文档查看地址:http://flume.apache.org/FlumeUserGuide.html
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。
Flume的作用就是实时读取服务器本地磁盘的数据,并将数据写入HDFS中
1. 架构
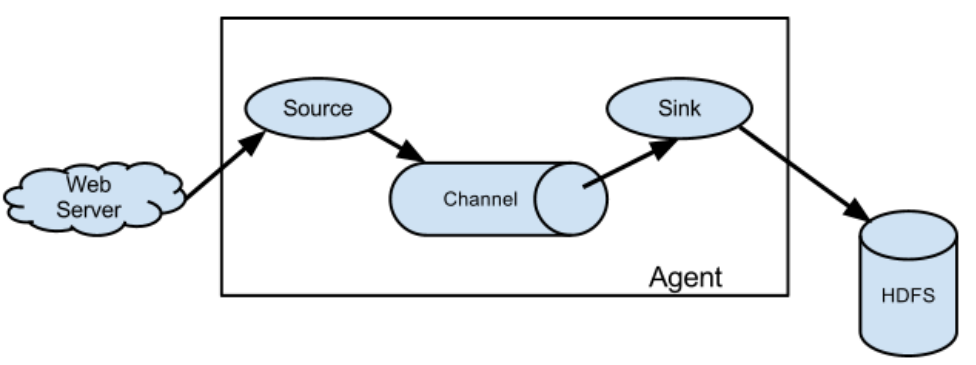
名词解释:
-
Agent:Agent是一个JVM进程,它以事件的形式将数据从源头送至目的。Agent主要有3个部分组成,Source、Channel、Sink。
-
Source:Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。
-
Channel:Channel是位于Source和Sink之间的缓冲区。从Source采集的数据会被封装成一个event,然后将event放入channel中,供sink读取。
因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。Flume自带两种Channel:Memory Channel(内存中的队列,在程序死亡,机器宕机的情况下会丢失数据)和File Channel(所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据)。 -
Sink:Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink组件目的地包括hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定义。
-
Event:传输单元,Flume数据传输的基本单元,以Event的形式将数据从源头送至目的地。Event由Header和Body两部分组成,Header用来存放该event的一些属性,为K-V结构,Body用来存放该条数据,形式为字节数组。
-
Interceptors:在source将event放入到channel之前,调用拦截器对event进行拦截和处理!Flume支持拦截器链,即由多个拦截器组合而成!通过指定拦截器链中拦截器的顺序,event将按照顺序依次被拦截器进行处理!
-
Channel Selectors:Channel Selectors用于source组件将event传输给多个channel的场景。常用的有replicating(默认)和multiplexing两种类型。replicating负责将event复制到多个channel,而multiplexing则根据event的属性和配置的参数进行匹配,匹配成功则发送到指定的channel!
-
Sink Processors:用户可以将多个sink组成一个整体(sink组),Sink Processors可用于提供组内的所有sink的负载平衡功能,或在时间故障的情况下实现从一个sink到另一个sink的故障转移。一般情况下,当多个sink从一个channel取数据时,为了保证数据的顺序,由sink processor从多个sink中挑选一个sink,由这个sink干活!
2. 安装
下载地址:http://archive.apache.org/dist/flume/
1. 下载apache-flume-1.9.0-bin.tar.gz包,上传到服务器,并解压
2. 配置flume的环境变量
3. 保证有JAVA_HOME
4. 查看版本:flume-ng version
5. 运行flume
flume-ng agent -c 配置文件所在的目录 -n agent的名称 -f agent配置文件 -Dproperty=value3. 简单案例
3.1 实时监控端口数据
参考博客: https://blog.csdn.net/weixin_42063239/article/details/88362390
3.2 实时监控单个文件
需求:实时监控Hive日志,并上传到HDFS中
做法:使用EXEC SOURCE
Execsouce的缺点:execsource和异步的source一样,无法做到在source向channel中放入event突发故障时,及时通知客户端,暂停生成数据,容易造成数据丢失!如果希望数据有强的可靠性保证,可以考虑使用SpoolingDirSource或TailDirSource或自己写Source自己控制!
