深度学习简介
深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
深度学习采用的模型为深层神经网络(Deep Neural Networks,DNN)模型,即包含多个隐藏层(Hidden Layer,也称隐含层)的神经网络(Neural Networks,NN)。深度学习利用模型中的隐藏层,通过特征组合的方式,逐层将原始输入转化为浅层特征,中层特征,高层特征直至最终的任务目标。
如下图所示:
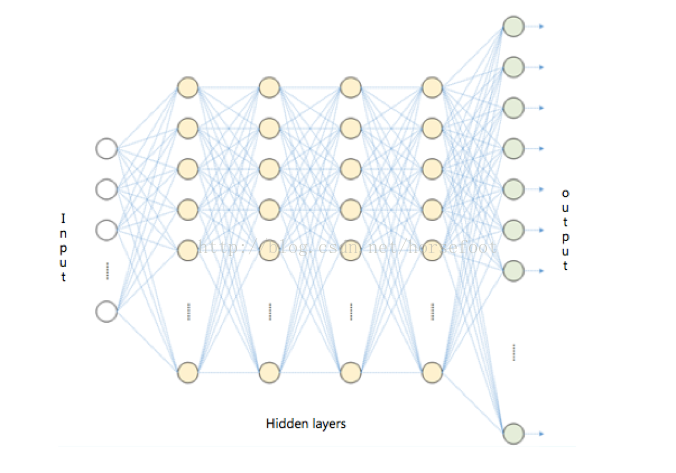
相对于传统的神经网络,深度学习含有更多的隐层(hidden layer),构造包含多隐藏层的深层网络结背后的理论依据包括仿生学依据与训练任务的层次结构依据。
对于很多训练任务来说,特征具有天然的层次结构。以语音、图像、文本为例,层次结构大概如下表所示。

以图像识别为例,图像的原始输入是像素,相邻像素组成线条,多个线条组成纹理,进一步形成图案,图案构成了物体的局部,直至整个物体的样子。不难发现,可以找到原始输入和浅层特征之间的联系,再通过中层特征,一步一步获得和高层特征的联系。想要从原始输入直接跨越到高层特征,无疑是困难的。
GPU计算的原理
1. GPU计算的优势
复杂的人工智能算法训练与计算经常涉及上亿的参数,这些参数的计算需要大量的计算能力,目前在深度学习领域,GPU计算已经成为主流,使用GPU运算的优势如下:
目前,主流的GPU具有强大的计算能力和内存带宽,如下图所示,无论性能还是内存带宽,均远大于同代的CPU。 同时,GPU的thousands of cores的并行计算能力也是一大优势。
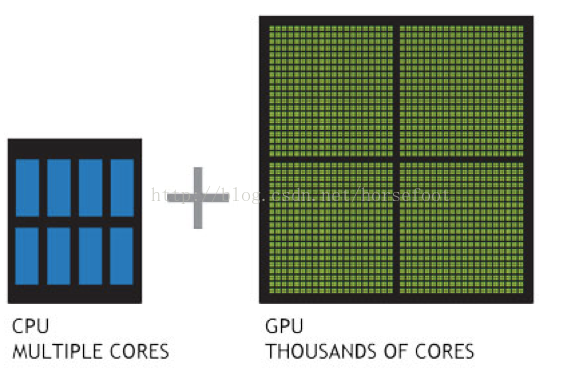
理解 GPU 和 CPU 之间区别的一种简单方式是比较它们如何处理任务。CPU 由专为顺序串行处理而优化的几个核心组成,而 GPU 则拥有一个由数以千计的更小、更高效的核心(专为同时处理多重任务而设计)组成的大规模并行计算架构。同时CPU相当的一部分时间在执行外设的中断、进程的切换等任务,而GPU有更多的时间并行计算。
2. GPU计算的原理
那么,CPU与GPU如何协同工作?下图展示了CPU与GPU的并存体系模式。
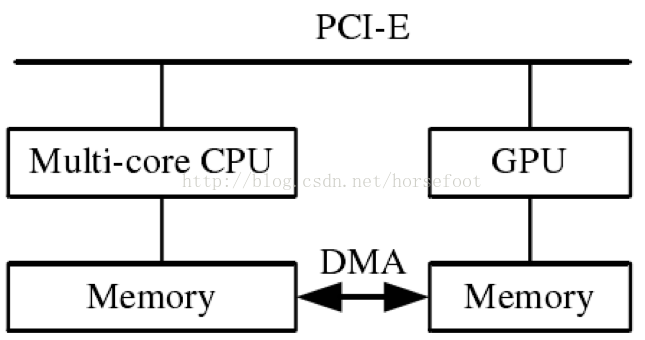
在需要GPU进行运算时,以NVIDIA推出的CUDA(Compute Unified Device Architecture)为例,整体的原理如下:
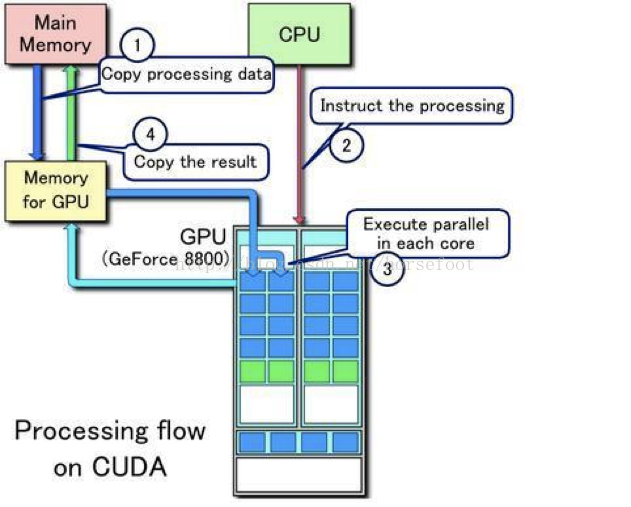
整体分为4步:
- 从主机内存将需要处理的数据copy到GPU的内存
- CPU发送数据处理执行给GPU
- GPU执行并行数据处理
- 将结果从GPU内存copy到主机内存
