目录
第一章 绪论 1
1.1 课题的研究背景 1
1.2 语音增强的历史和发展现状 1
1.3 本文的主要研究内容及结构安排 2
第二章 语音增强的基础知识 3
2.1 人耳的感知特性 3
2.2 噪声的分类和及特性 3
2.2.1 噪声的分类 3
2.2.2 噪声的特性 3
2.3语音特性 4
第三章 基于LMS算法的语音增强技术 6
3.1 LMS算法原理 6
3.2 LMS算法的Matlab仿真结果 8
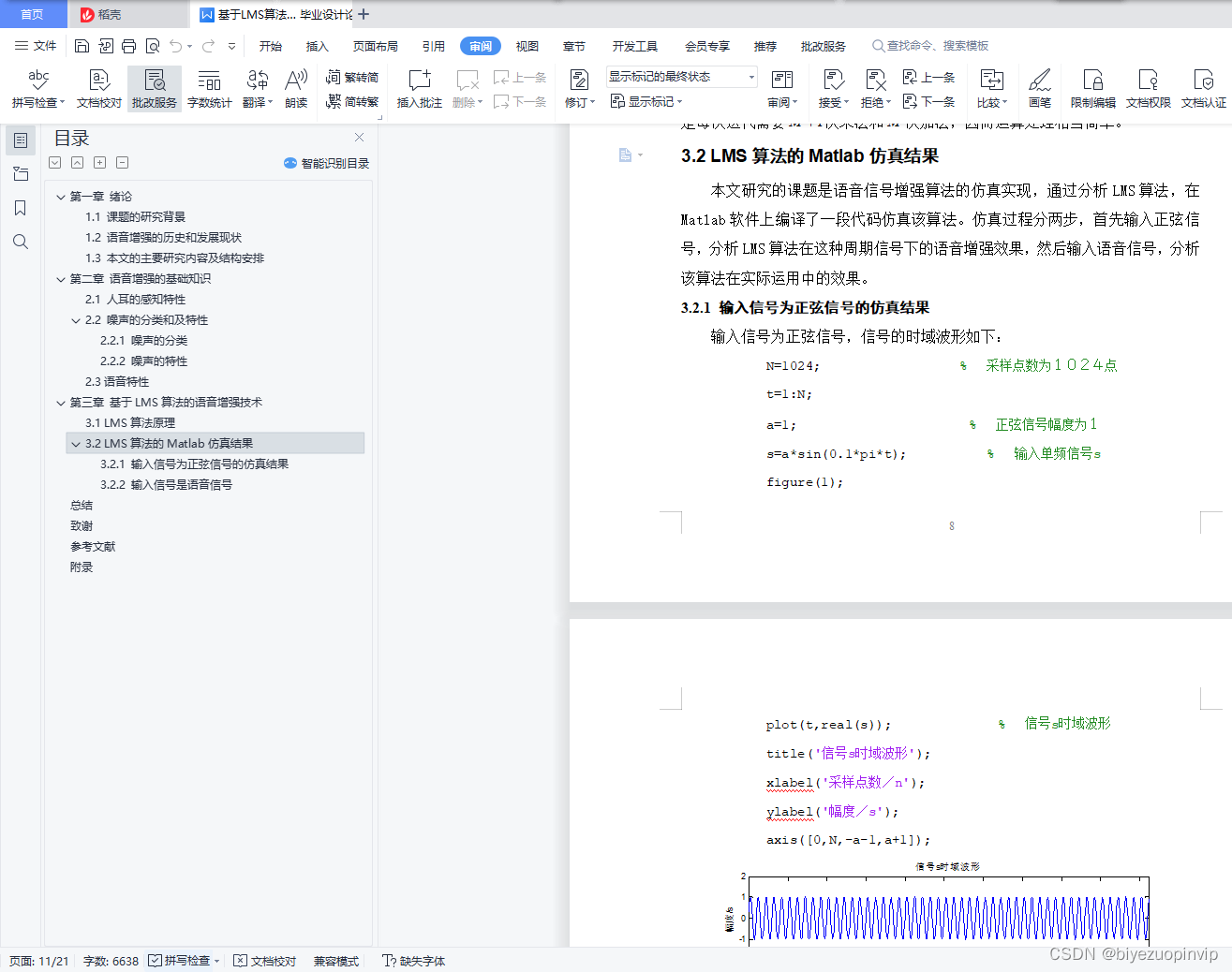
3.2.1 输入信号为正弦信号的仿真结果 8
3.2.2 输入信号是语音信号 10
总结 14
致谢 15
参考文献 16
附录 17
本文是对语音增强算法的仿真,针对以上问题,运用Matlab编写一段处理语音信号的程序,实现对语音信号的简单处理。
论文章节安排如下:
第一章介绍课题研究的背景,讲述语音增强在应用中的重要性,以及语音增强的发展历史和前景。
第二章主要是语音信号增强的理论基础,介绍了人耳的感知特性、噪声的分类和语音特性。
第三章是本课题研究的主题,首先介绍了LMS算法的原理,然后通过在Matlab中编译程序,实现了该算法,通过仿真结果,可以看出LMS算法对语音增强具有显著效果。
第二章 语音增强的基础知识
2.1 人耳的感知特性