可查看博客:https://blog.csdn.net/qq_41338249/article/details/101420440
3.3 监控多个文件
3.3.1 SpoolingDirSource
SpoolingDirSource用于监听多个新文件。
SpoolingDirSource指定本地磁盘的一个目录为"Spooling(自动收集)"的目录!这个source可以读取目录中新增的文件,将文件的内容封装为event! SpoolingDirSource在读取一整个文件到channel之后,它会采取策略,要么删除文件(是否可以删除取决于配置),要么对文件进程一个完成状态的重命名,这样可以保证source持续监控新的文件!SpoolingDirSource和execsource不同,SpoolingDirSource是可靠的!即使flume被杀死或重启,依然不丢数据!但是为了保证这个特性,付出的代价是,一旦flume发现以下情况,flume就会报错,停止!
①一个文件已经被放入目录,在采集文件时,不能被修改
②文件的名在放入目录后又被重新使用(出现了重名的文件)
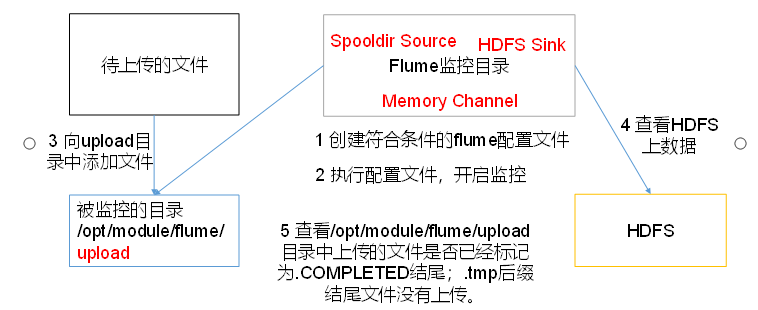
1. 创建配置文件flume-dir-hdfs.conf(文件名自定义),并放入FLUME_HOME/conf文件夹中
#a1是agent的名称,a1中定义了一个叫r1的source,如果有多个,使用空格间隔
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#组名.属性名=属性值,使用SpoolingDirSource时,type属性必须为spooldir
#spoolDir表示SpoolingDirSource监控哪个目录读取文件
a1.sources.r1.type=spooldir
a1.sources.r1.spoolDir=/usr/local/workspace/flume/upload
#忽略所有以.tmp结尾的文件,不上传
a1.sources.r1.ignorePattern=\S*\.tmp
#source处理完成后的文件自动添加的完成标识即文件名后缀
a1.sources.r1.fileSuffix=.COMPLETED
#定义chanel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
#定义sink
a1.sinks.k1.type=hdfs
#一旦路径中含有基于时间的转义序列,要求event的header中必须有timestamp=时间戳,如果没有需要设置useLocalTimeStamp=true
a1.sinks.k1.hdfs.path=hdfs://hadoop101:9000/flume/%Y%m%d/%H/%M
#上传文件的前缀
a1.sinks.k1.hdfs.filePrefix=logs-
#以下三个和目录的滚动相关,目录一旦设置了时间转义序列,基于时间戳滚动
#是否将时间戳向下舍
a1.sinks.k1.hdfs.round=true
#多少时间单位创建一个新的文件夹
a1.sinks.k1.hdfs.roundValue=1
#重新定义时间单位
a1.sinks.k1.hdfs.roundUnit=minute
#是否使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp=true
#积攒多少个Event才flush到HDFS一次
a1.sinks.k1.hdfs.batchSize=100
#以下三个和文件的滚动相关,以下三个参数是或的关系!以下三个参数如果值为0都代表禁用!