CUDA提供了对于一般性通用需求的大规模并发编程模型,使用户可以对NVIDIA GPU方便的对于 GPU进行并发性编程。如果进行编译优化会在特定操作系统里面把计算并行化分配到GPU的多个core里面,由于GPU有多个core(上千个),所以并发度大大提高,运算效率会比CPU高。下面用代码表明了如何通过GPU进行计算:
有三个数组int a[10], b[10], c[10];我们要计算a和b的向量之和存放到c中。
一般C语言:
for(int i=0; i<10; i++)
c[i] = a[i] + b[i];
CUDA编程做法:
GPU中的每个线程(核)有一个独立序号叫index,那么只要序号从0到9的线程执行c[index] = a[index] + b[index];就可以实现以上的for循环。以下为代码示例:
#include <stdio.h>
#include <cuda_runtime.h>
define N 10;/* 定义10个GPU运算线程 */
define SIZE N*sizeof(int);
/* 运行在GPU端的程序 */
__global__ void vectorADD(int* a, int* b, int* c)
{
int index = threadIdx.x;//获得当前线程的序号
if(index < blockDim.x)
c[index] = a[index] + b[index];
}
int main ()
{
/* 本地开辟三个数组存放我们要计算的内容 */
int* a = (int*) malloc (SIZE);
int* b = (int*) malloc (SIZE);
int* c = (int*) malloc (SIZE);
/* 初始化数组A, B和C */
for(int i=0; i<N; i++)
{
h_a[i] = i;
h_b[i] = i;
}
/* 在GPU上分配同样大小的三个数组 */
int* d_a;
int* d_b;
int* d_c;
cudaMalloc((void**)&d_a, SIZE);
cudaMalloc((void**)&d_b, SIZE);
cudaMalloc((void**)&d_c, SIZE);
/* 把本地的数组拷贝进GPU内存 */
cudaMemcpy(d_a, a, SIZE, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, SIZE, cudaMemcpyHostToDevice);
/* 定义一个GPU运算块 由 10个运算线程组成 */
dim3 DimBlock = N;
/* 通知GPU用10个线程执行函数vectorADD */
vectorADD<<<1, DimBlock>>>(d_a, d_b, d_c);
/* 将GPU运算完的结果复制回本地 */
cudaMemcpy(c, d_c, SIZE, cudaMemcpyDeviceToHost);
/* 释放GPU的内存 */
