GPU加速:
把计算过程从CPU切换到GPU上。首先,把设备定义为使用cuda,然后把我们建立好的网络MLP搬到设备上去,还需要把交叉熵损失函数也搬上去,最后需要把data搬上去。,即完成了数据上传至cuda进行加速运算的前期准备。
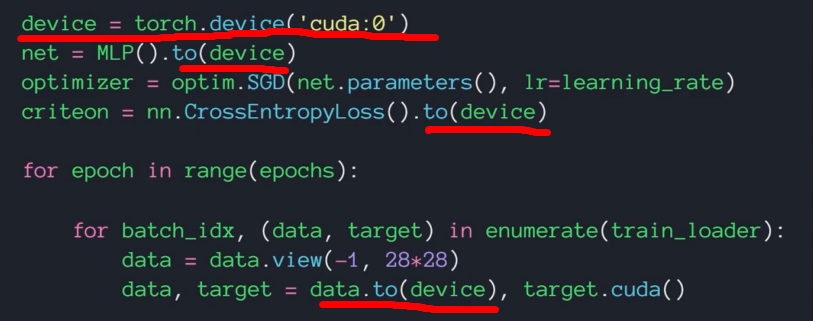
网络刚开始训练时,loss会下降,准确性会上升,这时的网络参数在学一些本质的特征,但随着学习的次数增加,会发现尽管准确率上升,但有效性却不再上升,并且损失函数还会偶尔剧烈波动。这是因为后面网络参数不再学医本质东西了,而是开始抄袭数据,使之变得无效。因此网络并不是训练越久越好。
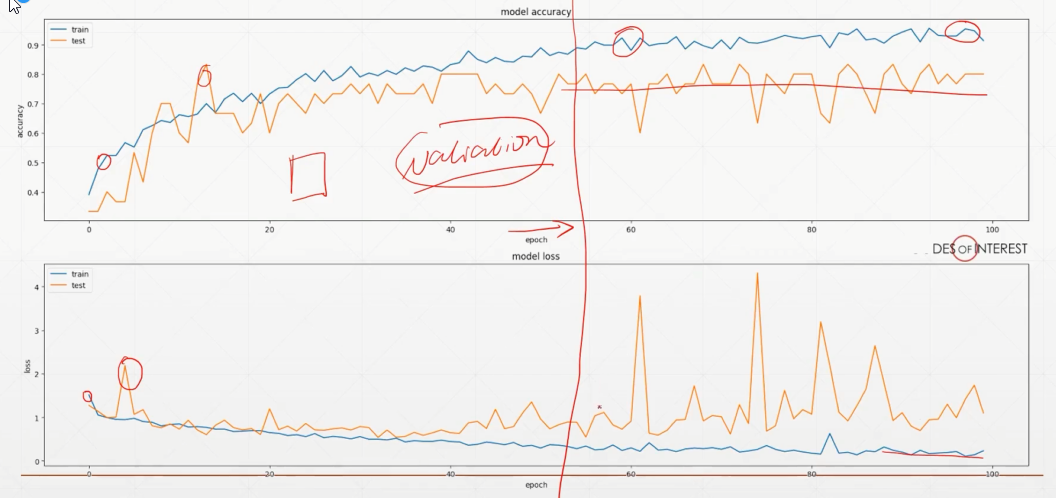
计算正确率:
即预测对的概率
- 首先,建立一个4*10的张量,表示4张图片,每个图片可能有10个结果,作为假设的输出结果。
- 然后利用softmax函数进行归一化,发现size并不会因为归一化而变化。
- 然后利用argmax函数提取向量中最大的元素的位置,作为预测标签。
- 输出预测标签为[9,5,9,4],即预测手写数字的值。
- 当然,即时不使用softmax函数进行归一化,也不影响预测标签的结果。这里直接从假设的logits输出的预测标签与使用softmax函数一致,也为[9,5,9,4]。
- 输出实际label=[9,3,2,4]
- 利用eq函数检验标签是否一致,一致则输出1,否则输出0。结果为[1,0,0,1]
- 最后求得正确率=0.5=50%。
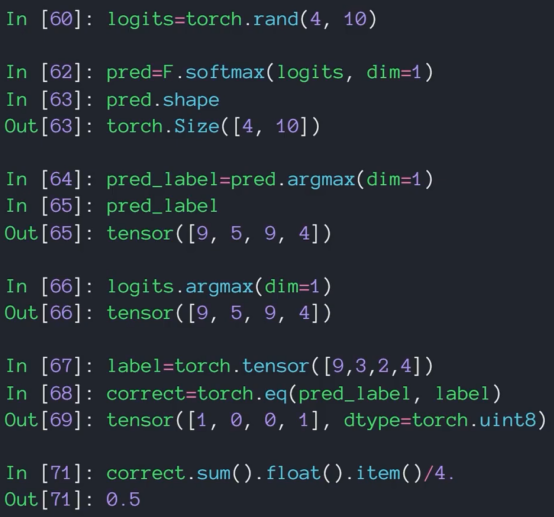
什么时候做试验得到实时准确率?
