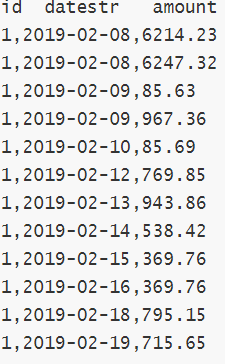
从左往右依次是用户id 存钱时间 每次存钱的金额
我们要求出:
用户的连续登录时间,
连续登录开始时间,
连续登录结束时间,
每次连续登录期间存储的总金额,
以及中间没有登录的时间
这是向表中插入的部分数据 :
建表语句
create table deal_tb(
id string
,datestr string
,amount string
)row format delimited fields terminated by ',';然后将数据插入
hive> load data local inpath '/usr/local/soft/data/date.txt' into table deal_tb;
首先我们可以对数据进行分组,因为有的人一天之内有可能不止一次的存钱操作,用sum函数对金钱进行求和。我们希望看到的是每个人每天一共存储了多少钱,
//group by后面的字段是id和datesrt。
//这样处理的结果是二者的笛卡尔积,符合显示每个用户每天的需求
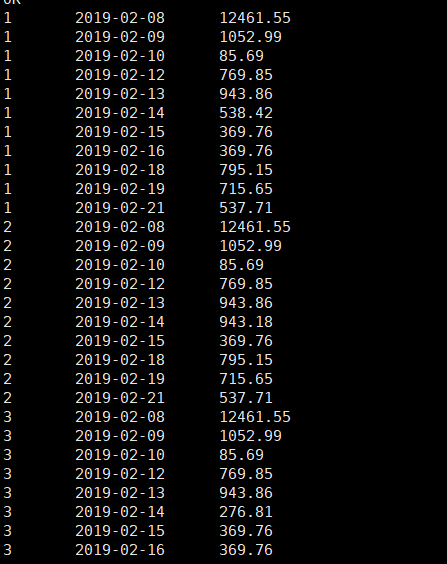
select id,datestr,sum(amount) as amount
from deal_tb
group by id,datestr;
接下来可能有些难想出来,怎么判断这个日期是不是连续的?
首先我们在上面的表上加上排名数据
with t as (select id,datestr,sum(amount) as amount
from deal_tb
group by id,datestr)
select t.id
,t.datestr
,t.amount
,row_number() over (partition by id order by datestr) as rn
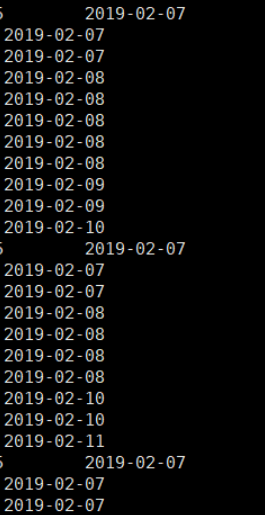
from t;运行结果如下: 看看图中的数据,排名使用的row_number函数,从1到最后连续显示
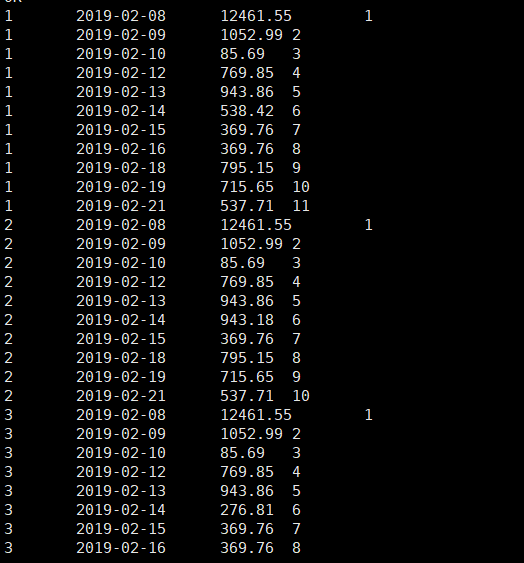
时间 -08 -09 -10 -12 -13 -14中间是有断开的天数
那么我把用时间减去对应排名:先拿前3天来观察
这3天的时间是连续递增,对于排名也是连续递增的,所以他么们的差值相同
| datestr | rank | Datestr-rank |
| 2019-02-08 | 1 | 2019-02-07 |
| 2019-02-09 | 2 | 2019-02-07 |
| 2019-02-10 | 3 | 2019-02-07 |
而对于中间如果有断开的天数会像下表中一样,从rank=3 的位置比较
由于中间天数断开,他们的时间和rank相减后的结果,就会比上面的多出断开的天数,所以结果会不一样了。
由此就可以看出哪些是连续的天数
| Datestr | rank | Datestr-rank |
| 2019-02-10 | 3 | 2019-02-07 |
| 2019-02-12 | 4 | 2019-02-08 |
| 2019-02-13 | 5 | 2019-02-08 |
用时间减去常数的函数是:date_sub(时间,常数)
with t as (
select id
,datestr
,sum(amount) as amount
from deal_tb
group by id,datestr
),
t1 as
(
select t.id
,t.datestr
,t.amount
,row_number() over (partition by id order by datestr) as rn
from t
)
select t1.id
,t1.datestr
,t1.amount
,date_sub(t1.datestr,t1.rn) as grp
from t1;运行结果如下:
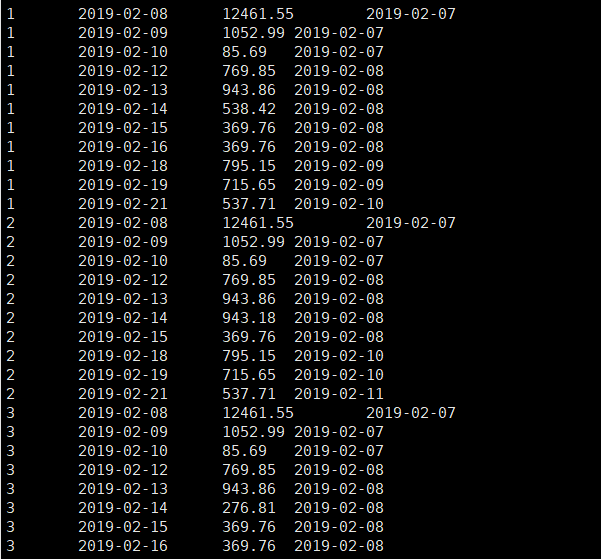
然后我们要做的就是将这张表再次作为数据来源查询
上面的查询结果中,连续的天数他们后面新出现的时间字段都是相同的,我们可以利用这一点进行分组,只根据一个grp字段分组还不行,因为还有用户不同, 所以是根据这2个字段进行分组;
分完组后的内容是不是都是如下图一样,但是数据结果只有一行,这里我们需要提取需要的信息;
在分组内,我们是不是将时间datestr的最小值提出来,这就是连续登录的开始时间;
提出时间datestr的最大值就是连续登录的结束时间;
连续登录的存储总金额就只要把以下组内的金额相加就可以;
分组后,count(*) 结果就是连续登录的天数