#30秒滚动生成一个新的文件
a1.sinks.k1.hdfs.rollInterval=30
#设置每个文件到128M时滚动
a1.sinks.k1.hdfs.rollSize=134217700
#每写多少个event滚动一次,0表示不配置此项,文件的滚动与Event数量无关
a1.sinks.k1.hdfs.rollCount=0
#以不压缩的文本形式保存数据
a1.sinks.k1.hdfs.fileType=DataStream
#连接组件 同一个source可以对接多个channel,一个sink只能从一个channel拿数据!绑定source和sink到channel
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
2. 指定配置文件并启动flume
# -n表示指定agent名称,由于我们配置文件中使用的a1,所以这里也写a1
# -c 指定flume的配置文件目录, -f指定配置文件, -c 和-f 是没有关系的,各自配置各自地址
flume-ng -n a1 agent -c /usr/local/workspace/flume/conf/ -f /usr/local/workspace/flume/conf/flume-spooldir-source.conf -Dflume.root.logger=DEBUG,console3. 上传文件测试
向SpoolingDirSource监控的目录(/usr/local/workspace/flume/upload)插入文件h.txt,插入完成,等待上传至HDFS,再次查看upload中的文件,发现文件名已被重命名为h.txt.COMPLETED,且成功上传至HDFS上
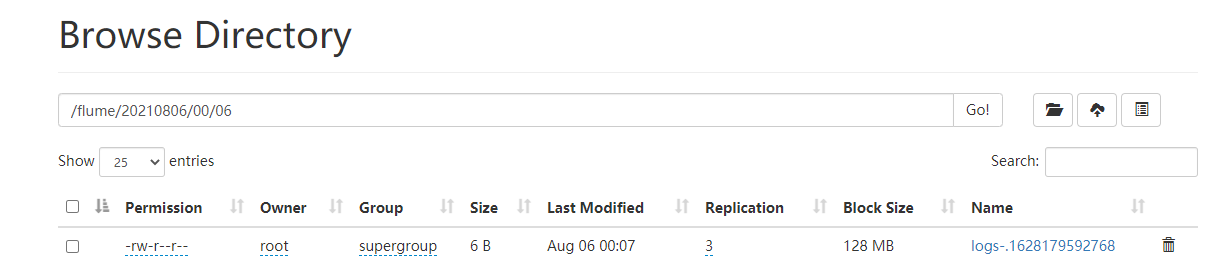
4. 遇到的bug
版本信息:我的hadoop版本为3.1.4,flume版本为1.9
说明:当我向SpoolingDirSource监控的目录插入文件后,预期结果应该是正确将文件上传至HDFS的flume目录,但是此时却报错了:
2021-08-05 23:53:47,350 ERROR hdfs.HDFSEventSink: process failed
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1357)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338)
at org.apache.hadoop.conf.Configuration.setBoolean(Configuration.java:1679)
at org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:221)
at org.apache.flume.sink.hdfs.BucketWriter.append(BucketWriter.java:572)
at org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:412)
at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:67)
at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:145)
at java.lang.Thread.run(Thread.java:748)
Exception in thread "SinkRunner-PollingRunner-DefaultSinkProcessor" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1357)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338)
at org.apache.hadoop.conf.Configuration.setBoolean(Configuration.java:1679)
at org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:221)
at org.apache.flume.sink.hdfs.BucketWriter.append(BucketWriter.java:572)
at org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:412)
at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:67)
at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:145)
at java.lang.Thread.run(Thread.java:748)
原因猜测:flume lib下的guava包可能跟hadoop的guava包冲突了
解决办法:删除flume下的guava包,或者将hadoop中的guava包中复制一份到flume中
3.3.2 TailDirSource

- Taildir Source在工作时,会将读取文件的最后的位置记录在一个json文件中,一旦agent重启,会从之前已经记录的位置,继续执行tail操作!所以它相对于SpoolingDirSource可以读取多个文件最新追加写入的内容!
- Taildir Source是可靠的,即使flume出现了故障或挂掉。
- Json文件中,位置是可以修改,修改后,Taildir Source会从修改的位置进行tail操作!如果JSON文件丢失了,此时会重新从每个文件的第一行,重新读取,这会造成数据的重复!
- Taildir Source目前只能读文本文件!
常见问题: TailDirSource采集的文件,不能随意重命名!如果日志在正在写入时,名称为 xxxx.tmp,写入完成后,滚动,改名为xxx.log,此时一旦匹配规则可以匹配上述名称,就会发生数据的重复采集!
