空间索引之GeoHash – 标点符 (biaodianfu.com)
钱魏Way · 2020-10-08 · 2,508 次浏览
目录
- Geohash简介
- Geohash算法实现
- 维度拆解
- 经度拆解
- 经纬度合并
- Geohash的精度
- Geohash的应用点
- GeoHash工具整理
- python-geohash
- Geohash
- geohash2
- geolib
- ProximityHash
- georaptor
- 其他项目
- GEOHASH的可视化
- Geohash实战:与商圈高效匹配
- 项目背景
- 面数据GeoHash编码
- 临近GeoHash块的快速算法
- 建立海量点数据与面数据的关系
- 延伸
- 问题与疑问
- 相关文章:
Geohash简介
Geohash是一种地址编码,它能把二维的经纬度编码成一维的字符串。比如,北海公园的编码是wx4g0ec1。
Geohash有以下几个特点:
- Geohash用一个字符串表示经度和纬度两个坐标。在数据存储时可以简化为只为一列做索引。
- Geohash表示的并不是一个点,而是一个矩形区域。使用者可以发布地址编码,既能表明自己大致位置,又不至于暴露自己的精确坐标,有助于隐私保护。
- Geohash编码的前缀可以表示更大的区域。例如wx4g0ec1,它的前缀wx4g0e表示包含编码wx4g0ec1在内的更大范围。 这个特性可以用于附近地点搜索。
Geohash算法实现
GeoHash是一种对地理坐标进行编码的方法,它将二维坐标映射为一个字符串。每个字符串代表一个特定的矩形,在该矩形范围内的所有坐标都共用这个字符串。字符串越长精度越高,对应的矩形范围越小。对一个地理坐标编码时,按照初始区间范围纬度[-90,90]和经度[-180,180],计算目标经度和纬度分别落在左区间还是右区间。落在左区间则取0,右区间则取1。然后,对上一步得到的区间继续按照此方法对半查找,得到下一位二进制编码。当编码长度达到业务的进度需求后,根据“偶数位放经度,奇数位放纬度”的规则,将得到的二进制编码穿插组合,得到一个新的二进制串。最后,根据base32的对照表,将二进制串翻译成字符串,即得到地理坐标对应的目标GeoHash字符串。
Geohash的最简单的解释就是:将一个经纬度信息,转换成一个可以排序,可以比较的字符串编码。
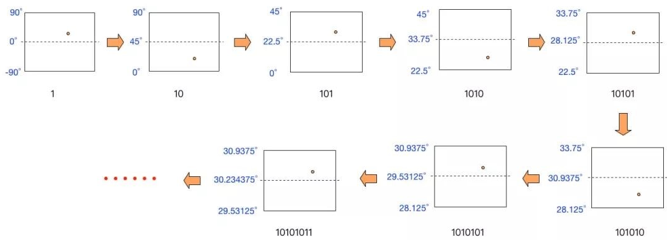
维度拆解
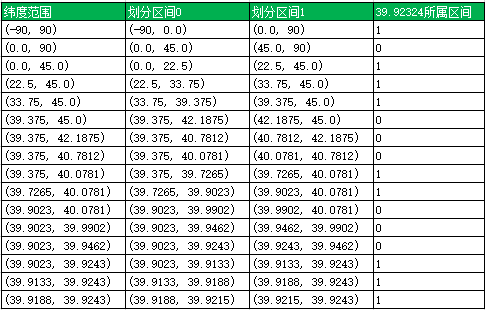
首先将纬度范围(-90, 90)平分成两个区间(-90,0)、(0, 90),如果目标纬度位于前一个区间,则编码为0,否则编码为1。然后再将(0, 90)分成 (0, 45), (45, 90)两个区间, 以此类推,直到精度符合要求为止,得到纬度39.92324编码为1011 1000 1100 0111 1001。
经度拆解
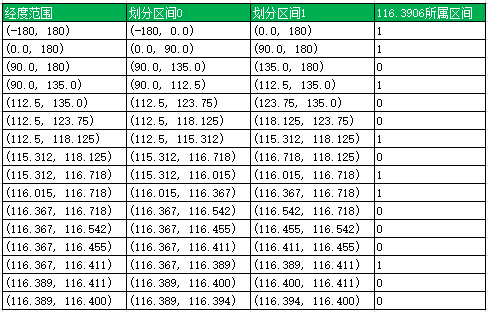
经度也用同样的算法,对(-180, 180)依次细分,得到116.3906的编码为1101 0010 1100 0100 0100。
解码算法与编码算法相反,先进行base32解码,然后分离出经纬度,最后根据二进制编码对经纬度范围进行细分即可。
上文讲了GeoHash的计算步骤,仅仅说明是什么而没有说明为什么?为什么分别给经度和维度编码?为什么需要将经纬度两串编码交叉组合成一串编码?
