想要更全面了解Spark内核和应用实战,可以购买我的新书。
《图解Spark 大数据快速分析实战》(王磊))
Spark数据写出过程
1.Spark文件写出原则(temporary机制)
Spark文件的写出是利用temporary机制来完成的,具体需要遵守三条原则。
(1)每个作业对应的文件夹都是相互独立的临时(temporary)目录。
(2)作业中的每个任务对应的文件夹也是相互独立的临时(temporary)目录。
(3)数据写完后,就将临时(temporary)目录修改为最终目录,这在HDFS中是通过move命令来实现的,如图所示。
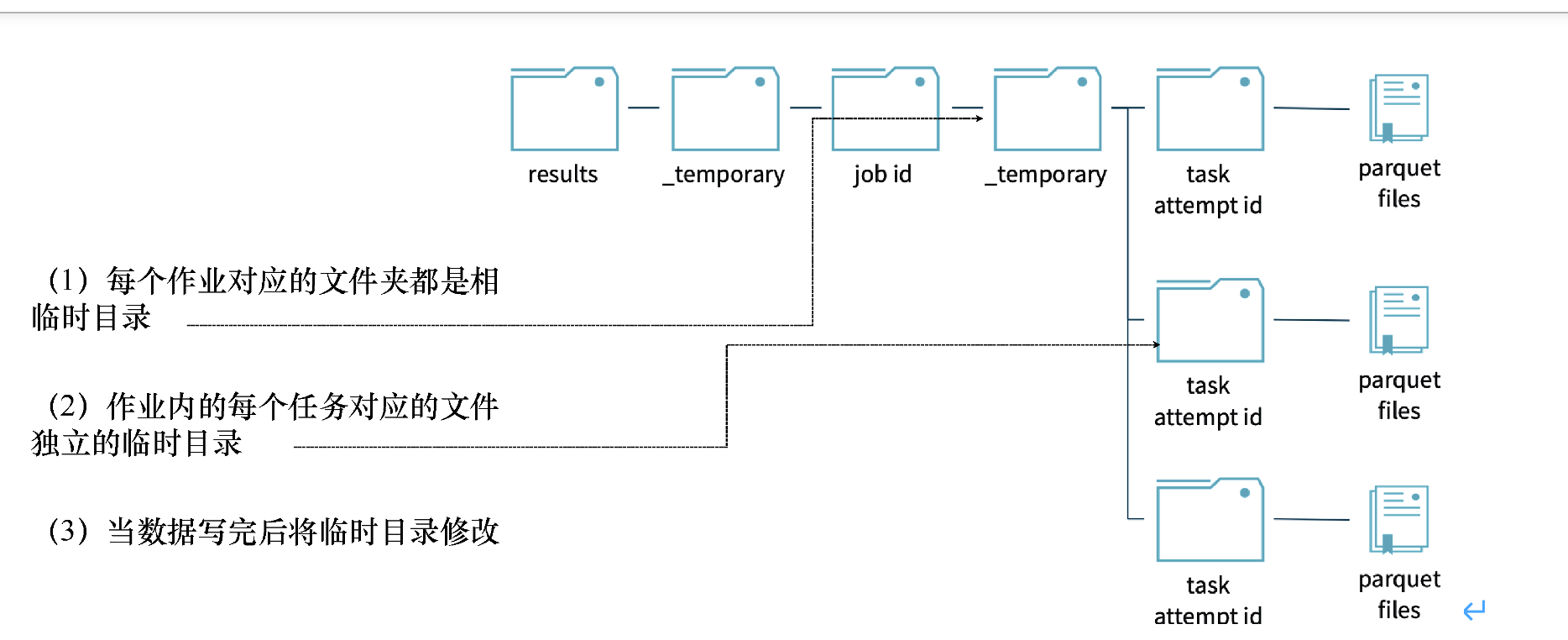
图Spark基于temporary机制来实现文件的写出
下面详细介绍Spark利用temporary机制将文件写出的过程。
2.Spark按照分区将数据写出的过程
Spark在写出数据的时候,会根据分区为每个分区分配一个任务并将文件以并行方式写出;Spark在写出文件的时候,会为每个任务建立一个临时目录并将数据写到这个临时目录中;等到所有任务的写操作都完成时,Spark会将临时目录以文件移到方式修改为最终目录。具体的流程如图所示。
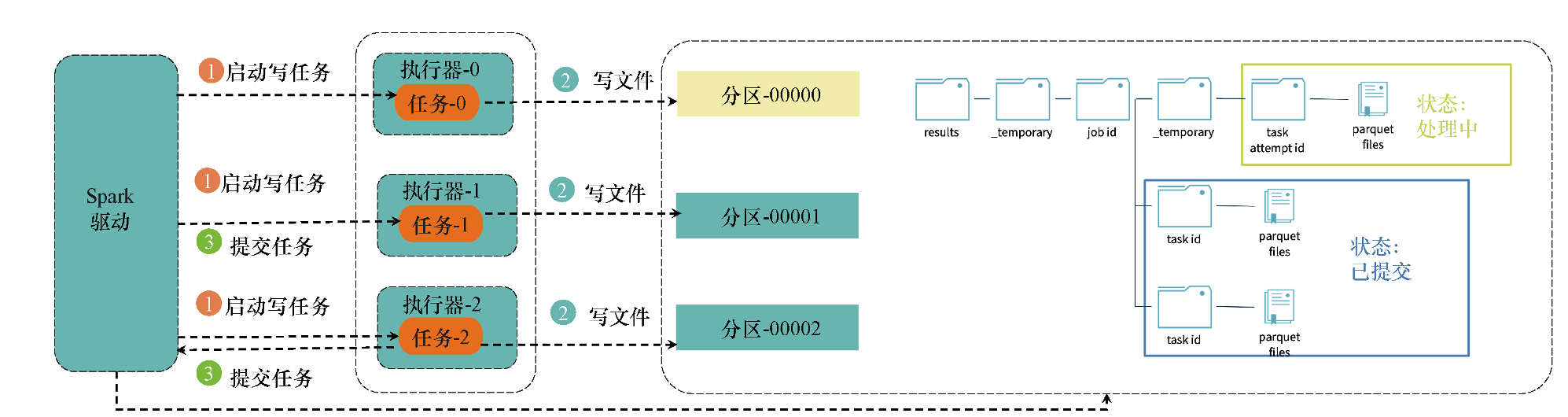
