源码下载地址:http://download.csdn.net/detail/huhui_bj/5645641
opencsv下载地址:http://download.csdn.net/detail/huhui_bj/5645661
地震数据下载地址:http://download.csdn.net/detail/huhui_bj/5645685
1 项目说明
本文实现的是用Hadoop的MapReduce计算框架,对国内2013年1月至6月这半年以来的地震数据进行了统计和分析。分别按照地震时间和地震地点进行分析。
地震数据来源于国家地震科学数据共享中心,地址:
http://data.earthquake.cn/data/index.jsp?no11&number=28
2 项目准备
首先是开发环境,我所使用的是Eclipse开发环境,eclipse中集成了hadoop开发插件。如何安装单机hadoop,请移步
hadoop安装
从国家地震科学数据共享中心下载下来的数据是excel文件,需要转化成CSV文件,这样便于解析。CSV文件中的数据大约有20000条左右,是这半年以来全国各地的地震情况监测数据。全国各地每天都有很多个小型地震发生。其中大部分发生在地壳深处,没有人能高觉到,尽管如此,地震监听站仍会记录这些小型地震。
下面是几行地震数据
日期,时间,纬度(°),经度(°),深度(km),震级类型,震级值,事件类型,参考地名
2013-06-25,06:04:13.0,10.70,-42.60,10,Ms,6.5,eq,中大西洋海岭北部
2013-06-24,14:34:48.7,44.33,84.10,6,Ms,4.1,eq,新疆维吾尔自治区塔城地区乌苏市
2013-06-24,13:02:01.9,44.31,84.17,8,Ms,4.3,eq,新疆维吾尔自治区塔城地区乌苏市
2013-06-24,11:44:20.8,39.42,95.50,6,Ms,3.4,eq,甘肃省酒泉市肃北蒙古族自治县
下面,提出两个问题:
a. 每天有多少次地震发生;
b. 这六个月的时间内,各个地点总共发生了多少次地震。
3 程序说明
3.1 解析CSV文件
CSV文件前面两行是文件头,其它每一行都是一系列逗号分隔开的数据值。我们只对3列数据感兴趣:日期、地点和震级。为了解析CSV文件,我们使用了一个很棒的开源库opencsv,用它能够很容易的解析CSV文件。
我们从CSV文件中复制一条数据作为测试数据,确认我们可以用opencsv来获取我们想要的信息。
/**
* 测试读取csv文件中的地震数据
*/
package com.eq.test;
import java.io.IOException;
import au.com.bytecode.opencsv.CSVParser;
public class CSVProcessingTest {
/**
* @param args
*/
// 从csv文件复制一行数据
private final String LINE = "2013-06-23,22:31:30.3,24.70,99.21,5,ML,1.4,eq,云南施甸";
public void testReadingOneLine() {
String[] lines = null;
try {
// 用opencsv解析
lines = new CSVParser().parseLine(LINE);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 打印解析结果
for (String line : lines) {
System.out.println(line);
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
CSVProcessingTest csvProcessingTest = new CSVProcessingTest();
csvProcessingTest.testReadingOneLine();
}
}3.2 编写map函数
EarthQuakeLocationMapper类继承了hadoop的Mapper对象。它指定输出键为一个Text对象,将其值制定为IntWritable,IntWritable实质上是一个整数。而LongWritable和Text分别表示字节数和文本行数。
/**
* 统计地震次数的区域的map
*/
package com.eq.map;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import au.com.bytecode.opencsv.CSVParser;
public class EarthQuakeLocationMapper extends
Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
if (key.get() > 0) {
String[] lines = new CSVParser().parseLine(value.toString());
context.write(new Text(lines[8]), new IntWritable(1));
}
}
}
"四川汶川":[1,1,1,1,1,1,1,1]
"甘肃天祝":[1,1,1,1]
"广西平果":[1,1,1,1,1,1]"四川汶川":[8]
"甘肃天祝":[4]
"广西平果":[6]3.3 编写reduce函数
reduce实现如下。与Mapper一样,Reducer被参数化了:前两个参数是传入的键类型(Text)和值类型(IntWritable),后两个参数是输出类型:键和值。
package com.eq.reduce;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class EarthQuakeLocationReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count++;
}
if (count >= 10) {
context.write(key, new IntWritable(count));
}
}
}
"四川汶川":[1,1,1,1,1,1,1,1] --> "四川汶川":83.3 编写Hadoop的Job