语音增强的效果最终取决于人耳的感受效果,因此可以根据人耳的感知特性来减少运算代价。研究表明,人耳对背景噪声有很大的抑制作用,通过了解其机理有助于语音增强技术的发展。目前,已有一些重要的结论可以用于语音增强。
1)人耳有掩蔽特性,也就是强信号对弱信号有掩盖的抑制作用,掩蔽的程度是声音强度与频率的二元函数,对频率的临近分量的掩蔽要比频差大的分量有效的多。
2)人耳对频谱分量强度的感受是频率与能谱的二元函数,响度与频谱幅度的对数成正比。
3)人耳对语音的感知与语音信号频谱分量幅度有关,但对分量相位不敏感。
4)人耳可以从多人讲话的环境中分辨出所需要的声音,这种分辨能力源于人的双耳输入效应,又称为“鸡尾酒效应”。
5)人耳对基频有极好的回复能力。
6)人耳对频率高低的感受于频谱的对数值成近似正比。
2.2 噪声的分类和及特性
2.2.1 噪声的分类
噪声的特性可以说是千变万化,根据与输入语音的关系,噪声可分为加性噪声和非加性噪声两类。对于非加性噪声,也可以通过变换转换为加性噪声。以下只讨论加性噪声,加性噪声大体上可分为宽带噪声、脉冲噪声、周期噪声和同信道语音干扰等。
2.2.2 噪声的特性
(1)宽带噪声
宽带噪声来源很多,热噪声、气流(如风、呼吸)噪声及各种随机噪声源,量化噪声也可视为宽带噪声。由于宽带噪声与语音信号在时域和频域上基本上重叠,因而消除这种噪声比较困难。这种噪声只有在语音间歇期才单独存在。对于平稳的宽带噪声,通常可以认为是高斯白噪声。对于不具有白色频谱的噪声,可以先对其进行预白化处理。对于非平稳的宽带噪声,情况就更为复杂一点。