图 Spark文件的写出流程
(1)Spark启动写任务。
(2)对于每个任务,并行地将数据写入临时文件。
(3)写操作完成后,提交任务到Spark驱动节点,这表示写任务已经完成。
(4)当Spark驱动节点接收到所有写任务的“写成功”状态后,便认为所有的写文件操作都已经完成,于是提交写文件作业,并将临时目录以文件移到方式修改为最终目录,这样写文件的过程就完成了。
3.在写任务失败时重试
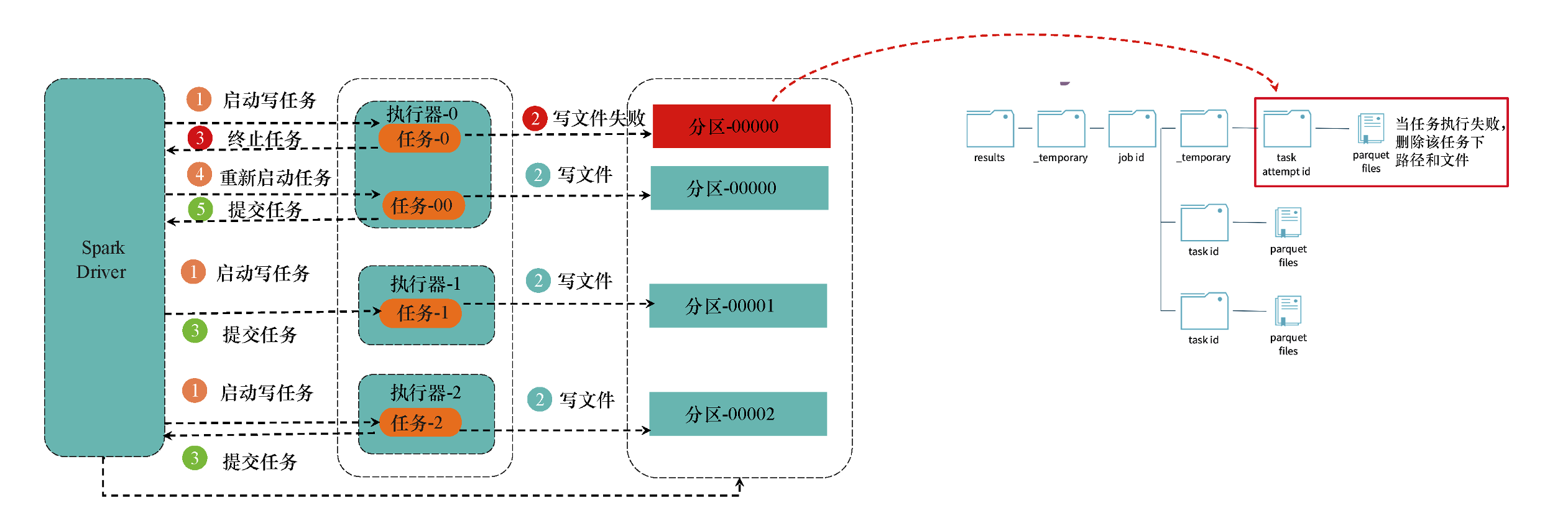
在写TB级别的文件时,由于网络原因,磁盘资源不足的问题经常会导致某些写任务失败。在这种情况下,Spark如何保障写任务失败情况下的容错性和数据最终的一致性呢?具体过程如下:当Spark中的某个写任务失败时,就向Spark驱动节点发出终止任务的请求,同时删除写路径下的文件;然后重新启动一个写任务,在新的写任务完成后,再次提交任务;当所有写任务完成后,Spark驱动节点就会提交作业,并将临时目录修改为最终目录;如图所示。
最后
以上就是背后柚子最近收集整理的关于Spark分布式数据写出原理的全部内容,更多相关Spark分布式数据写出原理内容请搜索靠谱客的其他文章。








发表评论 取消回复