现在我们已经写完了map和reduce,接下来要做的就是将所有这一切链接到一个Hadoop的Job。定义一个Job比较简单:你需要提供输入和输出、map和reduce实现以及输出类型。
/**
* 定义一个hadoop job,用于统计不同地域的地震次数
*/
package com.eq.job;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.eq.map.EarthQuakeLocationMapper;
import com.eq.map.EarthQuakesPerDateMapper;
import com.eq.reduce.EarthQuakeLocationReducer;
import com.eq.reduce.EarthQuakesPerDateReducer;
import org.apache.hadoop.io.Text;
public class EarthQuakesLocationJob {
/**
* @param args
*/
public static void main(String[] args) throws Throwable {
// TODO Auto-generated method stub
Job job = new Job();
job.setJarByClass(EarthQuakesLocationJob.class);
FileInputFormat.addInputPath(job, new Path("hdfs://localhost:9000/input/earthquake_data.csv"));//csv文件所在目录
FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/output"));
job.setMapperClass(EarthQuakeLocationMapper.class);
job.setReducerClass(EarthQuakeLocationReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true)?0:1);
}
}
3.4程序运行结果
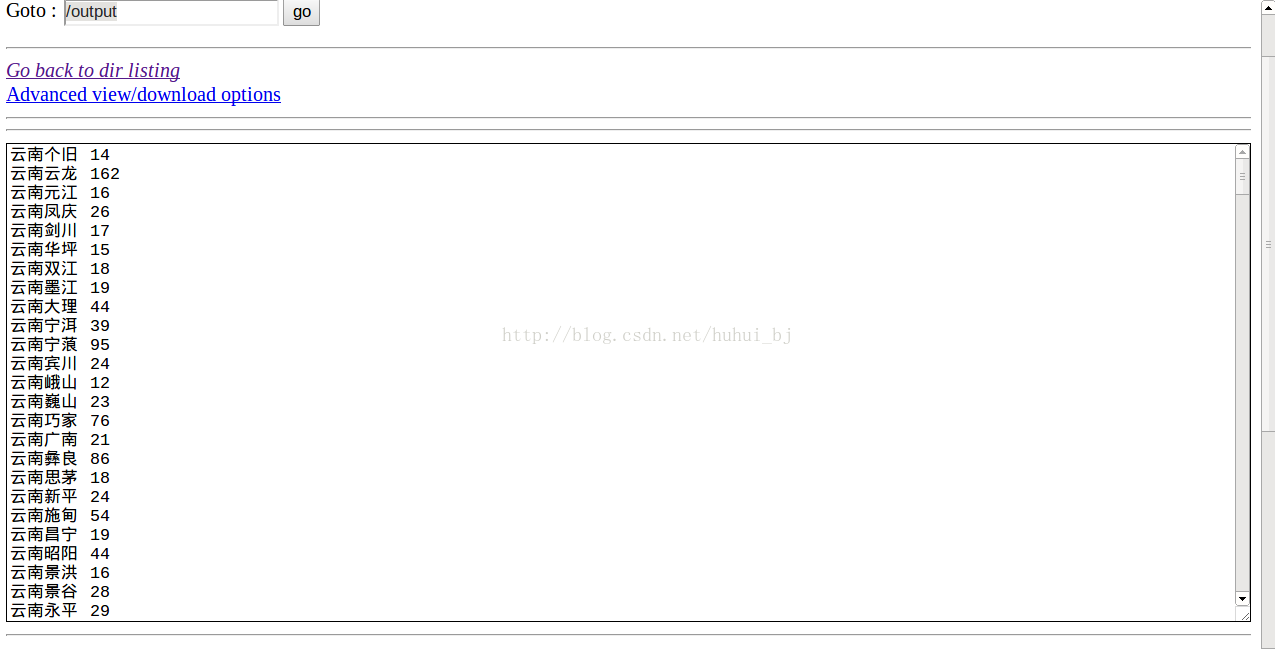
reduce输出的结果,可以在
http://localhost:50070中查看。以上只是结果的一部分。
通过上文的叙述,我们解答了前文提到的两个问题的第二个问题。还有第一个问题,就是统计每个时间地震发生的次数。
在源代码中,map函数如下:
/**
* map函数的实现
*/
package com.eq.map;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import au.com.bytecode.opencsv.CSVParser;
public class EarthQuakesPerDateMapper extends
Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException {
if (key.get() > 0) {
try {
// csv解析器
CSVParser parser = new CSVParser();
// 解析csv数据
String[] lines = parser.parseLine(value.toString());
String dtstr = lines[0];
//map输出
context.write(new Text(dtstr), new IntWritable(1));
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
}
}
reduce函数如下:
package com.eq.reduce;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class EarthQuakesPerDateReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count++;
}
context.write(key, new IntWritable(count));
}
}
Job如下:
/**
* 定义一个hadoop job
*/
package com.eq.job;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.eq.map.EarthQuakesPerDateMapper;
import com.eq.reduce.EarthQuakesPerDateReducer;
import org.apache.hadoop.io.Text;
public class EarthQuakesPerDayJob {
/**
* @param args
*/
public static void main(String[] args) throws Throwable {
// TODO Auto-generated method stub
Job job = new Job();
job.setJarByClass(EarthQuakesPerDayJob.class);
FileInputFormat.addInputPath(job, new Path("hdfs://localhost:9000/input/all_month.csv"));//csv文件所在目录
FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/output"));
job.setMapperClass(EarthQuakesPerDateMapper.class);
job.setReducerClass(EarthQuakesPerDateReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true)?0:1);
}
}
最后
以上就是壮观银耳汤最近收集整理的关于基于Hadoop的地震数据分析统计1 项目说明2 项目准备3 程序说明的全部内容,更多相关基于Hadoop的地震数据分析统计1内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复