文章目录
- 概述
- 1. RDD存储相关概念
- 1.1 RDD分区和数据块的关系
- 1.1.1 问题说明
- 1.1.2 关系说明
- 1.1.3 数据块与分区映射约定方式
- 2. RDD持久化机制
- 2.1 RDD持久化种类
- 3. RDD 缓存过程
- 4. 淘汰和落盘
- 4.1 淘汰
- 4.2 落盘
- 总结
- 致谢
概述
介绍存储内存的管理。主要讲解RDD在存储内存中的持久化。
在Spark内存管理之堆内/堆外内存原理详解一文中,我们可以知道,无论是on-heap还是off-heap,都存在storage内存,主要用于存储 spark 的 cache 数据,例如RDD的缓存、unroll数据等等。
本文将主要从RDD持久化过程来说明Storage Memory如何发挥效用。
1. RDD存储相关概念
RDD的基础概念请参考Spark RDD运行原理、Spark RDD之Partition、Spark RDD之Partitioner、Spark RDD之Dependency等文章。这里主要是介绍RDD存储相关的知识。
1.1 RDD分区和数据块的关系
1.1.1 问题说明
对于RDD的各种操作:如transform、action,我们将操作函数施行于RDD之上,而最终这些操作都将施行于每一个分区之上,因此可以这么说,在RDD上的所有运算都是基于分区的。在Storage模块内,对于数据的存取都是以数据块为单位进行的。很少会接触到RDD。
事实上,分区是一个逻辑上的概念,而数据块是物理上的数据实体,我们操作的分区和数据块,它们两者之间有什么关系呢?
1.1.2 关系说明
在Spark中,分区和数据块是一一对应的,一个RDD中的一个Partition对应着BlockManager中的一个Block。
Task执行结果就是生成了目标RDD的一个Partiton,如果要求缓存,就会以Block的形式存储到了本地的BlockManager上(参见Spark DAG之SubmitTask中的Task介绍)。因此BlockManager接触不到也并不关心RDD,它只关心数据块,对于Block和Partition之间的映射则是通过名称上的约定进行的。
1.1.3 数据块与分区映射约定方式
这种名称上的约定是按如下方式建立的:
- Spark为每一个RDD在其内部维护了独立的ID号
- 对于RDD的每一个分区也有一个独立的索引号
因此,“RddID+Partition索引号”就能全局唯一地确定这个分区。这样以“RddID+Partition索引号”作为块的名称就自然地建立起了分区和块的映射。即:
映射方式:BlockID = RddID+Partition索引号
在显示调用调用函数缓存我们所需的RDD时,Spark在其内部就建立了RDD分区和数据块之间的映射而当我们需要读取缓存的RDD时,根据上面所提到的映射关系,就能从存储管理模块中取得分区对应的数据块。下图展示了RDD分区与数据块之间的映射关系。- 事实上,BlockId的格式为
rdd_RDD-ID_PARTITION-ID,如下,均以rdd开头,用以标识这是存储的是RDD数据。
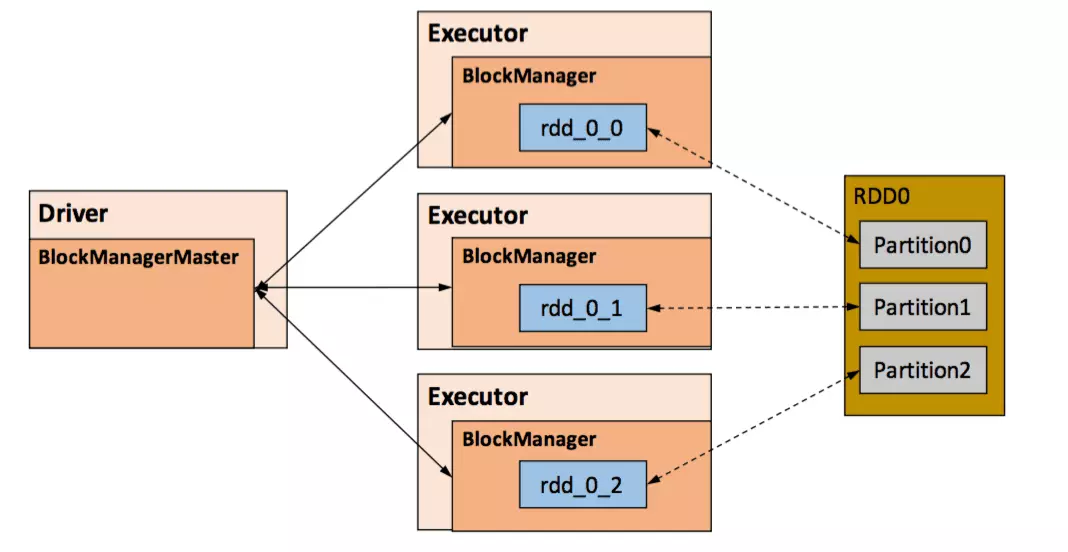
