Impala是一个高性能的OLAP引擎,Impala本身只是一个OLAP-SQL引擎,它访问的数据存储在第三方引擎中,第三方引擎包括HDFS、Hbase、kudu。对于HDFS上的数据,Impala支持多种文件格式,目前可以访问Parquet、TEXT、avro、sequence file等。对于HDFS文件格式,Impala不支持更新操作,这主要限制于HDFS对于更新操作的支持比较弱。本文主要介绍Impala是如何访问HDFS数据的,Impala访问HDFS包括如下几种类型:1、数据访问(查询);2、数据写入(插入);3、数据操作(重命名、移动文件等)。本文将详细介绍Impala是如何在查询执行过程中从HDFS获取数据,也就是Impala中HdfsScanNode的实现细节。
本文是Impala系列文章的一篇,关于Impala的介绍相关的文章可以参考:Impala查询详解第一篇——简介 和 大数据时代快速SQL引擎-Impala
数据分区
Impala执行查询的时首先在FE端进行查询解析,生成物理执行计划,进而分隔成多个Fragment(子查询),然后交由Coordinator处理任务分发,Coordinator在做任务分发的时候需要考虑到数据的本地性,它需要依赖于每一个文件所在的存储位置(在哪个DataNode上),这也就是为什么通常将Impalad节点部署在DataNode同一批机器上的原因,为了揭开Impala访问HDFS的面纱需要先从Impala如何分配扫描任务说起。
众所周知,无论是MapReduce任务还是Spark任务,它们执行的之前都需要在客户端将输入文件进行分割,然后每一个Task处理一段数据分片,从而达到并行处理的目的。Impala的实现也是类似的原理,在生成物理执行计划的时候,Impala根据数据所在的位置将Fragment分配到多个Backend Impalad节点上执行,那么这里存在两个核心的问题:
- Impala如何获取每一个文件的位置?
- 如何根据数据位置分配子任务?
在之前介绍的Impala的总体架构可以看到,Catalogd节点负责整个系统的元数据,元数据是以表为单位的,这些元数据具有一个层级的关系,如下图所示
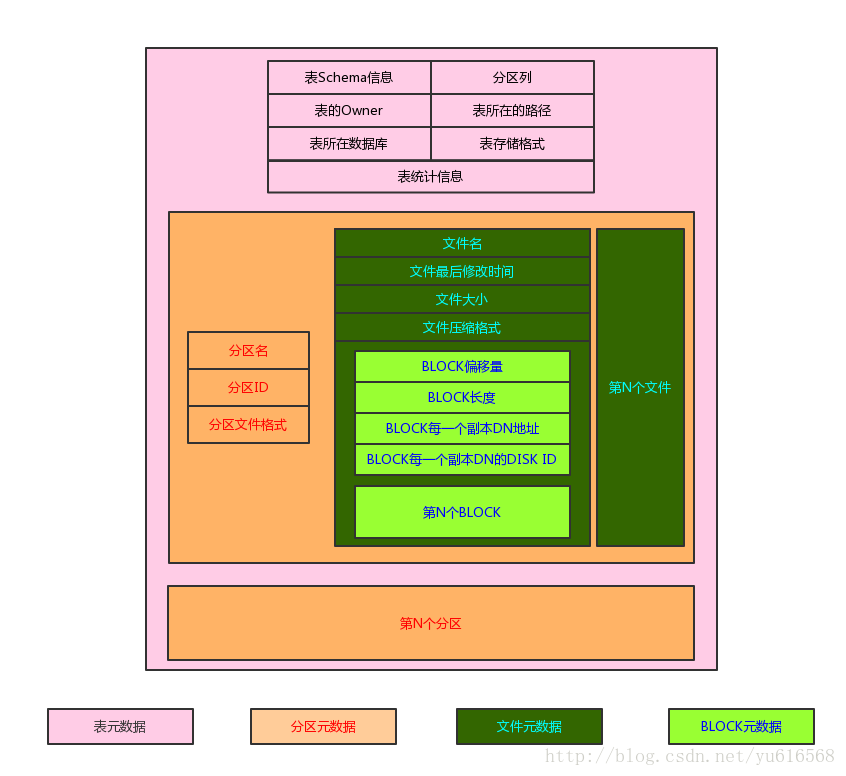
Impala表元数据结构
每一个表包含如下元数据(只选取本文需要用到的):
- schema信息:该表中包含哪些列,每一列的类型是什么等
- 表属性信息:拥有者、数据库名、分区列、表的根路径、表存储格式。
- 表统计信息:主要包括表中总的记录数、所有文件总大小。
- 分区信息:每一个分区的详细信息。
每一个分区包含如下信息:
- 分区名:由所有的分区列和每一列对应的值唯一确定的
- 分区文件格式:每一个分区可以使用不同的文件格式存储,解析时根据该格式而非表中的文件存储格式,如果创建分区时不指定则为表的存储格式。
- 分区的所有文件信息:保存了该分区下每一个文件的详细信息,这也导致了重新写入数据之后需要REFRESH表。
每一个文件包含如下的信息:
- 该文件的基本信息:通过FileStatus对象保存,包括文件名、文件大小、最后修改时间等。
- 文件的压缩格式:根据文件名的后缀决定。
