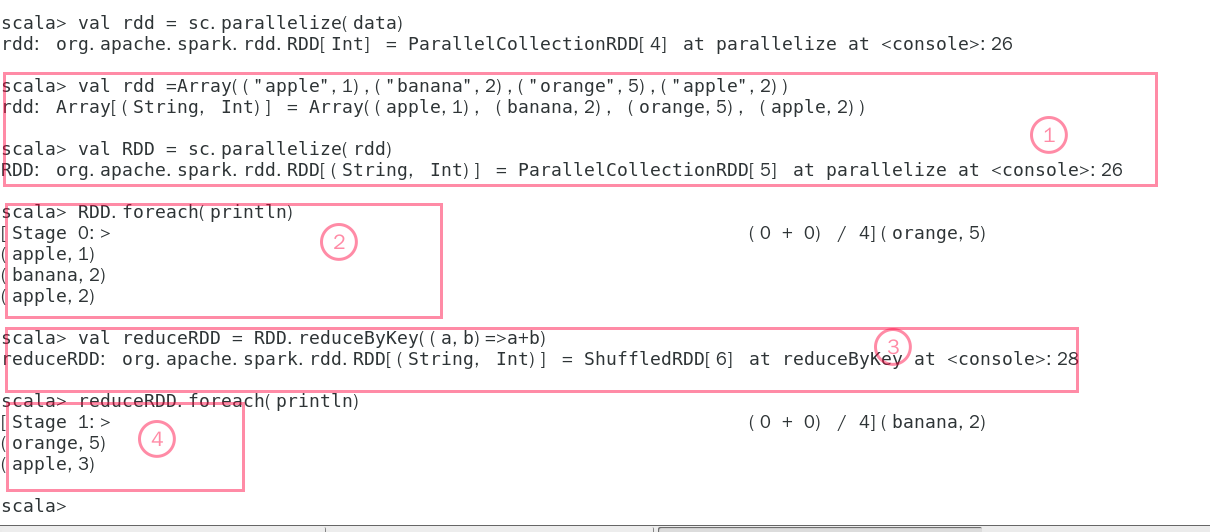
1:首先使用parallelize()方法创建RDD 《key,value》
2:然后进行显示创建的结果
3:将key之相同的集合进行合并,a和b代表value
4:将处理后的集过进行显示
2.2 groupByKey()演示

1:原来的RDD显示
2:进行groupByKey操作
3:显示新的RDD
2.3 keys演示

1:原来的RDD
2:进行keys转换
3:显示keys
2.4 values显示

1:显示原来的RDD
2:进行values操作
2:显示新的RDD
2.5 mapValues(func)演示
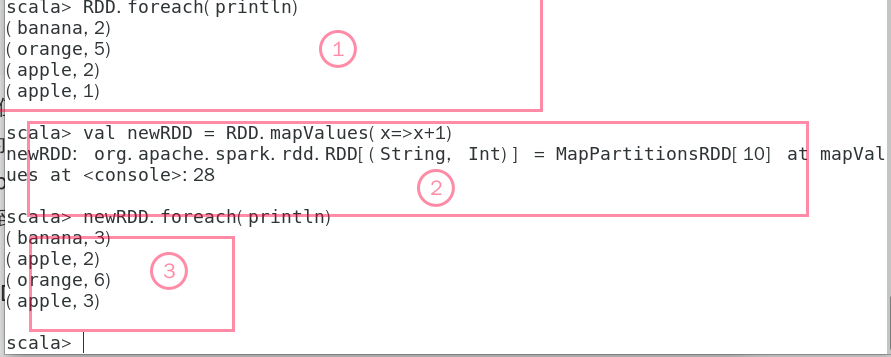
1:原来的RDD显示
2:进行mapValue操作
3:显示新的RDD
2.6 join操作
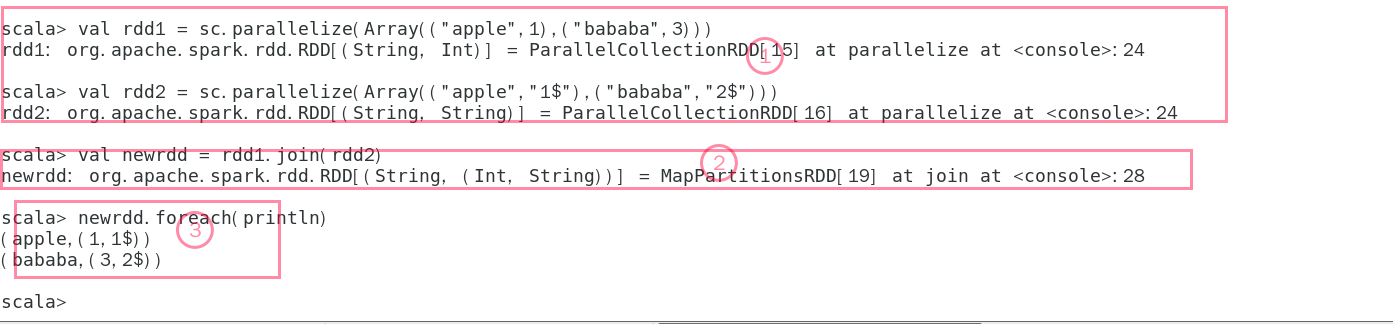
1:创建两个RDD
2:进行join操作
2:显示新的RDD
3 持久化
RDD惰性机制:当进行RDD转换时必不会进行实际的操作,只有遇到行动时才会触发真正的执行。如果遇到大量行动操作,每次行动都需要从头开始会付出很大代价,通过持久化(缓存)机制避免这种重复计算的开销。
使用persist()方法对一个RDD标记为持久化,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化,持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用。
4 广播变量
每个阶段内的所有任务所需要的公共数据,Spark都会自动进行广播。通过广播方式进行传播的变量,会经过序列化,然后在被任务使用时再进行反序列化。

1:创建广播变量
2:读取广播变量的值
5 累加器
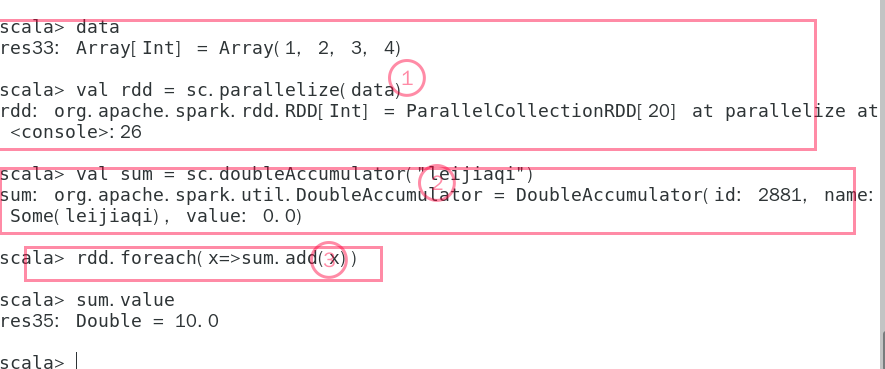
1:创建RDD
2:创建累加器
3:进行累加
4:显示累加器的值
最后
以上就是神勇枕头最近收集整理的关于RDD编程的全部内容,更多相关RDD编程内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。

![[Spark]-源码解析-RDD的五大特征体现](https://www.shuijiaxian.com/files_image/reation/bcimg7.png)






发表评论 取消回复