Batch:一批数据。仅使用训练集中的一小批数据训练,用完后立即反向传播更新参数,即等于一次迭代。
Epoch:一代训练。使用训练集里所有的数据进行训练。
因此,如果有1000张可供训练的图片,分成200个一组进行训练,5次batch迭代后可完成一次epoch。
- 可以每几次batch后测试一下准确度,即迭代几次后就更新。
- 也可以在一个完整的epoch后进行测试。
- 还可以几个epoch后再训练。
- 以上三种检测频率逐渐降低,因此可以花更多的时间在训练网络上。

这里每个epoch进行一次准确率的计算。Correct表示预测正确的图片数量,len(test_loader.dataset)表示总的图片数量,二者一除就是正确率。
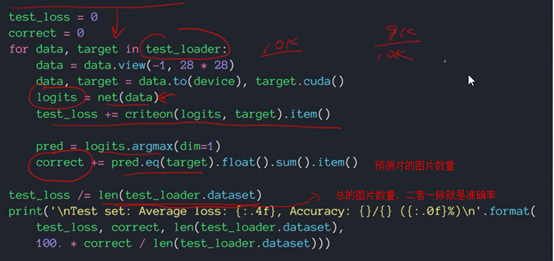
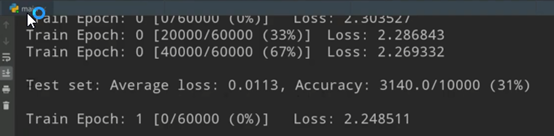
打印结果:这里共有10000个测试数据;60000个训练数据epoch,并把20000个作为一个数据组batch,共3个batch。每组计算完便返回更新参数,因此先显示本轮的loss函数的结果。
当一轮epoch结束后,进行测试,报告测试集的平均loss为0.01,准确率为3140/10000,为31%。
网络训练监测的可视化工具1:tensorboardX
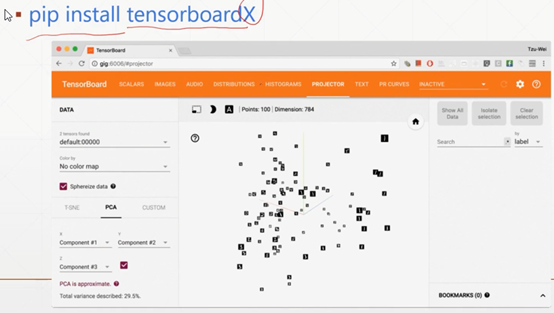
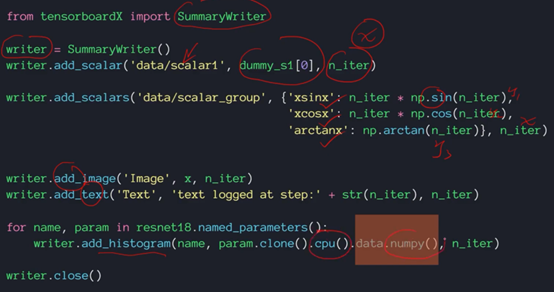
这是使用tensorboardX的方法:
首先导入其监测函数summarywriter
然后定义需要写入的监测参数,并加入坐标中。
接着可以加入图片和一些描述文本
最后加入直方图。
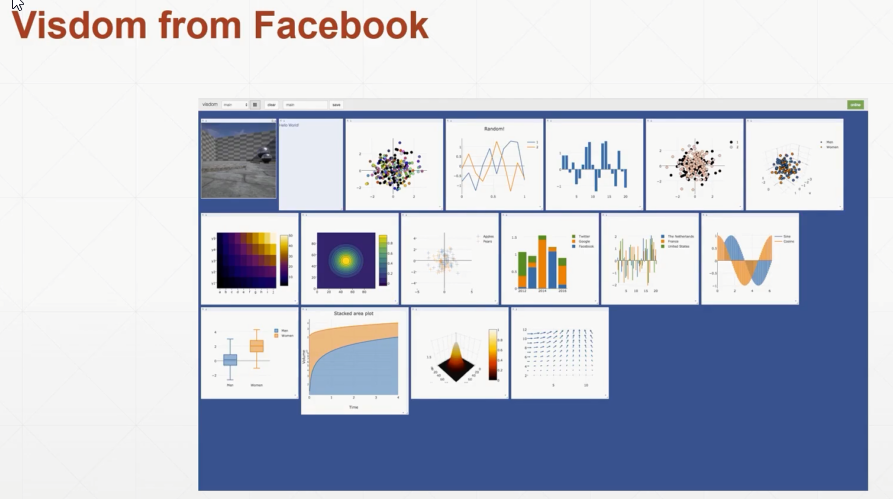
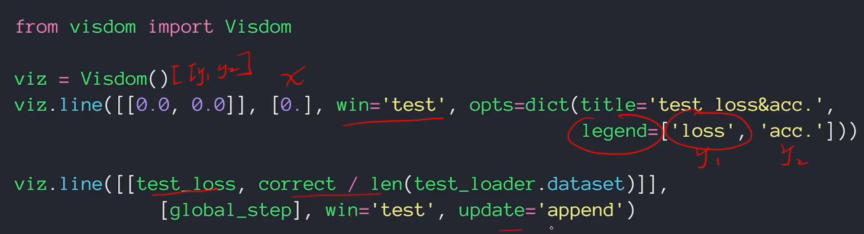
网络训练监测的可视化工具2:visdom
(一个web服务器,程序给它数据,它在web上显示)
更加强大,速度更快,是Facebook的亲儿子。可以同时监听多个参数。
比如说先创建一个可视化表:viz.line([[y轴第一个参数,y轴第二个参数]][x轴参数],标签分别为loss和acc)
然后将数据填充进去,并进行实施附加更新append。
最后
以上就是简单皮卡丘最近收集整理的关于3D机器学习(8):GPU加速、计算正确率、训练监测可视化tensorboardX和visdom的全部内容,更多相关3D机器学习(8)内容请搜索靠谱客的其他文章。








发表评论 取消回复