配置文件:
#a1是agent的名称,a1中定义了一个叫r1的source,如果有多个,使用空格间隔
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#组名名.属性名=属性值
a1.sources.r1.type=TAILDIR
a1.sources.r1.filegroups=f1 f2
a1.sources.r1.filegroups.f1=/usr/local/workspace/flume/a.txt
a1.sources.r1.filegroups.f2=/usr/local/workspace/flume/b.txt
#a1.sources.r1.positionFile=/usr/local/workspace/tail-json/taildir_position.json
#定义sink
#sink将获取的数据打印到控制台上
a1.sinks.k1.type=logger
a1.sinks.k1.maxBytesToLog=100
#定义chanel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
#连接组件 同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
注意:配置中定义的f1和f2均是文件,而不是文件夹,配置文件夹是无法监听的,一个filegroup想监听多个文件,可写正则表达式来匹配文件
4. Agent内部原理
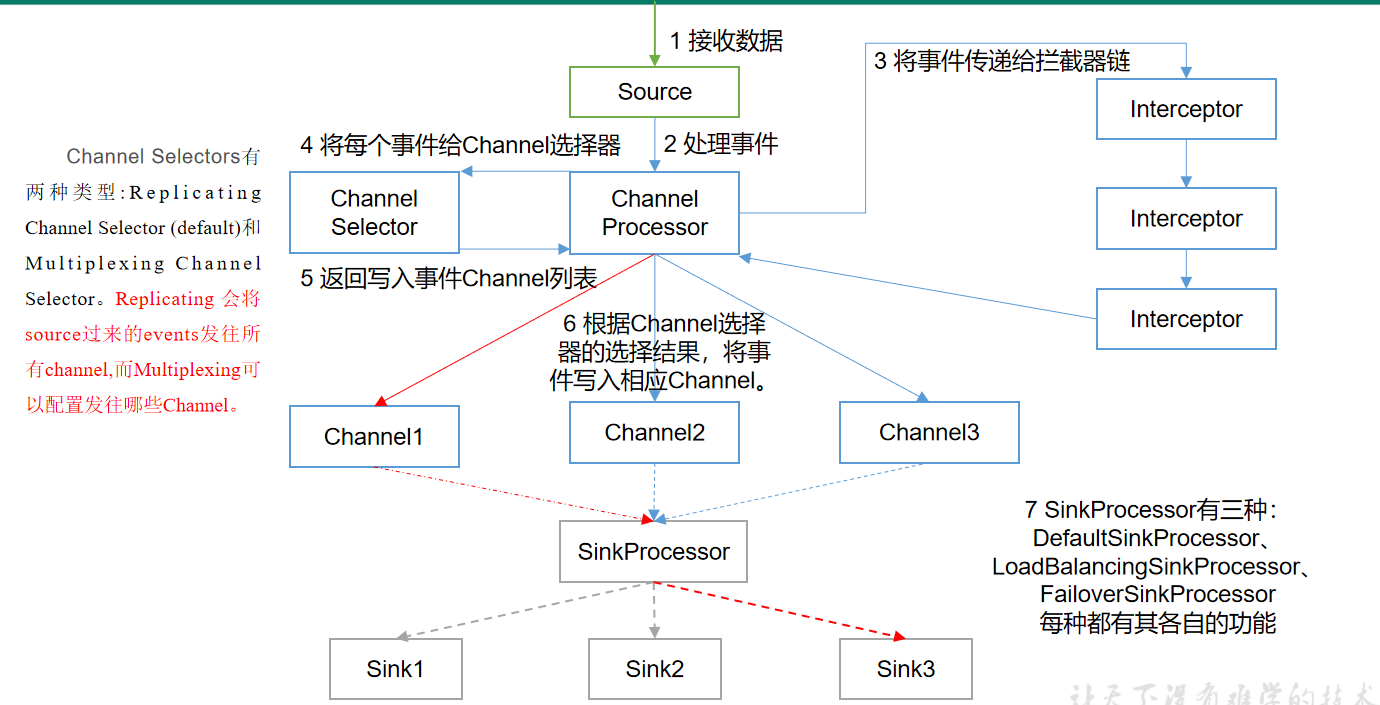
ChannelSelector:
ChannelSelector的作用就是选出Event将要被发往哪个Channel。其共有两种类型,分别是Replicating(复制)和Multiplexing(多路复用)。
ReplicatingSelector会将同一个Event发往所有的Channel,Multiplexing会根据相应的原则,将不同的Event发往不同的Channel。
SinkProcessor
SinkProcessor有以下三种:
1.Default Sink Processor:如果agent中,只有一个sink,默认就使用Default Sink Processor,这个sink processor是不强制用户将sink组成一个组。如果有多个sink,多个sink对接一个channel,不能选择Default Sink Processor。
2.Failover Sink Processor: 维护了一个多个sink的有优先级的列表,按照优先级保证,至少有一个sink是可以干活的!如果根据优先级发现,优先级高的sink故障了,故障的sink会被转移到一个故障的池中冷却!在冷却时,故障的sink也会不管尝试发送event,一旦发送成功,此时会将故障的sink再移动到存活的池中!
3.Load balancing Sink Processor:负载均衡的sink processor! Load balancing Sink Processor维持了sink组中active状态的sink!使用round_robin 或 random 算法,来分散sink组中存活的sink之间的负载!