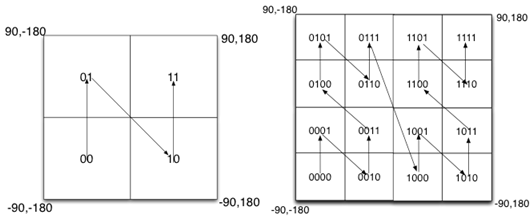
如图所示,我们将二进制编码的结果填写到空间中,当将空间划分为四块时候,编码的顺序分别是左下角00,左上角01,右下脚10,右上角11,也就是类似于Z的曲线,当我们递归的将各个块分解成更小的子块时,编码的顺序是自相似的(分形),每一个子快也形成Z曲线,这种类型的曲线被称为Peano空间填充曲线。
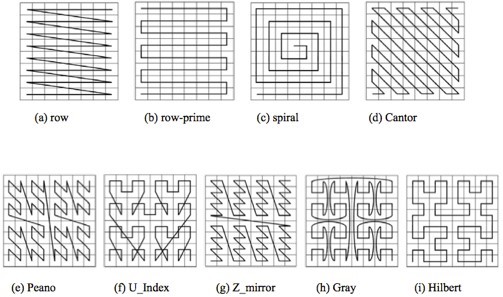
这种类型的空间填充曲线的优点是将二维空间转换成一维曲线(事实上是分形维),对大部分而言,编码相似的距离也相近, 但Peano空间填充曲线最大的缺点就是突变性,有些编码相邻但距离却相差很远,比如0111与1000,编码是相邻的,但距离相差很大。
除Peano空间填充曲线外,还有很多空间填充曲线,如图所示,其中效果公认较好是Hilbert空间填充曲线,相较于Peano曲线而言,Hilbert曲线没有较大的突变。为什么GeoHash不选择Hilbert空间填充曲线呢?可能是Peano曲线思路以及计算上比较简单吧,事实上,Peano曲线就是一种四叉树线性编码方式。
经纬度合并
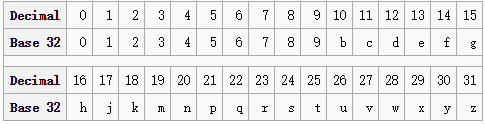
接下来将经度和纬度的编码合并,奇数位是纬度,偶数位是经度,得到编码 11100 11101 00100 01111 00000 01101 01011 00001。最后,用0-9、b-z(去掉a, i, l, o)这32个字母进行base32编码,得到(39.92324, 116.3906)的编码为wx4g0ec1。
Geohash的精度
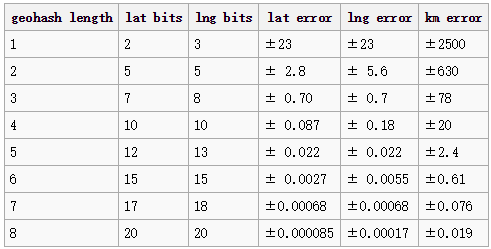
Geohash算法的主要思想是对某一数字通过二分法进行无限逼近。显然的是,不可能让计算机执行无穷计算,加入执行N次计算,则x属于的区间长度为(b-a)/2N+1 ,以纬度计算为例,则为180/2N ,误差近似计算为:err= 180/2N+1 =90/2N ,如果N=20,则误差最大为:0.00009。但无论如何这样表明Geohash是一种近似算法。
Geohash长度对应的精度误差:
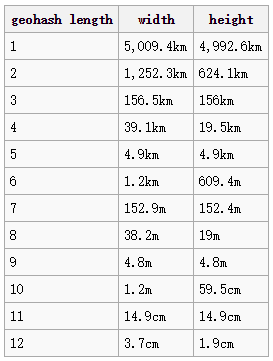
由于GeoHash是将区域划分为一个个规则矩形,并对每个矩形进行编码,每个精度等级对应的规则矩形大小为:
Geohash的应用点
geohash的最大用途就是附近地址搜索了。不过,从geohash的编码算法中可以看出它的一个缺点:位于格子边界两侧的两点,
虽然十分接近,但编码会完全不同。实际应用中,可以同时搜索当前格子周围的8个格子,即可解决这个问题。
GeoHash工具整理
python-geohash
项目地址:
- https://github.com/hkwi/python-geohash
- python-geohash · PyPI
官方没有说明文档,以下为使用示例:
import geohash
print(geohash.encode(30.723514, 104.123245, precision=5)) # wm6nc
print(geohash.decode("wm6nc")) # (30.73974609375, 104.12841796875) #中心经纬度
print(geohash.decode("wm6nc", delta=True)) # (30.73974609375, 104.12841796875, 0.02197265625, 0.02197265625) #中心及偏差
print(geohash.decode_exactly("wm6nc")) # (30.73974609375, 104.12841796875, 0.02197265625, 0.02197265625)