(2)脉冲噪声
脉冲噪声表现为时域波形中突然出现的窄脉冲,主要来源于爆炸、撞击、放电等。其特征是时间上的宽度很窄。消除脉冲噪声通常可以在时域内进行,其过程如下:根据带噪语音信号幅度的平均值确定阈值,当信号幅度超出这一阈值时判别为脉冲噪声,然后对信号进行适当的衰减,就可以完全消除噪声分量,也可以使用内插方法将脉冲噪声在时域上进行平滑。这是一种直接消除的方法。
(3)周期性噪声
周期性噪声的特点是具有许多离散的线谱,主要来源于发动机等周期性运转的机械,电气干扰,特别是电源交流声也会引起周期性噪声。实际信号受多种因素的影响,线谱分量通常转变为窄带谱结构,而且通常这些窄带谱都是时变的,位置也不固定。必须采用自适应滤波的方法才能有效地区分这些噪声分量。
(4)同声道语音干扰噪声
人耳可以从两人以上谈话的环境中分辨出所需要的声音,人类的这种分离语音的能力成为“鸡尾酒效应”,这种能力来源于人耳的双耳输出效应。干扰语音信号和语音信号同时在一个信道中传输所造成的语音干扰即为同声道语音干扰。区别于用语音和干扰语音的基本方法是利用它们的基音差别。考虑到一般情况下两种语音的基音不同,本文转载自http://www.biyezuopin.vip/onews.asp?id=13769也不成整数倍,这样可以用梳状滤波器提取基音和各次谐波,再恢复出有用语音信号。