5. Flume的拓扑结构
如果AgentA需要将Event对象发送到其他的agent进程中!那么 AgentA的sink必须为AvroSink,其他的agent在接收时,必须选择AvroSource!注意两个flume之间传输的是event,传输时使用的序列化方式。
5.1 简单串联
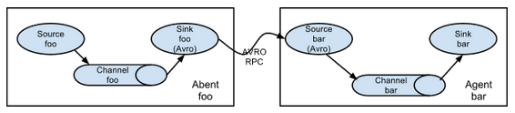
将多个flume顺序连接起来了,从最初的source开始到最终sink传送的目的存储系统。此模式不建议桥接过多的flume数量, flume数量过多不仅会影响传输速率,而且一旦传输过程中某个节点flume宕机,会影响整个传输系统。
需求:agent1监听主机hadoop101的44444端口收集数据,然后将数据传输到agent2主机为hadoop102的33333
配置文件如图所示:
agent1
#a1是agent的名称,a1中定义了一个叫r1的source,如果有多个,使用空格间隔
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#组名名.属性名=属性值
a1.sources.r1.type=netcat
a1.sources.r1.bind=hadoop101
a1.sources.r1.port=44444
#定义sink
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=hadoop102
a1.sinks.k1.port=33333
#定义chanel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
#连接组件 同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
--------------------------------------------------------