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
/* 验证计算结果 */
for(int j=0; j<N; j++)
printf(“%d “, c[j]);
printf(“n”);
}
3. GPU并行计算的原理
由于每台服务器有多个CPU,多个GPU,同时为了进一步提高并行机器学习效率,我们的目标是为了多台服务器(每台服务器包含多块GPU卡)采取分布式计算的形式进行,那么要完成目标,在硬件层面需要进行服务器集群的构建,同时需要在深度学习框架层面也支持分布式,下面介绍GPU计算的分布式原理,深度学习分布式原理在下一个章节介绍。
首先简单介绍下单主机内GPU并行计算的基本原理:
单GPU并行计算:
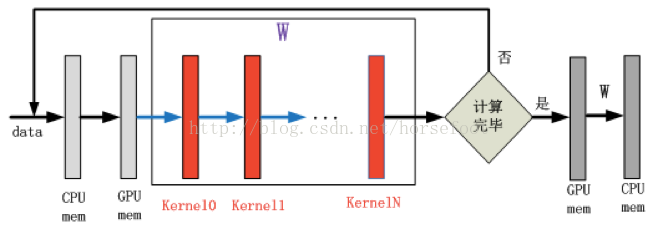
针对每次训练数据,模型内计算通过多次GPU 内核的调用完成计算。权重W值一直存在GPU内存中,直到所有训练数据计算完毕之后回传到系统内存中。
多GPU并行计算之数据并行:
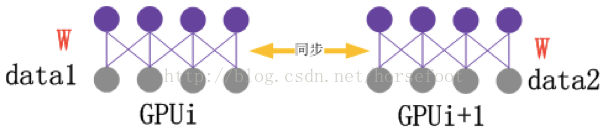
数据并行是指不同的GPU计算不同的训练数据,即把训练数据划分给不同的GPU进行分别计算,由于训练是逐步训练的,后一个训练数据的计算需要前一个训练数据更新的W(W通常是指模型训练变化了的数据),数据并行改变了这个计算顺序,多GPU计算需要进行W的互相通信,满足训练的特点,使训练可以收敛。数据并行如上图所示,多GPU训练不同的数据,每训练一次需要同步W,使得后面的训练始终为最新的W。该模型的缺点是当模型较大时,GPU内存无法满足存储要求,无法完成计算。
多GPU并行计算之模型并行:
模型并行是指多个GPU同时计算同一个训练数据,多个GPU对模型内的数据进行划分,在一次训练数据多层计算过程中,每个GPU内核计算之后需要互相交换数据才能进行下一次的计算。
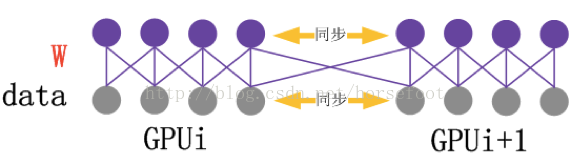
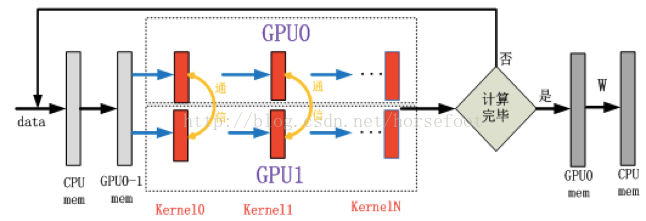
可以看出,模型并行需要更频繁的通信,增加通信压力,且实现难度较大
多GPU并行计算之集群计算:
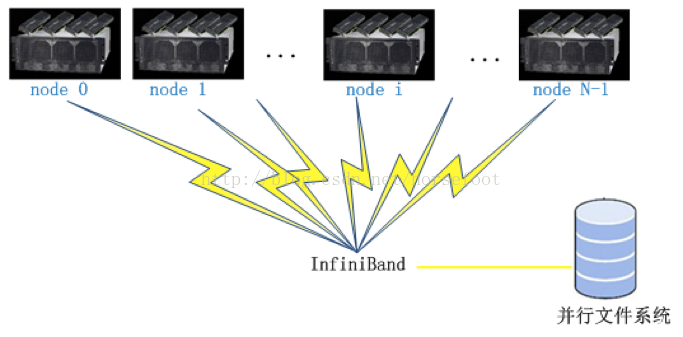
GPU集群并行模式即为多GPU并行中各种并行模式的扩展,如上图所示。节点间采用InfiniBand通信,节点间的GPU通过RMDA通信,节点内多GPU之间采用基于infiniband的通信。
分布式机器学习原理
分布式深度学习框架的基本原理,每个深度学习框架在分布式实现上各有不同,在此,我们用tensorflow作为例子:
分布式TensorFlow集群由多个服务端进程和客户端进程组成. 服务端和客户端的代码可以在不同的机器上也可以在同一个机器上。在具体实现上,分为ps服务器与worker服务器,ps服务器即是参数服务器,当模型越来越大,模型的参数越来越多,多到模型参数的更新,一台机器的性能都不够的时候,就需要把参数分开放到不同的机器去存储和更新。