print(geohash.bbox("wm6nc")) # {'s': 30.7177734375, 'w': 104.1064453125, 'n': 30.76171875, 'e': 104.150390625}
print(geohash.neighbors("wm6nc")) # ['wm6nb', 'wm6nf', 'wm6n9', 'wm6n8', 'wm6nd', 'wm6p1', 'wm6p0', 'wm6p4']
print(geohash.expand("wm6nc")) # ['wm6nb', 'wm6nf', 'wm6n9', 'wm6n8', 'wm6nd', 'wm6p1', 'wm6p0', 'wm6p4', 'wm6nc']
Geohash
项目地址:
- Geohash · PyPI
- https://github.com/vinsci/geohash
使用示例:
import Geohash
print(Geohash.encode(30.723514, 104.123245, precision=5)) # wm6nc
print(Geohash.decode("wm6nc")) # (30.73974609375, 104.12841796875)
print(Geohash.decode("wm6nc", delta=True)) # (30.73974609375, 104.12841796875, 0.02197265625, 0.02197265625)
print(Geohash.decode_exactly("wm6nc")) # (30.73974609375, 104.12841796875, 0.02197265625, 0.02197265625)
geohash2
项目地址:
- https://github.com/dbarthe/geohash/
- geohash2 · PyPI
使用示例:
import geohash2
print(geohash2.encode(30.723514, 104.123245, precision=5)) # wm6nc
print(geohash2.decode("wm6nc")) # ('30.7', '104.1')
print(geohash2.decode_exactly("wm6nc")) # (30.73974609375, 104.12841796875, 0.02197265625, 0.02197265625)
print(geohash2.encode(30.7, 104.1, precision=5)) # wm6n8
从上面的数据可以看到decode后获取的不是中心点的坐标,而是对坐标进行了精度的调整,导致上述问题,所以不推荐使用。
geolib
项目地址:
- geolib · PyPI
- https://github.com/joyanujoy/geolib
from geolib import geohash
print(geohash.encode(30.723514, 104.123245, precision=5)) # wm6nc
print(geohash.decode("wm6nc")) # Point(lat=Decimal('30.73974609375'), lon=Decimal('104.12841796875'))
print(geohash.bounds(
"wm6nc")) # Bounds(sw=SouthWest(lat=30.7177734375, lon=104.1064453125), ne=NorthEast(lat=30.76171875, lon=104.150390625))
print(geohash.neighbours(
"wm6nc")) # Neighbours(n='wm6p1', ne='wm6p4', e='wm6nf', se='wm6nd', s='wm6n9', sw='wm6n8', w='wm6nb', nw='wm6p0')