- 文件中每一个BLOCK的信息:因为HDFS存储文件是按照BLOCK进行划分的,因此Impala也同样存储每一个块的信息。
每一个BLOCK包含如下的信息:
- 这个BLOCK处于文件的偏移量、BLOCK长度。
- 这个BLOCK所在的Datanode节点:每一个BLOCK默认会被存储多个副本,分布在不同的Datanode上。
- 这个BLOCK所在的Datanode的Disk信息:这个BLOCK存储在对应的Datanode的哪一块磁盘上,如果查询不到则返回-1表示未知。
任务分发
从上面的元数据描述可以解答我们的第一个问题,每一个表所拥有的全部文件信息都在表加载的时候由Impala缓存并且通过statestored同步到每一个impalad节点缓存,在impalad生成HdfsScanNode节点时会首先根据该表的过滤条件过滤掉不必要的分区(分区剪枝),然后遍历每一个需要处理分区文件,获取每一个需要处理的BLOCK的基本信息和位置信息,返回给Coordinator作为分配HdfsScanNode的输入。这里还有一个问题:每一个分配的range是多大呢?这个依赖于查询的配置项MAX_SCAN_RANGE_LENGTH,这个配置项表示每一个扫描的单元的最大长度,根据该配置项得到每一个range的大小为:
- MAX_SCAN_RANGE_LENGTH : 如果配置了该配置项并且该配置项小于BLOCK大小。
- BLOCK大小 : 如果配置了MAX_SCAN_RANGE_LENGTH但是该配置值大于HDFS的BLOCK大小。
- BLOCK大小 : 如果没有配置MAX_SCAN_RANGE_LENGTH
- 整个文件大小 : 如果文件的大小小于一个HDFS的BLOCK大小。
到这一步得到了每一个HdfsScanNode扫描的range列表,每一个range包含所属的文件、该range的起始偏移量和长度,以及该range所属的BLOCK所在的DataNode地址、在DataNode的Disk id以及该BLOCK是否已被HDFS缓存等信息。
完成了SQL解析,Coordinator会根据分配的子任务(本文只关心HdfsScanNode)和数据分布进行任务的分发,分发的逻辑由Coordinator的Scheduler::ComputeScanRangeAssignment函数完成,由于每一个range包含了存储位置,Impala会首先根据每一个BLOCK是否已被缓存,或者是否存储在某一个impalad本地节点上,前者表示可以直接从缓存(内存)中读取数据,后者意味着可以通过shortcut的方式读取HDFS数据,这里需要提到一个读取距离的概念,Impala中将距离从近到远分为如下几种:
- CACHE_LOCAL : 该range已缓存,并且缓存的DataNode是一个impalad节点
- CACHE_RACK : 该range已缓存,并且缓存在相同机架的DataNode上,目前没有使用。
- DISK_LOCAL : 该range可以从本地读取,意味着该BLOCK所在的DataNode和处理该BLOCK的impala在同一个机器上。
- DISK_RACK : 该range可以从同一个机架的磁盘读取,目前没有使用。
- REMOTE : 该range不能通过本地读取,只能通过HDFS远程读取的方式获取。