说明:rdd是固定的,第二位上的{0,0,0},是因为这些都是RDD0,也就是RDD的ID是0;第三位上的{0,1,2},便对应了Partition0,1,2。
2. RDD持久化机制
- 弹性分布式数据集(RDD)作为Spark最根本的数据抽象,是只读的分区记录(Partition)的集合,只能基于在稳定物理存储中的数据集上创建,或者在其他已有的RDD上执行转换(Transformation)操作产生一个新的RDD。
- 转换后的RDD与原始的RDD之间产生的依赖关系,构成了血统(Lineage)。凭借血统,Spark保证了每一个RDD都可以被重新恢复。
- 但RDD的所有转换都是惰性的,即只有当一个返回结果给Driver的行动(Action)发生时,Spark才会创建任务读取RDD,然后真正触发转换的执行。
- Task在启动之初读取一个分区时,会先判断这个分区是否已经被持久化,如果没有则需要检查Checkpoint或按照血统重新计算。
- 所以如果一个RDD上要执行多次action,可以在第一次行动中使用
persist或cache方法,在内存或磁盘中持久化或缓存这个RDD,从而在后面的行动时提升计算速度。 - 事实上,cache方法是使用默认的
MEMORY_ONLY的存储级别将RDD持久化到内存,故缓存是一种特殊的持久化。 - 堆内和堆外存储内存的设计,便可以对缓存RDD时使用的内存做统一的规划和管理(存储内存的其他应用场景,如缓存broadcast数据,暂时不在本文的讨论范围之内)。
- RDD的持久化由Spark的Storage模块负责,实现了RDD与物理存储的解耦合。Storage模块负责管理Spark在计算过程中产生的数据,将那些在内存或磁盘、在本地或远程存取数据的功能封装了起来。(参见Spark存储管理之Storage模块解析)
2.1 RDD持久化种类
在对RDD持久化时,Spark规定了MEMORY_ONLY、MEMORY_AND_DISK等7种不同的存储级别,而存储级别是以下5个变量的组合[2]:
class StorageLevel private(
private var _useDisk: Boolean, //磁盘
private var _useMemory: Boolean, //这里其实是指堆内内存
private var _useOffHeap: Boolean, //堆外内存
private var _deserialized: Boolean, //是否为非序列化
private var _replication: Int = 1 //副本个数
)
通过对数据结构的分析,可以看出存储级别从三个维度定义了RDD的Partition(同时也就是Block)的存储方式:
| 维度 | 分类 | 说明 |
|---|---|---|
存储位置 | 磁盘 堆内内存 堆外内存 | 如MEMORY_AND_DISK是同时在磁盘和堆内内存上存储,实现了冗余备份。 OFF_HEAP则是只在堆外内存存储,目前选择堆外内存时不能同时存储到其他位置。 |
存储形式 | Block缓存到Storage Memory中 序列化/非序列化 | 如MEMORY_ONLY是非序列化方式存储,OFF_HEAP是序列化方式存储 |
副本数量 | 大于1时需要远程冗余备份到其他节点。如DISK_ONLY_2需要远程备份1个副本。 |