print(geohash.adjacent("wm6nc", 'n')) # wm6p1
ProximityHash
ProximityHash生成一组覆盖圆形区域的地理HASH,给定中心坐标和半径。它还可以使用GeoRaptor创建不同级别的geohash的最佳组合来表示圆,从最高级别开始迭代,直到绘制出最佳混合。结果精度与初始geohash级别的精度相同,但数据大小大大减小,从而提高了速度和性能。
项目地址:
- proximityhash · PyPI
- https://github.com/ashwin711/proximityhash
georaptor
GeoRaptor通过从最高级别开始迭代直到绘制出最佳混合,创建跨不同级别的geohash的最佳组合来表示多边形。结果精度与初始geohash级别相同,但对于大型多边形,数据大小会显著减小,从而提高速度和性能。
项目地址:
- https://github.com/ashwin711/georaptor
- georaptor · PyPI
其他项目
- https://github.com/mathieuripert/geoh
- https://github.com/Bonsanto/polygon-geohasher
- https://github.com/wmorin/geohashit
- https://github.com/derrickpelletier/geohash-poly
- https://github.com/tammoippen/geohash-hilbert
- https://github.com/kylebebak/py-geohash-any
GEOHASH的可视化
参考项目:
- https://github.com/missinglink/leaflet-spatial-prefix-tree
- https://github.com/rzanato/geohashgrid
- Geohash encoding/decoding
- https://github.com/soorajb/geohash-grid
Geohash实战:与商圈高效匹配
项目背景
闲鱼app根据交通条件、商场分布情况、住宅区分布情况综合考虑,将城市划分为一个个商圈。杭州部分区域商圈划分如下图所示:
闲鱼的商品是由用户发布的GPS随机分布在地图上的点数据。当用户处于某个商圈范围内时,app会向用户推荐GPS位于此商圈中的商品。要实现精准推荐服务,就需要计算出哪些商品是归属于你所处的商圈。
在数据库中,商圈是由多个点围成的面数据,这些面数据形状、大小各异,且互不重叠。商品是以GPS标记的点数据,如何能够快速高效地确定海量商品与商圈的归属关系呢?传统而直接的方法是,利用几何学的空间关系计算公式对海量数据实施直接的“点—面”关系计算,来确定每一个商品是否位于每一个商圈内部。
闲鱼目前有10亿商品数据,且每天还在快速增加。全国所有城市的商圈数量总和大约为1万,每个商圈的大小不一,边数从10到80不等。如果直接使用几何学点面关系运算,需要的计算量级约为2亿亿次基本运算。按照这个思路,我们尝试过使用阿里巴巴集团内部的离线计算集群来执行计算,结果集群在运行了超过2天之后也未能给出结果。
面数据GeoHash编码
标准GeoHash算法只能用来计算二维点坐标对应的GeoHash编码,现实场景中还需要计算面数据(即GIS中的POLYGON多边形对象)对应的GeoHash编码,需要扩展算法来实现。算法思路:
- 找到目标Polygon的最小外接矩形MBR,计算此MBR西南角坐标对应的GeoHash编码。
- 用GeoHash编码的逆算法,反解出此编码对应的矩形GeoHash块
- 以此GeoHash块为起点,循环往东、往北找相邻的同等大小的GeoHash块,直到找到的GeoHash块完全超出MBR的范围才停止。
如此找到的多个GeoHash块,边缘上的部分可能与目标Polygon完全不相交,这部分块需要通过计算剔除掉,如此一来可以减少后续不必要的计算量。