(5)传输噪声
传输系统的电路噪声,处理这种噪声可以采用同态处理的方法,把非加性噪声变换为加性噪声来处理。
clc
clear % 清空变量空间
g=100; % 统计仿真次数为g
N1=50001; % 读取的起点值
N2=60000; % 读取的终点值
N=N2-N1+1; % 计算抽样点数N
k=128; % 时域抽头LMS算法滤波器阶数
pp=zeros(g,N-k); % 将每次独立循环的误差结果存于矩阵pp中,以便后
% 面对其平均
u=0.016; % 收敛因子
for q=1:g
t=1:N;
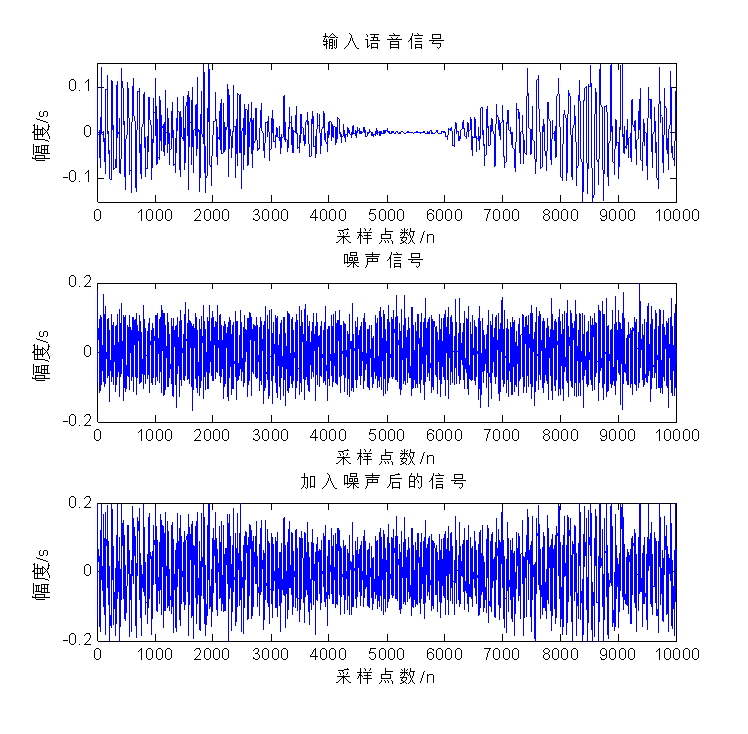
[x,fs,bits]=wavread('D:1.wav',[N1,N2]); % 读取信号
x1=x(1:N,1)'; % 取其第一通道的音频数据
noise=0.05*randn(1,N); % 随机噪声
xn=x1+noise; % 加入噪声
% 设置初值
y=zeros(1,N); % 输出信号y
y(1:k)=xn(1:k); % 将输入信号xn的前k个值作为输出y的前k个值
w=zeros(1,k); % 设置抽头加权初值
e=zeros(1,N); % 误差信号
% 用LMS算法迭代滤波
for i=(k+1):N
XN=xn((i-k+1):(i));
y(i)=w*XN';