前面的工作的都完成后,我们看最后一个需求:求出间隔的天数,答案其实就在最右侧的grp字段内容
经过分组后,剩下的数据都进行了合并, 剩下的每一条都表示一个连续登录的信息,那他们减去上一行表示的是什么呢 ,这个差值就是中间断开的天数
为了使用前一行的数据,我们还需要使用获得前面行数据的函数:

利用当前行grp减去上一行的grp,得出时间间隔
with t as (
select id
,datestr
,sum(amount) as amount
from deal_tb
group by id,datestr
),
t1 as
(
select t.id
,t.datestr
,t.amount
,row_number() over (partition by id order by datestr) as rn
from t
),
t2 as
(
select t1.id
,t1.datestr
,t1.amount
,date_sub(t1.datestr,t1.rn) as grp
from t1
)
//这里的lag(...) over(...)表示的是将上一行的数据开了一个窗口,能与我当前行进行相减
select t2.id
,t2.grp
,sum(t2.amount) as amount
,count(*)
,min(t2.datestr) as start_time
,max(t2.datestr) as end_time
,datediff(t2.grp,lag(t2.grp,1) over (partition by t2.id order by t2.grp)) as d_days
from t2
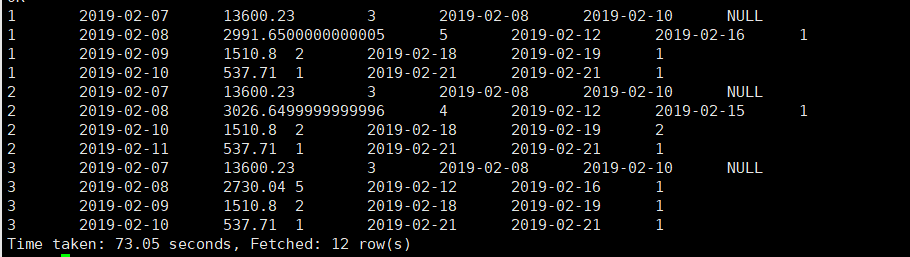
group by t2.id,t2.grp;
从左往右依次是用户id , 用来数据分组的连续登录信息,连续登录天里存入的总金额,连续登录天数,连续登录开始时间,连续登录结束时间,连续登录中间断开的时间
最后
以上就是慈祥小笼包最近收集整理的关于hive用户连续登录天数问题的全部内容,更多相关hive用户连续登录天数问题内容请搜索靠谱客的其他文章。








发表评论 取消回复