#agent2
#a1是agent的名称,a1中定义了一个叫r1的source,如果有多个,使用空格间隔
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#组名名.属性名=属性值
a1.sources.r1.type=avro
a1.sources.r1.bind=hadoop102
a1.sources.r1.port=33333
#定义sink
a1.sinks.k1.type=logger
#定义chanel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
#连接组件 同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c15.2 复制和多路复用
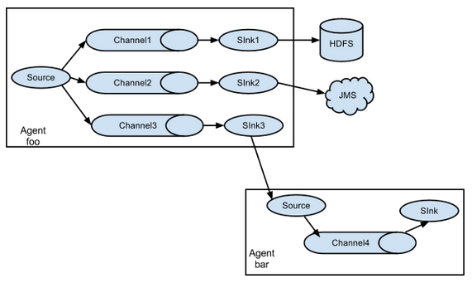
Flume支持将事件流向一个或者多个目的地。这种模式可以将相同数据复制到多个channel中,或者将不同数据分发到不同的channel中,sink可以选择传送到不同的目的地。
5.3 聚合
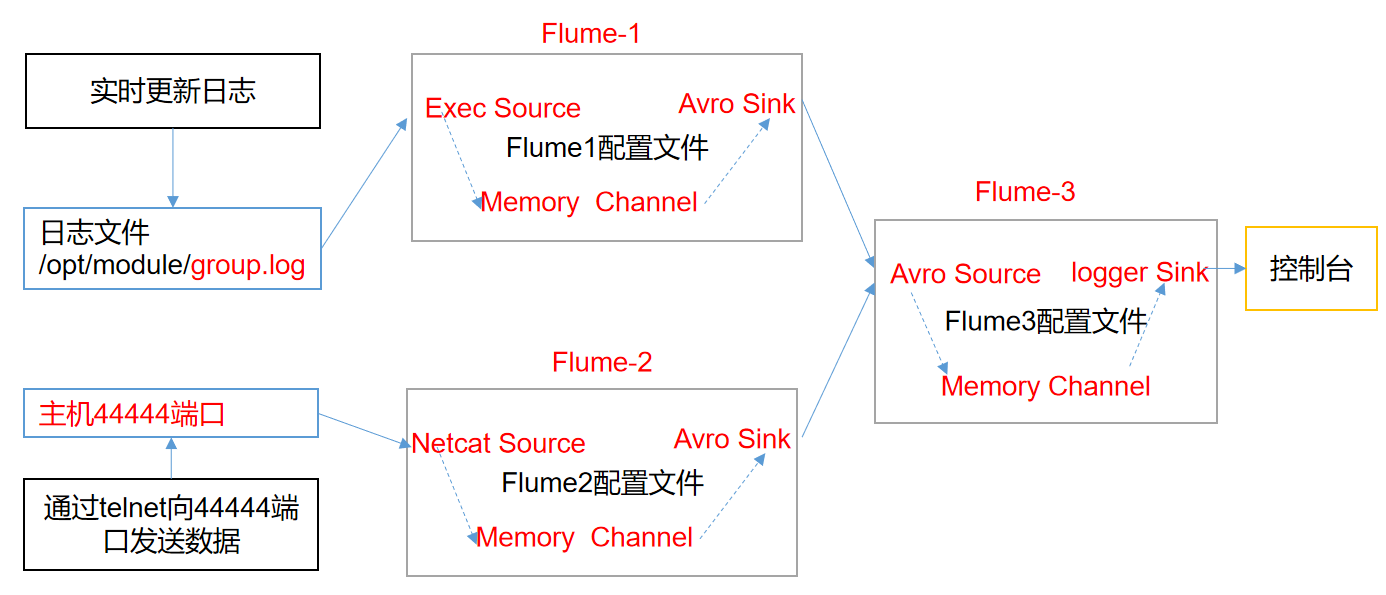
一般的使用场景为:
1. Flume1和Flume2负责外网环境下采集数据,传输给内网环境的Flume3
2. 统一处理采集的数据
6. Flume事务
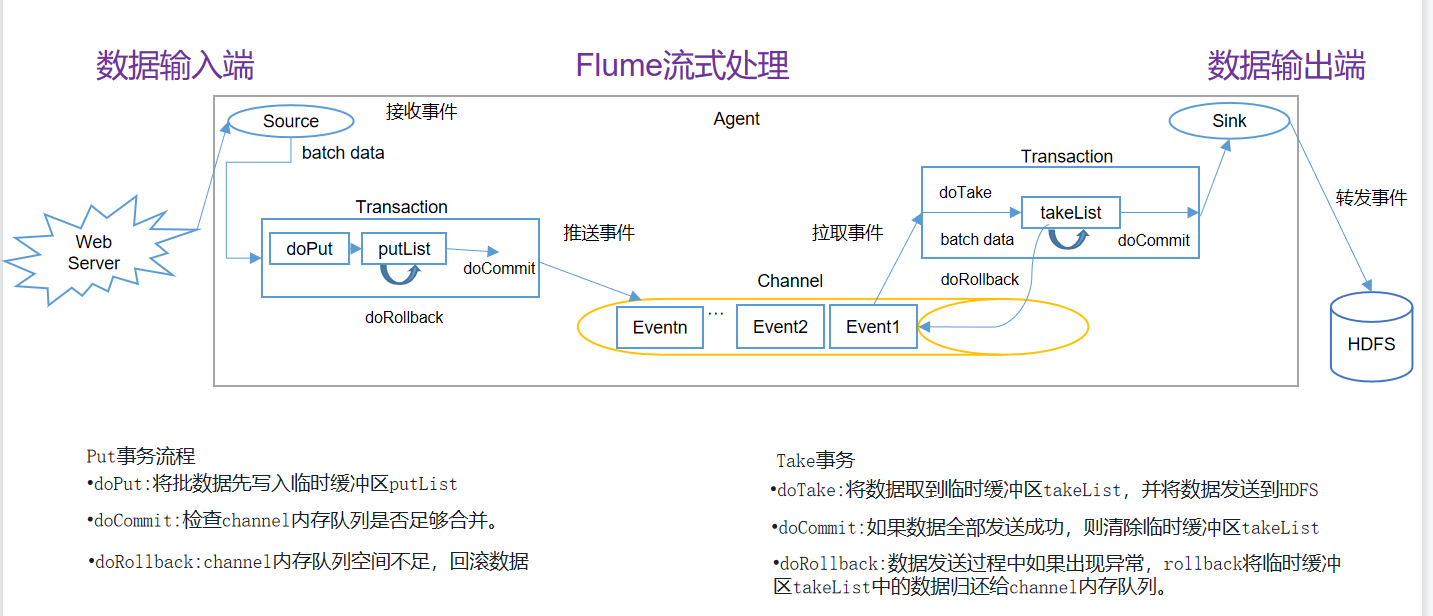
概念:
- putList: source在向channel放入数据时的缓冲区!putList在初始化时,需要根据一个固定的size初始化,这个size在channel中设置,在channel中,这个size由参数transactionCapacity决定!
- takeList: sink在向channel拉取数据时的缓冲区!
