Python爬虫学习
文章目录
- Python爬虫学习
- 一、抓包工具
- 二、代码实现
- 三、代码参数
一、抓包工具
打开豆瓣电影喜剧排行榜页面源代码
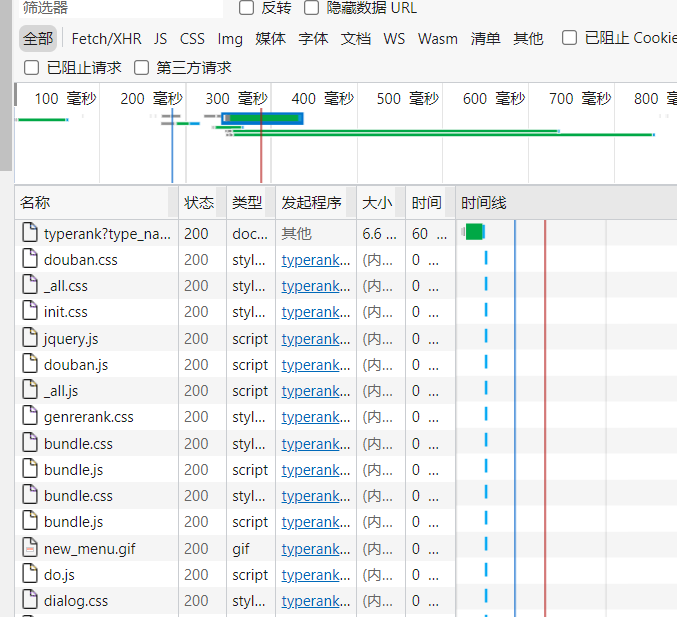
我们可以看到有很多数据,上面有个XHR
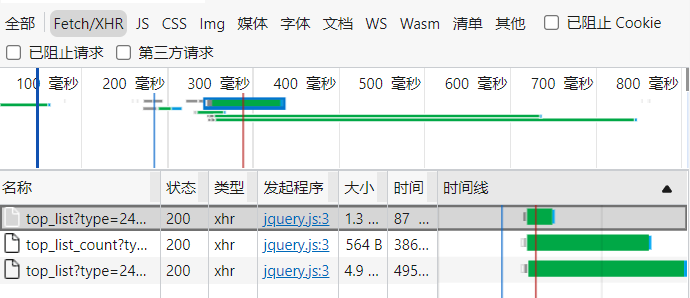
XHR用于筛选数据
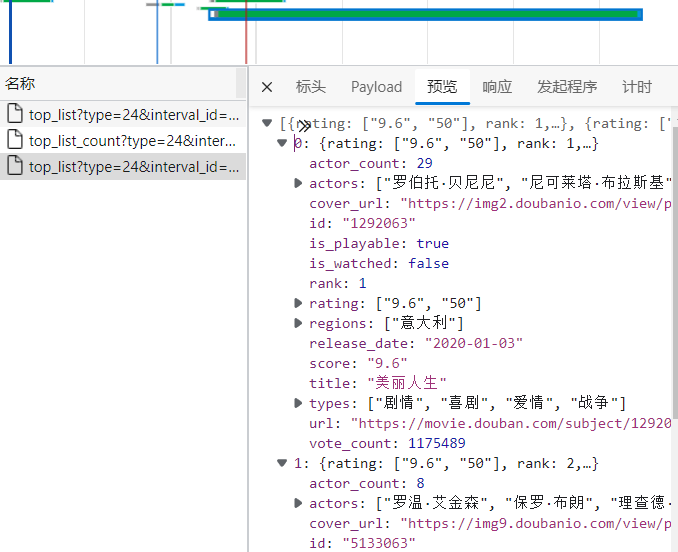
你会发现相关数据都在这个里面,前面提到怎么获取,现在我们可以通过这个URL获取
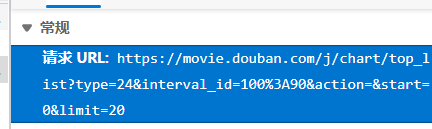
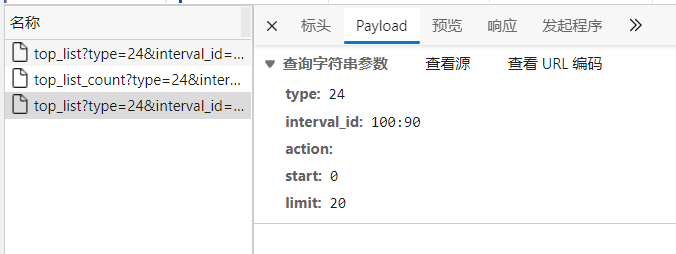
这个URL很复杂,这是一个带有参数的URL, “?”后面是我们的参数
在Payload可以看到相关参数
二、代码实现
上面提到这个URL非常长,我们在写爬虫程序的时候,如果你发现GET请求的url很复杂,这个时候可以重新封装参数,只取问号前面的东西,然后将参数复制,写成一个字典的形式
url="https://movie.douban.com/j/chart/top_list0"
#重新封装参数
p={"type": "24",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20}
前面提到过带有参数的post请求用data参数进行传递,而get请求用params参数进行传递
resp=requests.get(url,params=p )
import requests #导入requests
url="https://movie.douban.com/j/chart/top_list0"
p={"type": "24",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20}
resp=requests.get(url,params=p )
print(resp.request.url)