上面的例子中最终得到的结果高清大图如下,其中蓝色的GeoHash块是与原始Polygon部分相交的,橘黄色的GeoHash块是完全被包含在原始Polygon内部的。
上述算法总结成流程图如下:
临近GeoHash块的快速算法
上一节对面数据进行GeoHash编码的流程图中标记为绿色和橘黄色的两步,分别是要寻找相邻的东边或北边的GeoHash字符串。传统的做法是,根据当前GeoHash块的反解信息,求出相邻块内部的一点,在对这个点做GeoHash编码,即为相邻块的GeoHash编码。如下图,我们要计算”wtmk72″周围的8个相邻块的编码,就要先利用GeoHash逆算法将”wtmk72″反解出4个顶点的坐标N1、N2、N3、N4,然后由这4个坐标计算出右侧邻接块内部的任意一点坐标N5,再对N5做GeoHash编码,得到的“wtmk78”就是我们要求的右边邻接块的编码。按照同样的方法,求可以求出”wtmk72″周围总共8个邻接块的编码。
这种方法需要先解码一次再编码一次,比较耗时,尤其是在指定的GeoHash字符串长度较长需要循环较多次的情况下。
通过观察GeoHash编码表的规律,结合GeoHash编码使用的Z阶曲线的特性,验证了一种通过查表来快速求相邻GeoHash字符串的方法。还是以“wtmk72”这个GeoHash字符串为例,对应的10进制数是“28,25,19,18,7,2”,转换成二进制就是11100 11001 10011 10010 00111 00010。其中,w对应11100,这5个二进制位分别代表“经 纬 经 纬 经”;t对应11001,这5个二进制位分别代表“纬 经 纬 经 纬”。由此推广开来可知,GeoHash中的奇数位字符(本例中的’w’、’m’、’7’)代表的二进制位分别对应“经 纬 经 纬 经”,偶数位字符(本例中的’t’、’k’、’2’)代表的二进制位分别对应“纬 经 纬 经 纬”。’w’的二进制11100,转换成方位含义就是“右 上 右 下 左”。’t’的二进制11001,转换成方位含义就是“上 右 下 左 上”。根据这个字符与方位的转换关系,我们可以知道,奇数位上的字符与位置对照表如下:

偶数位上的字符与位置对照表如下:
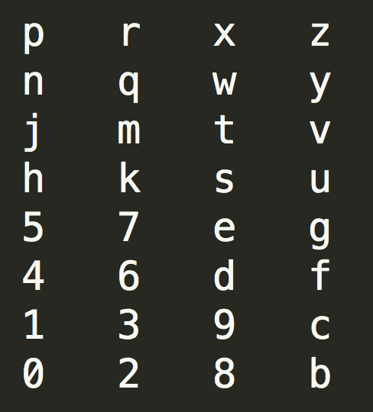
这里可以看到一个很有意思的现象,奇数位的对照表和偶数位对照表存在一种转置和翻转的关系。 有了以上两份字符与位置对照表,就可以快速得出每个字符周围的8个字符分别是什么。而要计算一个给定GeoHash字符串周围8个GeoHash值,如果字符串最后一位字符在该方向上未超出边界,则前面几位保持不变,最后一位取此方向上的相邻字符即可;如果最后一位在此方向上超出了对照表边界,则先求倒数第二个字符在此方向上的相邻字符,再求最后一个字符在此方向上相邻字符(对照表环状相邻字符);如果倒数第二位在此方向上的相邻字符也超出了对照表边界,则先求倒数第三位在此方向上的相邻字符。以此类推。
以上面的“wtmk72”举例,要求这个GeoHash字符串的8个相邻字符串,实际就是求尾部字符‘2’的相邻字符。‘2’适用偶数对照表,它的8个相邻字符分别是‘1’、‘3’、‘9’、‘0’、‘8’、‘p’、‘r’、‘x’,其中‘p’、‘r’、‘x’已经超出了对照表的下边界,是将偶数位对照表上下相接组成环状得到的相邻关系。所以,对于这3个超出边界的“下方”相邻字符,需要求倒数第二位的下方相邻字符,即‘7’的下方相邻字符。‘7’是奇数位,适用奇数位对照表,‘7’在对照表中的“下方”相邻字符是‘5’,所以“wtmk72”的8个相邻GeoHash字符串分别是“wtmk71”、“wtmk73”、“wtmk79”、“wtmk70”、“wtmk78”、“wtmk5p”、“wtmk5r”、“wtmk5x”。利用此相邻字符串快速算法,可以大大提高上一节流程图中面数据GeoHash编码算法的效率。
建立海量点数据与面数据的关系