于是就有了参数服务器的概念。
参数服务器可以是多台机器组成的集群,类似分布式的存储架构,涉及到数据的同步,一致性等等, 一般是key-value的形式,可以理解为一个分布式的key-value内存数据库,然后再加上一些参数更新的操作,采取这种方式可以几百亿的参数分散到不同的机器上去保存和更新,解决参数存储和更新的性能问题。
在tensorflow中,计算节点称做worker节点。
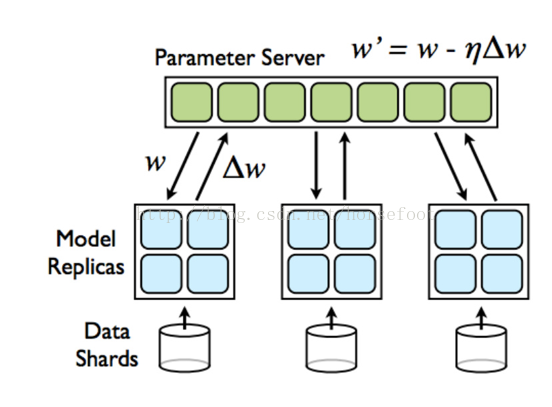
在运行在具体的物理集群时,PS服务器可以挑选如下图中的node0、node1…,worker节点可以挑选如下图中的node2,node3…
tensorflow的分布式有in-graph和between-gragh两种架构模式。
in-graph模式,把计算已经从单机多GPU扩展到了多机多GPU, 不过数据分发还是在一个节点。 这样的好处是配置简单,但是这样的坏处是训练数据的分发依然在一个节点上,要把训练数据分发到不同的机器上,严重影响并发训练速度。在大数据训练的情况下,不推荐使用这种模式。
between-graph模式下,训练的参数保存在参数服务器,数据不用分发,数据分片的保存在各个计算节点,各个计算节点自己算自己的,算完了之后,把要更新的参数告诉参数服务器,参数服务器更新参数。 这种模式的优点是不用训练数据的分发, 尤其是在数据量在TB级的时候,所以大数据深度学习推荐使用between-graph模式。
in-graph模式和between-graph模式都支持同步和异步更新
在同步更新的时候,每次梯度更新,要等所有分发出去的数据计算完成后,返回回来结果之后,把梯度累加算了均值之后,再更新参数。这样的好处是loss的下降比较稳定, 但是这个的坏处也很明显, 处理的速度取决于最慢的那个分片计算的时间。
在异步更新的时候,所有的计算节点,各自算自己的,更新参数也是自己更新自己计算的结果,这样的优点就是计算速度快,计算资源能得到充分利用,但是缺点是loss的下降不稳定,抖动大。
总结
本文介绍了深度学习的概念,GPU的计算原理,包括GPU并行计算的实现,以及分布式深度学习框架(以tensorflow为例)实现的方式。分布式的深度学习框架如果需要进行动态的调度,以及多个学习框架以资源共享的方式运行与同一个集群时,我们又需要在集群上实现集群管理与调度软件,来实现分布式深度学习框架的资源调度,将在下一篇文章中进行介绍。
最后
以上就是光亮枫叶最近收集整理的关于[机器学习入门] 深度学习简介,GPU计算的原理,分布式机器学习原理的全部内容,更多相关[机器学习入门]内容请搜索靠谱客的其他文章。




![[机器学习入门] 深度学习简介,GPU计算的原理,分布式机器学习原理](https://www.shuijiaxian.com/files_image/reation/bcimg7.png)



发表评论 取消回复