6.1 事务流程
put事务流程:
source将封装好的一批event(批的数量可以通过source的参数定义),先放入到putList中,放入完成后,一次性commit(),这批event就可以写入到channel!写入完成后,清空putList,开始下一批数据的写入!假如一批event中的某些event在放入putList时,发生了异常,此时要执行rollback(),rollback()直接清空putList。
take事务流程:
sink不断从channel中拉取event,每拉取一个event,这个event会先放入takeList中!当一个batchSize的event全部拉取到takeList中之后,此时由sink执行写出处理!假如在写出过程中,发送了异常,此时执行回滚!将takeList中所有的event全部回滚到channel! 反之,如果写出没有异常,执行commit(),清空takeList!
注意:假设takeList中有50个event,sink一批获取50个event开始写出数据,当sink写到第30个event时出现了异常,那么前30个的event写出依然是成功的,只是会将takeList的这50个event全部回滚到channel中,当下次sink再次取event进行写操作时,前30个event就会被重复写出。
6.2 数量大小关系
- batchSize: 每个Source和Sink都可以配置一个batchSize的参数。 这个参数代表一次性到channel中put|take 多少个event!
- transactionCapacity: putList和takeList的初始值!
- capacity: channel中存储event的容量大小!
大小原则为:整个数据流转的流程中,前面的批处理大小要小于等于后面的容量
那么大小关系应该是:batchSize <= transactionCapacity <= capacity
如果不遵循该规则,可能会存在容量大小不够的问题,比如source的batchSize为100,而transactionCapacity为50,那么当source将一批event放入putList时,明显putList的容量不够,会报异常
7. 自定义Source、interceptors、sink
7.1 自定义拦截器
https://flume.apache.org/FlumeUserGuide.html#flume-interceptors
7.2 自定义Source
http://flume.apache.org/releases/content/1.9.0/FlumeDeveloperGuide.html#source
7.3 自定义sink
http://flume.apache.org/releases/content/1.9.0/FlumeDeveloperGuide.html#sink
8. 监控数据流
在使用flume期间,我们需要监控以下数据:
- channel当前的容量是多少?
- channel当前已经使用了多少容量?
- source向channel中put成功了多少个event?
- sink从channel中take成功了多少个event?
此时我们可以使用JMX技术,它是 java的监控扩展模块,J可以帮助我们实时监控一个java进程中需要了解的参数,可以实时修改java进程中某个对象的参数!
实现JMX监控的流程需要如下组件:
①MBean(monitor bean): 监控的参数封装的Bean
②JMX的monitor服务:这个服务可以在程序希望获取到MBean参数时,来请求服务,请求后服务帮我们对MBean的参数进行读写!flume已经提供了基于JMX的服务实现,如果我们希望使用,只需要启动此服务即可!
③客户端:客户端帮我们来向JMX服务发送请求,显示服务返回的Mbean的结果
MBean和JMX的monitor服务Flume已帮我们完成,我们只需要选择合适的客户端即可,客户端有如下几种方式:
- 使用JCONSOLE程序查看:在flume的conf/env.sh文件中,配置
export JAVA_OPTS=”-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=5445 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false” - 使用web浏览器向JMX服务发请求查看,返回JSON格式的数据,这种方式更灵活,可以对接公司自己的大数据监控服务
bin/flume-ng agent --conf-file example.conf --name a1 -Dflume.monitoring.type=http -Dflume.monitoring.port=34545 - 使用第三方框架:官方有提供Ganglia框架,该框架自带web页面查看数据
9.常见问题
9.1 Flume采集数据会丢失吗
根据Flume的架构原理,Flume是不可能丢失数据的,其内部有完善的事务机制,Source到Channel是事务性的,Channel到Sink是事务性的,因此这两个环节不会出现数据的丢失,唯一可能丢失数据的情况是Channel采用memoryChannel,agent宕机导致数据丢失,或者Channel存储数据已满,导致Source不再写入,未写入的数据丢失。
Flume不会丢失数据,但是有可能造成数据的重复,例如数据已经成功由Sink发出,但是没有接收到响应,Sink会再次发送数据,此时可能会导致数据的重复。或者6.1中的注意也有可能会有数据的重复
最后
以上就是潇洒鸡翅最近收集整理的关于Flume使用1. 架构2. 安装3. 简单案例4. Agent内部原理5. Flume的拓扑结构6. Flume事务7. 自定义Source、interceptors、sink8. 监控数据流9.常见问题的全部内容,更多相关Flume使用1.内容请搜索靠谱客的其他文章。








发表评论 取消回复