客户端查询的时候可以设置REPLICA_PREFERENCE配置项,该配置项表示本次查询更倾向于使用哪种距离的副本,默认为0表示CACHE_LOCAL,其他的配置有3和5,分别表示DISK_LOCAL和REMOTE。另外可以配置DISABLE_CACHED_READS设置是否可以从缓存中读取,除此之外,可以在SQL的hints中设置默认读取的距离。最后,可以在SQL的hints中设置是否随机选择副本,有了这两个配置接下来就可以根据range的位置计算每一个range应该被哪个impalad处理。
处理range的分配首先需要计算出该range的最短距离,分为两种情况:
- 如果最短的距离是REMOTE,表示该range所在的DataNode没有部署impalad节点,这种range从所有impalad中选择一个目前已分配的range字节数最少的impalad。
- CACHE_LOCAL和DISK_LOCAL的区别在于前者可以随机选择,此时可以从所有满足条件的副本(该副本的距离等于最短距离)随机选择一个impalad分配,否则分配到已分配的字节数最少的impalad。
讲到这里,也就回答了上面的第二个问题,Impala根据每一个range所在的位置分配到impalad上,尽可能的做到range的分配更均衡并且尽可能的从本地甚至缓存中读取。接下来需要看一下HdfsScanNode是如何运行的。
HdfsScanNode的实现
前面我们提到过,HdfsScanNode的作用是从保存在HDFS上的特定格式的文件读取数据,然后对其进行解析转换成一条条记录,将它们传递给父执行节点处理,因此下面介绍的过程主要是在已知扫描哪些数据的情况下返回所有需要获取的记录。在这之前,可以先看一下BE模块的ScanNode的类结构:

Impala执行节点类层次
集合上图和Impala执行逻辑,SQL生成的物理执行计划中每一个节点都是ExecNode的子类,该类提供了6个接口:
- Init函数:该函数在创建ExecNode节点的时候被调用,参数分别是该执行节点的详细描述信息和整个Fragment的上下文。HdfsScanNode初始化的时候会解析runtime filter信息和查询中指定的该表的filter条件。另外还初始化一些该节点的统计指标。
- Prepare函数:该函数在Fragment执行Prepare函数的时候递归的调用该子树所有节点的Prepare函数,HdfsScanNode的Prepare函数初始化该表的描述信息以及需要读取并交给父节点的记录包含哪些列,初始化每一个range扫描的信息(创建Hdfs handler等)。
- Codegen函数:该函数实现每一个节点的codegen,Impala利用LLVM实现codegen的功能,减少虚函数的调用,一定程度上提升了查询性能,HdfsScanNode在Codegen中生成每一种文件格式的codegen。
- Open函数:该函数在执行之前被调用,完成执行之前的初始化工作,在HdfsScanNode的Open函数中初始化最大的scanner线程数,并且注册ThreadTokenAvailableCb函数用于启动新的scanner线程。
- GetNext函数:该函数每次输出一个row_batch,并且传入eos变量用于设置该节点是否执行完成,HdfsScanNode会被父节点循环的调用,每次返回一个row_batch。