| 储存量 |
|
|---|---|
MEMORY_ONLY | 将RDD作为反序列化的Java对象存储在JVM中。如果RDD不能容纳在内存中,则某些分区将不会被缓存,并且每次需要时都会即时重新计算。这是默认级别。 |
MEMORY_AND_DISK | 将RDD作为反序列化的Java对象存储在JVM中。如果RDD不能容纳在内存中,请存储磁盘上不适合的分区,并在需要时从那里读取它们。 |
MEMORY_ONLY_SER (Java和Scala) | 将RDD存储为序列化的 Java对象(每个分区一个字节数组)。通常,这比反序列化的对象更节省空间,尤其是在使用快速序列化程序时,但读取时会占用 更多CPU。 |
MEMORY_AND_DISK_SER(Java和Scala) | 与MEMORY_ONLY_SER类似,但是将内存中不适合的分区溢出到磁盘上,而不是在需要时即时对其进行重新计算。 |
DISK_ONLY | 仅将RDD分区存储在磁盘上。 |
MEMORY_ONLY_2MEMORY_AND_DISK_2等 | 与上面的级别相同,但是在两个群集节点上复制每个分区。 |
OFF_HEAP(实验性) | 与MEMORY_ONLY_SER类似,但是将数据存储在 堆外内存中。这需要启用堆外内存。 |
3. RDD 缓存过程
-
RDD在缓存到存储内存之前,Partition中的数据一般以迭代器(Iterator)的数据结构来访问,这是Scala语言中一种遍历数据集合的方法。通过Iterator可以获取分区中每一条序列化或者非序列化的数据项(Record),这些Record的对象实例在逻辑上占用了JVM堆内内存的other部分的空间,同一Partition的不同Record的空间并不连续。 -
RDD在缓存到存储内存之后,Partition被转换成Block,Record在堆内或堆外存储内存中占用一块连续的空间。将Partition由不连续的存储空间转换为连续存储空间的过程,Spark称之为“展开”(Unroll)。Block有序列化和非序列化两种存储格式,具体以哪种方式取决于该RDD的存储级别。
- 非序列化的Block以一种DeserializedMemoryEntry的数据结构定义,用一个数组存储所有的Java对象
- 序列化的Block则以SerializedMemoryEntry的数据结构定义,用字节缓冲区(ByteBuffer)来存储二进制数据。 -
每个Executor的Storage模块用一个链式Map结构(LinkedHashMap)来管理堆内和堆外存储内存中所有的Block对象的实例,对这个LinkedHashMap新增和删除间接记录了内存的申请和释放。
-
因为不能保证存储空间可以一次容纳Iterator中的所有数据,当前的计算任务在Unroll时要向MemoryManager申请足够的Unroll空间来临时占位,空间不足则Unroll失败,空间足够时可以继续进行。
- 对于序列化的Partition,其所需的Unroll空间可以直接累加计算,一次申请。
- 而非序列化的Partition,则要在遍历Record的过程中依次申请,即每读取一条Record,采样估算其所需的Unroll空间并进行申请,空间不足时可以中断,释放已占用的Unroll空间。
-