解释一下resp.request.url()
前面介绍过resp是返回的响应,响应从什么发起的找到请求对象(request),请求对象里放着url
然后我们查看相关信息
import requests #导入requests
url="https://movie.douban.com/j/chart/top_list0"
p={"type": "24",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20}
resp=requests.get(url,params=p )
print(resp.text)

你会发现没有任何东西,如果你的参数没有错误,这个时候只有一种可能,你被反爬了。
前面介绍过如何伪装自己的爬虫程序,这里就不过多的赘述了
import requests #导入requests
url="https://movie.douban.com/j/chart/top_list"
p={"type": "24",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20}
h={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36 Edg/98.0.1108.43"
}
resp=requests.get(url=url,params=p,headers=h)
print(resp.text)
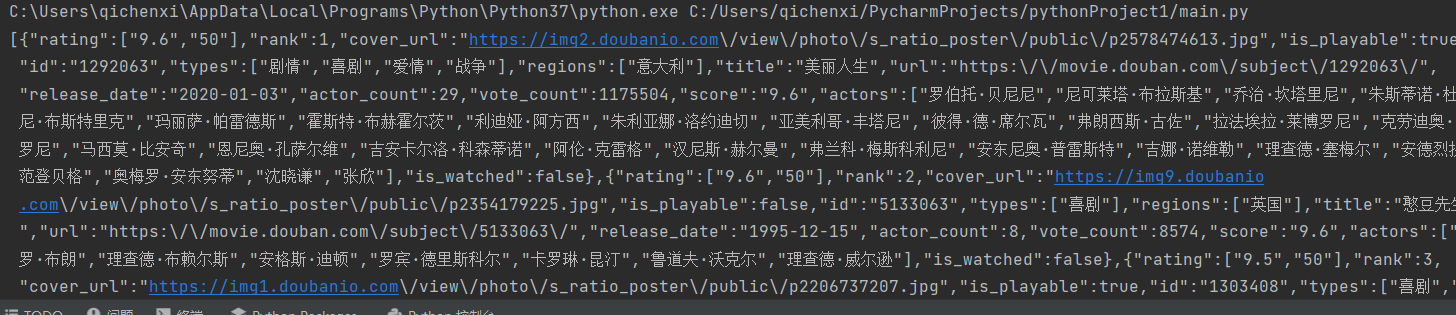
转成相应的格式
import requests #导入requests
url="https://movie.douban.com/j/chart/top_list"
p={"type": "24",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20}
h={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36 Edg/98.0.1108.43"
}
resp=requests.get(url=url,params=p,headers=h)
print(resp.json()) #json格式

三、代码参数
先看源代码参数
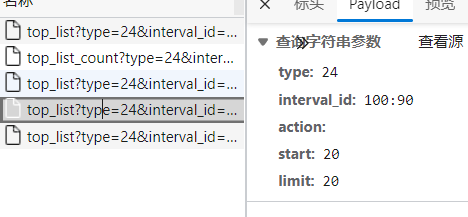
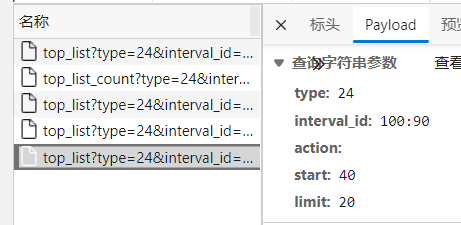
每次鼠标向下滑动就会多出来一些数据,你会发现参数只有start发生了改变,所以我们可以通过修改代码中的start来抓取数据。
import requests #导入requests
url="https://movie.douban.com/j/chart/top_list"
p={"type": "24",
"interval_id": "100:90",
"action": "",
"start": 20, #修改的参数
"limit": 20}
h={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36 Edg/98.0.1108.43"
}
resp=requests.get(url=url,params=p,headers=h)
print(resp.json())
爬取完数据后一定要关掉resp,如果长时间访问,之后访问就会报错
resp.close()
import requests #导入requests
url="https://movie.douban.com/j/chart/top_list"
p={"type": "24",
"interval_id": "100:90",
"action": "",
"start": 20,
"limit": 20}
h={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36 Edg/98.0.1108.43"
}
resp=requests.get(url=url,params=p,headers=h)
print(resp.json())
resp.close()#关掉resp
最后
以上就是雪白蜡烛最近收集整理的关于Python爬虫学习——Requests入门三(六)Python爬虫学习一、抓包工具二、代码实现三、代码参数的全部内容,更多相关Python爬虫学习——Requests入门三(六)Python爬虫学习一、抓包工具二、代码实现三、代码参数内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复