- Clode函数:该函数在完成时被调用,处理一些资源释放和统计的操作。
对于每一个ExecNode,真正执行逻辑一般是在Open和GetNext函数中,在HdfsScanNode节点中也是如此,刚才提到Open函数中会注册一个回调函数,该函数被调用时会判断当前是否需要启动新的scanner线程,那么是scanner线程又是什么呢?这里就需要介绍一下impalad执行数据扫描的模型,impalad执行过程中会将数据读取和数据扫描分开,数据读取是指从远程HDFS或者本地磁盘读取数据,数据扫描是指基于读取的原始数据对其进行转换,转换之后的就是一条条记录数据。它们的线程模型和关系如下图所示:
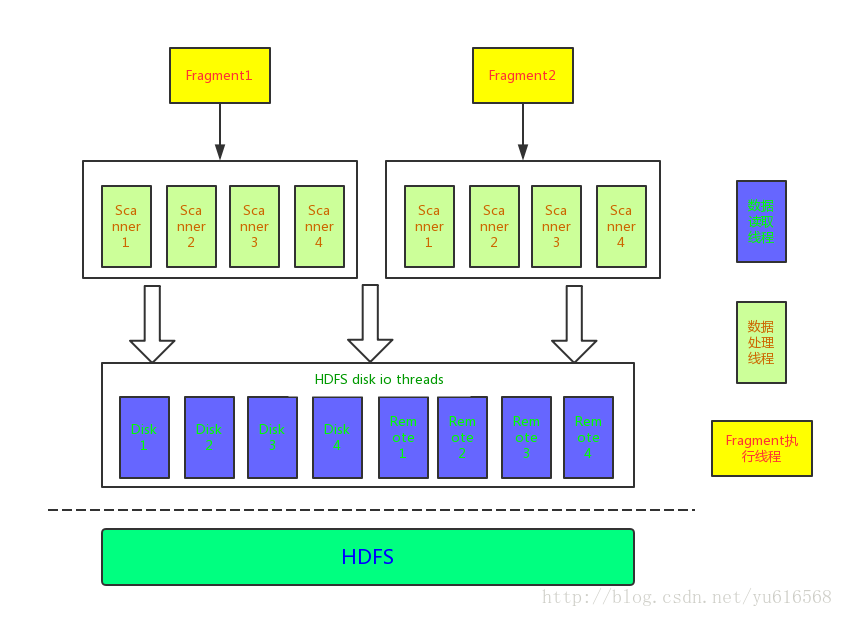
Impala数据处理线程模型
我们从下往上看这个处理模型,最底层的线程池是HDFS数据I/O线程池,这个线程池在impalad初始化的时候启动和初始化,impalad将这些线程分为本地磁盘线程和远程访问数据线程,本地磁盘线程需要为每一个磁盘启动一组线程,它根据系统配置num_threads_per_disk项决定,默认情况下对于每一个机械磁盘启动1个线程,这样可以避免大量的随机读取(避免大量的磁盘寻道);对于FLASH磁盘(SSD),默认情况对于每一块磁盘启动8个线程。远程数据访问线程数由系统配置num_remote_hdfs_io_threads决定,默认情况下启动8个线程,每一个线程拥有一个阻塞队列,Scanner线程通过传递共享变量ScanRange对象,该对象包含读取数据的输入:文件、range的偏移量,range的长度,磁盘ID等,在读取的过程中会向该对象中填充读取的一个个内存块,内存块的大小决定了每次从HDFS中读取的数据的大小,默认是8MB(系统配置项read_size配置),并且在ScanRange对象中记录本地读取数据和远程读取数据大小,便于生成该查询的统计信息。
将数据读取和数据解析分离是为了保证本地磁盘读写的顺序性以及远程数据读取不占用过量的CPU,而Scanner线程的执行需要依赖于Disk线程,Scanner线程的启动是由回调函数ThreadTokenAvailableCb触发的,我们下面在做介绍,当调用getNext方法获取一个个row_batch时,HdfsScanNode会判断是否是第一次调用,如果是第一次调用会触发所有需要扫描的range的请求下发到Disk I/O线程池,扫描操作需要根据文件类型扫描不同的区域,例如对于parquet总是需要扫描文件的footer信息。这里需要提到一个插曲,如果该表需要使用runtime filter需要在扫描文件之前等待runtime filter到达(超时时间默认是1s)。
我们可以假设,在第一个getNext调用之后,所有的数据都已经被读取了,虽然可能有的range的数据读取被block了(可能未被调度或者内存已经使用到了上线),但是这些对于scanner线程是透明的,scanner线程只需要从reader_context_对象中获取已读取的数据(获取数据的操作可能阻塞)进行解析的处理。到这里,数据已经被I/O线程读取了,那么什么时候会启动Scanner线程呢?