如果最终Unroll成功,当前Partition所占用的Unroll空间被转换为正常的缓存RDD的存储空间,如下图2所示。
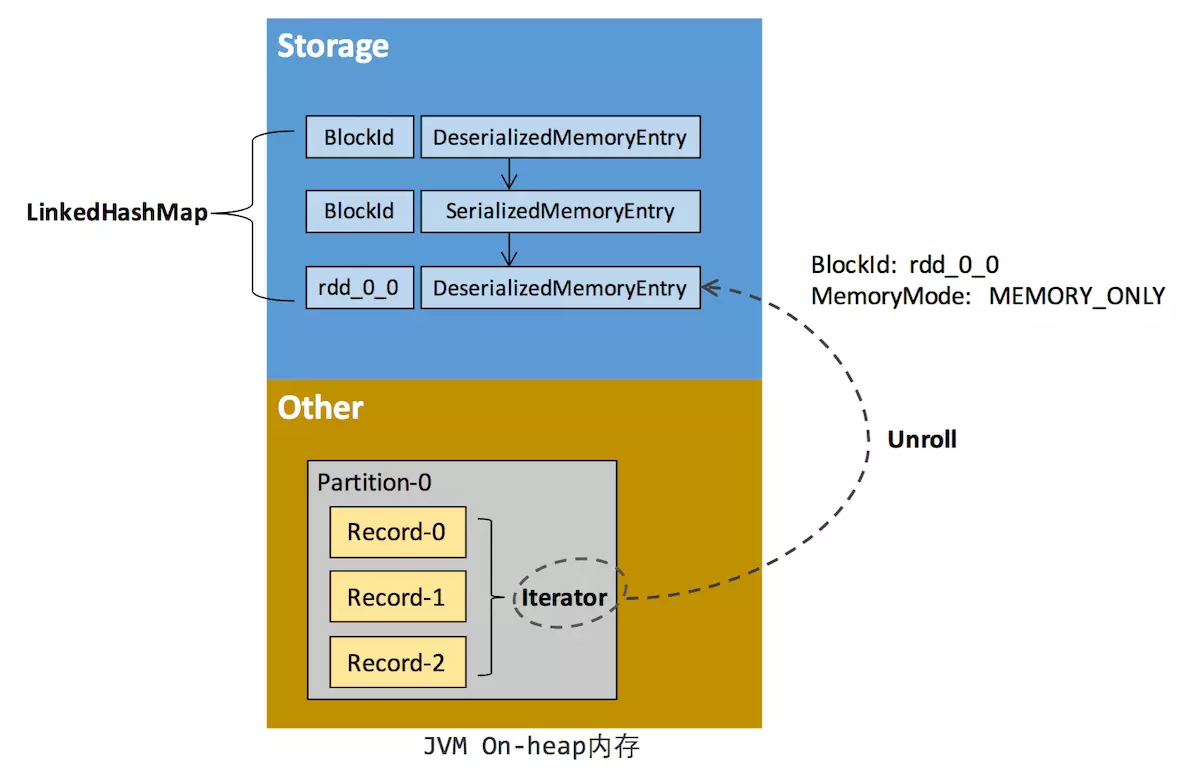
在Spark内存管理之堆内/堆外内存原理详解中可以看到,在静态内存管理方式时,Spark在存储内存中专门划分了一块Unroll空间,其大小是固定的,统一内存管理方式时则没有对Unroll空间进行特别区分,当存储空间不足是会根据动态占用机制进行处理。
4. 淘汰和落盘
当以默认或者基于内存的持久化方式缓存RDD时,RDD中的每一分区所对应的数据块是会被存储管理模块中的内存缓存(Memory Store)所管理的。内存缓存在其内部维护了一个以数据块名为键,块内容为值的哈希表。
在内存缓存中有一个重要的问题是,当内存不是或是已经到达所设置的阈值时应如何处理。在Spark中对于内存缓存可使用的内存阈值有这样一个配置:spark.storage.memoryFraction。默认情况下是0.6,也就是说JVM内存的60%可被内存缓存用来存储块内容。当我们存储的数据块所占用的内存大于60%时,Spark会采取一些策略释放内存缓存空间:丢弃一些数据块,或是将一些数据块存储到磁盘上以释放内存缓存空间。
4.1 淘汰
由于同一个Executor的所有的计算任务共享有限的存储内存空间,当有新的Block需要缓存但是剩余空间不足且无法动态占用时,就要对LinkedHashMap中的旧Block进行淘汰(Eviction)。存储内存的淘汰规则为:
- 被淘汰的旧Block要与新Block的
MemoryMode相同,即同属于堆外或堆内内存 - 新旧Block
不能属于同一个RDD,避免循环淘汰
旧Block所属RDD不能处于被读状态,避免引发一致性问题 - 遍历LinkedHashMap中Block,按照最近
最少使用(LRU)的顺序淘汰,直到满足新Block所需的空间。其中LRU是LinkedHashMap的特性。
4.2 落盘
而被淘汰的Block如果其存储级别中同时包含存储到磁盘的要求,则要对其进行落盘(Drop),否则直接删除该Block。落盘的流程则比较简单:
- 如果其存储级别符合
_useDisk为true的条件,再根据其_deserialized判断是否是非序列化的形式,若是则对其进行序列化,最后将数据存储到磁盘,在Storage模块中更新其信息。
那么直接删除是否会影响Spark程序的错误恢复机制呢?
这取决于依赖关系的可回溯性,若该RDD所依赖的祖先RDD是可被回溯并可用的,那么该RDD所对应的块被删除是不会影响错误恢复的。反之,若该RDD已经是祖先RDD,且数据已无法被回溯到,那么程序就会出错。
总结
从上面的介绍可以看出,内存缓存对于数据块的管理是非常简单的,本质上就是一个哈希表加上一些存取策略。
致谢
- Spark内存管理详解(下)——内存管理
- Spark存储管理(读书笔记)
- RDD Persistence
最后
以上就是欢喜白猫最近收集整理的关于Spark内存管理之存储内存管理概述1. RDD存储相关概念2. RDD持久化机制3. RDD 缓存过程4. 淘汰和落盘总结致谢的全部内容,更多相关Spark内存管理之存储内存管理概述1.内容请搜索靠谱客的其他文章。








发表评论 取消回复