建立海量点数据与面数据的关系的思路是,先将需要匹配的商品GPS数据(点数据)、商圈AOI数据(面数据)按照前面所述的算法,分别计算同等长度的GeoHash编码。每个点数据都对应唯一一个GeoHash字符串;每个面数据都对应一个或多个GeoHash编码,这些编码要么是“完全包含字符串”,要么是“部分包含字符串”。
- 将每个商品的GeoHash字符串与商圈的“完全包含字符串”进行join操作。join得到的结果中出现的<商品,商圈>数据就是能够确定的“某个商品属于某个商圈”的关系。
- 对于剩下的还未被确定关系的商品,将这些商品的GeoHash字符串与商圈的“部分包含字符串”进行join操作。join得到的结果中出现的<商品,商圈>数据是有可能存在的“商品属于某个商圈”的关系,接下来对这批数据中的商品gps和商圈AOI数据进行几何学关系运算,进而从中筛选出确定的“商品属于某个商圈”的关系。
如图:
- 商品1的点数据GeoHash编码为”wtmk70j”,与面数据的“完全包含字符串wtmk70j”join成功,所以可以直接确定商品1属于此面数据。
- 商品2的点数据GeoHash编码为“wtmk70r”,与面数据的“部分包含字符串wtmk70r”join成功,所以商品2疑似属于面数据,具体是否存在包含关系,还需要后续的点面几何学计算来确定。
- 商品3的点数据GeoHash编码与面数据的任何GeoHash块编码都匹配不上,所以可以快速确定商品3不属于此面数据。
实际应用中,原始的海量商品GPS范围散布在全国各地,海量商圈数据也散布在全国各个不同的城市。经过a)步骤的操作后,大部分的商品数据已经确定了与商圈的从属关系。剩下的未能匹配上的商品数据,经过b)步骤的GeoHash匹配后,可以将后续“商品-商圈几何学计算”的运算量从“1个商品 x 全国所有商圈”笛卡尔积的量级,降低为“1个商品 x 1个(或几个)商圈”笛卡尔积的量级,减少了绝大部分不必要的几何学运算,而这部分运算是非常耗时的。
在闲鱼的实际应用中,10亿商品和1万商圈数据,使用本文的快速算法,只需要 10亿次GeoHash点编码 + 1万次GeoHash面编码 + 500万次“点是否在面内部”几何学运算,粗略换算为基本运算需要的次数约为1800亿次,运算量远小于传统方法的2亿亿次基本运算。使用阿里巴巴的离线计算平台,本文的算法在不到一天的时间内就完成了全部计算工作。
另外,对于给定的点和多边形,通过几何学计算包含关系的算法不止一种,最常用的算法是射线法。简单来说,就是从这个点出发做一条射线,判断该射线与多边形的交点个数是奇数还是偶数。如果是奇数,说明点在多边形内;否则,点在多边形外。
延伸
面对海量点面数据的空间关系划分,本文采用是的通过GeoHash来降低计算量的思路,本质上来说是利用了空间索引的思想。事实上,在GIS领域有多种实用的空间索引,常见的如R树系列(R树、R+树、R*树)、四叉树、K-D树、网格索引等,这些索引算法各有特点。本文的思路不仅能用来处理点—面关系的相关问题,还可以用来快速处理点—点关系、面—面关系、点—线关系、线—线关系等问题,比如快速确定大范围类的海量公交站台与道路的从属关系、多条道路或铁路是否存在交点等问题。
问题与疑问
10亿条商品和1万条商圈数据做匹配,如果是我,我会怎么做?我会将商品和商圈先划分城市,再通过城市间匹配减少匹配量。暂时不清楚为什么阿里不采用此方案。
参考资料:
- https://en.wikipedia.org/wiki/Geohash
- 基于快速GeoHash,如何实现海量商品与商圈的高效匹配?
相关文章:
- 空间索引之 Google S2
- Skyline实战:CentOS 7部署
- 自然语言处理之中文分词
- 时间序列异常检测算法综述
- 地理信息系统之瓦片坐标系
最后
以上就是无语万宝路最近收集整理的关于空间索引之GeoHash的全部内容,更多相关空间索引之GeoHash内容请搜索靠谱客的其他文章。








发表评论 取消回复