数据解析和处理
前面提到Scanner线程的启动是ThreadTokenAvailableCb函数触发的,当每次向Disk线程池中请求RangeScan请求时会触发该函数,该函数需要根据当前Fragment和系统中资源使用的情况决定启动多少Scanner线程,当每一个Scanner线程执行完成之后会重新触发该回调函数启动新的Scanner线程。每一个Scanner线程分配一个ScanRange对象,该对象中保存了一个分区的全部数据。最后调用ProcessSplit函数,该函数处理这个分区的数据解析。
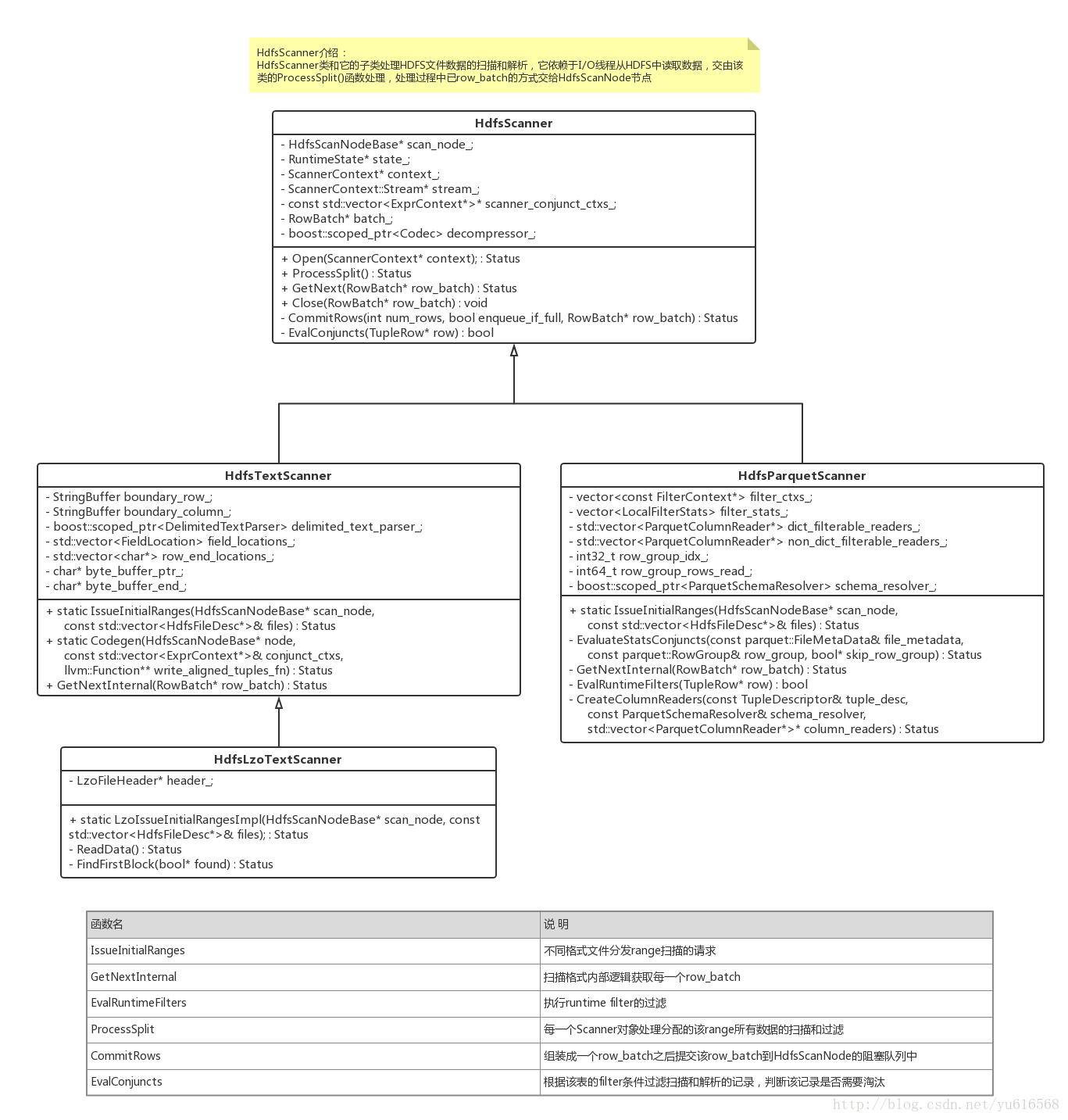
HDFS文件数据处理类层次
上图描述了不同HDFS文件类型的Scanner类结构,不同的文件类型使用不同的Scanner进行扫描和解析,这里我们以比较简单的TEXT格式为例来说明该流程,TEXT格式的表需要在建表的时候指定行分隔符、列分隔符等元数据,分区数据的解析依赖于这些分隔符配置。为了提升解析性能,Impala使用了Codegen计数和SSE4指令,但是由于分区的划分是按照BLOCK来的,而每一个BLOCK绝大部分情况下其实和结束都处于一条记录的中间,而且每次读取数据的缓存是8MB大小,每一块缓存中的数据还是可能处于记录的中间,这些情况都需要特殊处理。Impala处理每一个分区的时候首先扫描到该分区的第一条记录,当处理完成该分区,如果分区的结尾是一条不完整的记录则继续往下扫描到该记录结束位置。而正常情况下,Scanner只需要根据行分隔符解析出每一行,对于每一行根据需要解析的列将其保存,而直接跳过不需要解析的列,但是对于TEXT这种行式存储的文件格式需要首先读取全部的数据,然后遍历全部的数据,而对于Parquet之类的列式存储,虽然也需要读取每一个分区的数据,但是由于每一列的数据存储在一起,扫描的时候只需要扫描需要的列。这才是列式存储可以减少数据的扫描,而不是较少数据的读取。当然Parquet文件一般使用数据压缩算法使得数据量远小于TEXT格式。
无论是哪种文件格式,通过解析器解析出一条条记录,每一条记录中只包含该表需要读取的列的内容,组装成一条记录之后会通过该表的filter条件和runtime filter判断该条记录是否需要被淘汰。可以看出,ScanNode执行了Project和谓词下推的功能。所有没被淘汰的记录按照row_batch的结构组装在一起,每一个row_batch默认情况下是1024行,查询客户端可以使用BATCH_SIZE配置项设置。但是过大的row_batch大小需要占用更大的内存,可能降低ExecNode之间的并发度,因为ExecNode需要等到子节点完成一个row_batch的组装才进行本节点的计算。由于Scan操作是由Scanner线程中完成的,每次Scanner组装完成之后将其放到一个BlockingQueue中,等待父节点从该Queue中获取进行自身的处理逻辑,当然可能存在父节点和子节点执行频率不一致的情况,导致BlockingQueue队列被放满,此时Scanner线程将被阻塞,并且也不会创建新的Scanner线程。