e(i)=x1(i)-y(i);
w=w+u*e(i)*XN;
end
pp(q,:)=(e(k+1:N)).^2;
end
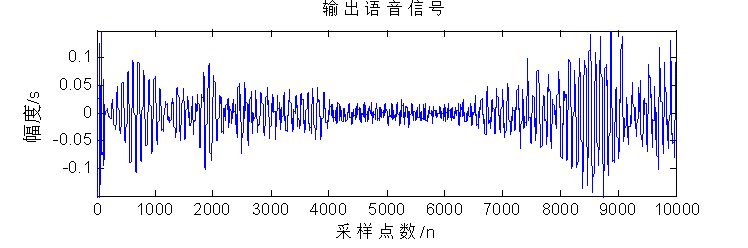
figure(1);
t=1:N;
plot(t,y); % 输出信号
title('输出语音信号');
xlabel('采样点数/n');
ylabel('幅度/s');
axis([0,N,-0.15,0.15]);
for b=1:N-k
bi(b)=sum(pp(:,b))/g; % 求误差的统计平均
end
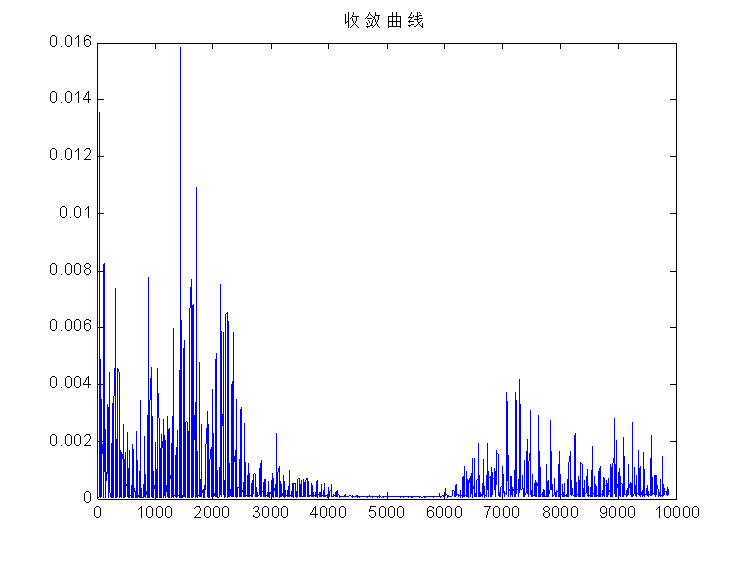
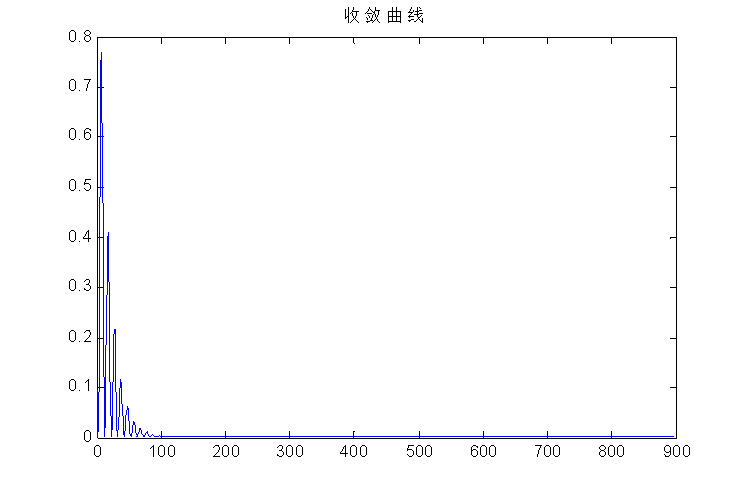
figure(2); % 算法收敛曲线
t=1:N-k;
plot(t,bi);
title('收敛曲线');
hold off % 将每次循环的图形显示结果保存下来
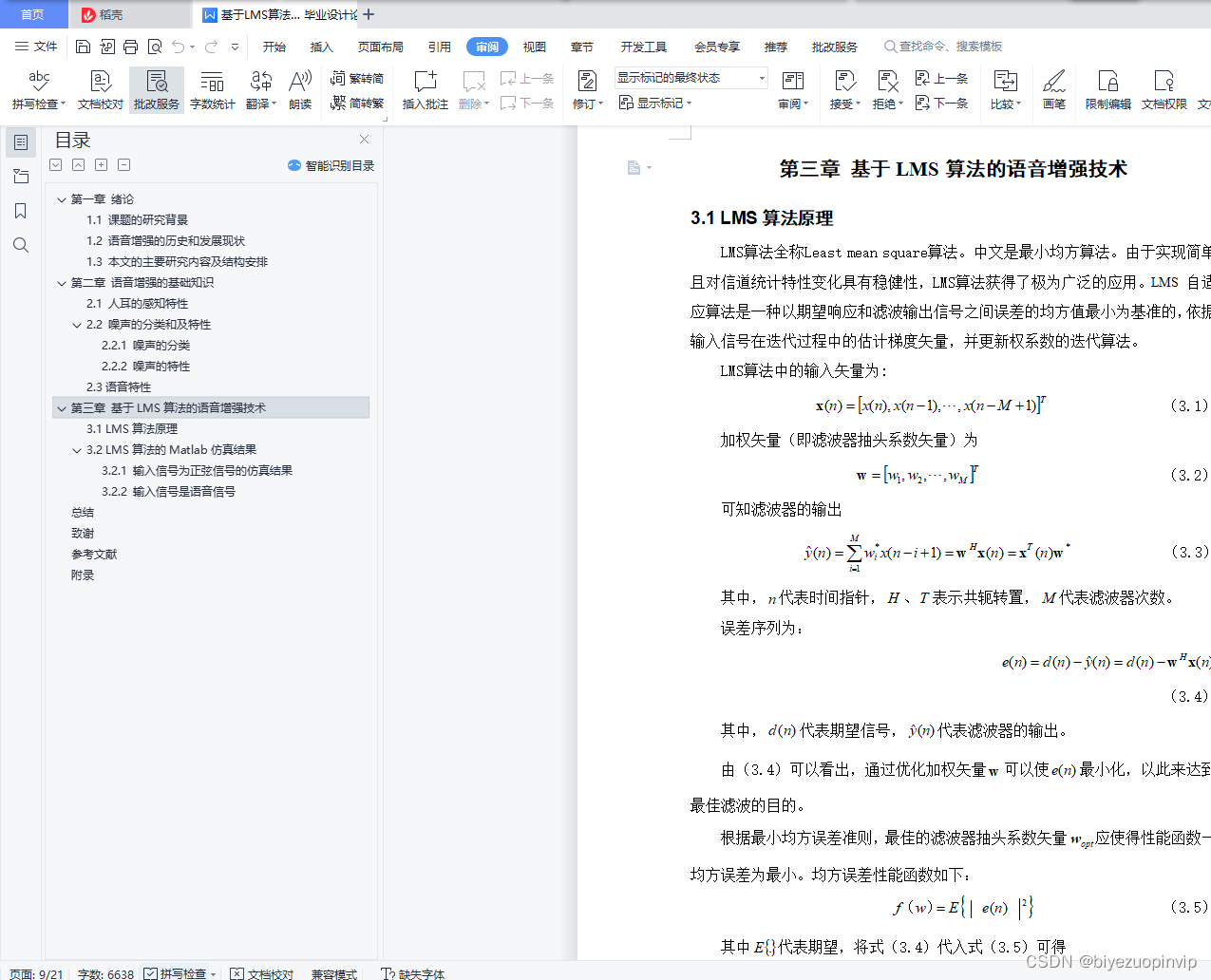
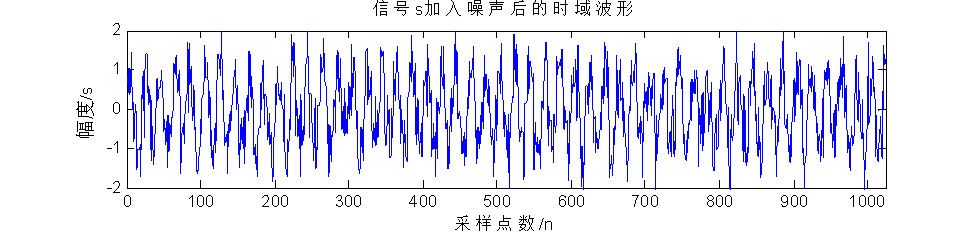
最后
以上就是朴实御姐最近收集整理的关于基于LMS算法的Matlab语音增强算仿真设计的全部内容,更多相关基于LMS算法内容请搜索靠谱客的其他文章。








发表评论 取消回复