数据压缩
最后我们简单的聊一下文件压缩,通常在聊到OLAP优化方式的时候都会提到数据压缩,相同的数据压缩之后可以有很大程度的数据体积的降低,但是通过学习impala的数据读取流程,impala通过文件名的后缀判断文件使用了哪种压缩算法,对于使用了压缩的文件,虽然读取的数据量减少了许多,但是需要消耗大量的CPU资源进行解压缩,解压缩之后的数据其实和非压缩的数据是一样的,因此对于解析操作处理的数据量两者并没有任何差异。因此使用数据压缩只不过是一个I/O资源换取CPU资源的常用手段,当一个集群中I/O负载比较高可以考虑使用数据压缩降低I/O消耗,而相反CPU负载比较高的系统则通常不需要进行数据压缩。
总结
好了,在结束之前我们总结一下Impala读取HDFS数据的逻辑,首先Impala会将数据扫描和数据读取线程分离,Impalad在启动的时候初始化所有磁盘和远程HDFS访问的线程,这些线程负责所有数据分区的读取。Impala对于每一个SQL查询根据表的元数据信息对每一个表扫描的数据进行分区(经过分区剪枝之后),并记录每一个分区的位置信息。BE根据每一个分区的位置信息对子任务进行分配,尽可能保证数据的本地读取和任务分配的均衡性。每一个子任务交给不同的Backend模块执行,首先会为子任务创建执行树,HdfsScanNode节点负责数据的读取和扫描,通常是执行树的孩子节点,执行时首先将该HdfsScanNode需要扫描的分区请求Disk I/O线程池执行数据读取,然后创建Scanner线程处理数据扫描和解析,解析时根据不同的文件类型创建出不同的Scanner对象,该对象处理数据的解析,组装成一个个的row_batch对象交给父节点执行。直到所有的分区都已经被读取并完成扫描和解析。
本文详细介绍了Impala如何实现HdfsScanNode执行节点,该节点是所有查询SQL获取数据的源头,因此是十分重要的,当然Impala支持的HDFS格式还是比较有限的,对于ORC格式不能够支持,而对于JSON格式的扫描我们完成各内部的开发版本,有待于进一步性能优化,本文中提到了数据扫描过程中会根据过滤条件和runtime filter进行数据的过滤,这种谓词下推也是各种大数据引擎性能优化的一大要点,而runtime filter可谓是impala的独家秘笈,下一篇文章我们将详细介绍这一神秘特性的实现原理。
最后
以上就是大胆皮带最近收集整理的关于Impala高性能探秘之HDFS数据访问的全部内容,更多相关Impala高性能探秘之HDFS数据访问内容请搜索靠谱客的其他文章。








发表评论 取消回复