缺失值处理
很多机器学习/数据挖掘算法对缺失值是敏感的,因此我们在进行数据分析之前,首先要寻找数据中的缺失值并对它进行适当的处理
缺失值主要分为三种:
1)完全随机缺失(Missing Completely at Random,MCAR)。数据 的缺失与不完全变量以及完全变量都是无关的。
2)随机缺失(Missing at Random,MAR)。数据的缺失仅仅依赖于完全变量。
3)非随机、不可忽略缺失(Not Missing at Random,NMAR,or nonignorable)。不完全变量中数据的缺失依赖于不完全变量本身,这种缺失是不可忽略的。
我们对缺失值处理一般采用平均值填充(Mean/Mode Completer)
将信息表中的属性分为数值属性和非数值属性来分别进行处理。如果空值是数值型的,就根据该属性在其他所有对象的取值的平均值来填充该缺失的属性值;如果空值是非数值型的,就根据统计学中的众数原理,用该属性在其他所有对象的取值次数最多的值(即出现频率最高的值)来补齐该缺失的属性值。
# pandas primarily uses the value np.nan to represent missing data.
def missing():
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
print df
# Reindexing allows you to change/add/delete the index on a specified axis. This returns a copy of the data.
df1 = df.reindex(index=dates[0:4], columns=list(df.columns) + ['E'])
df1.loc[dates[0]:dates[1], 'E'] = 1
print df1
# Filling missing data
df2 = df1.fillna(value=5)
print df2
#To drop any rows that have missing data.
df3 = df1.dropna(how='any')
print df3
#To get the boolean mask where values are nan
print pd.isnull(df1)数据的重塑
很多时候我们并不会使用整个数据集,我们选取我们感兴趣的部分,在进行裁剪后,再进行拼接或整合,得到我们需要的数据集,这就是pandas的merge/concact/join操作
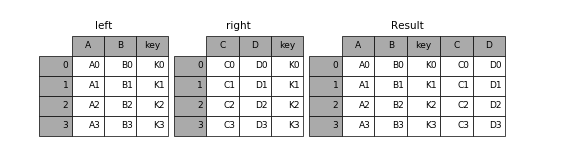
merge:通过键拼接列
pandas提供了一个类似于关系数据库的连接(join)操作的方法,可以根据一个或多个键将不同DataFrame中的行连接起来
merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=('_x', '_y'), copy=True, indicator=False)
该函数的典型应用场景是,针对同一个主键存在两张包含不同字段的表,现在我们想把他们整合到一张表里。在此典型情况下,结果集的行数并没有增加,列数则为两个元数据的列数和减去连接键的数量。
concact
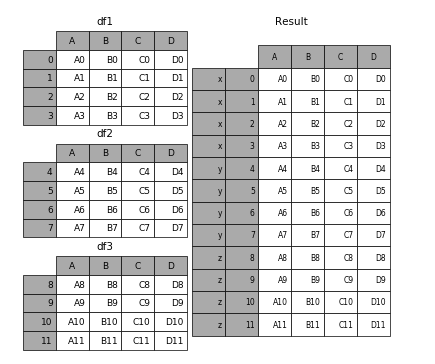
concat 可以沿着一条轴将多个对象堆叠到一起
concat方法相当于数据库中的全连接(UNION ALL),就是单纯地把两个表拼在一起,可以指定按某个轴进行连接,也可以指定连接的方式join(outer,inner 只有这两种)。与数据库不同的时concat不会去重,要达到去重的效果可以使用drop_duplicates方法
concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True):
def join():
#concat():
#Concatenating pandas objects together with concat():
df = pd.DataFrame(np.random.randn(10, 4))
print df
pieces = [df[:3], df[3:7], df[7:]]
pd.concat(pieces)
#concact two dataFrame
#data = pd.concat([data0,data1],ignore_index=True)
#join
left = pd.DataFrame({'key': ['foo', 'foo'], 'lval': [1, 2]})
right = pd.DataFrame({'key': ['foo', 'foo'], 'rval': [4, 5]})
print pd.merge(left, right, on='key')
#Append
df = pd.DataFrame(np.random.randn(8, 4), columns=['A','B','C','D'])
print df
s = df.iloc[3]
print s
df1 =
df.append(s, ignore_index=True)
print df1
#Grouping,group by
#Splitting :the data into groups based on some criteria
#Applying a function to each group independently
#Combining the results into a data structure
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar',
'foo', 'bar', 'foo', 'foo'],
'B' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'C' : np.random.randn(8),
'D' : np.random.randn(8)})
print df
print df.groupby('A').sum()
print df.groupby(['A','B']).sum()
#groupBy 2:
i =0
for data in df.groupby(df[3]):
i=i+1
print i
print data
#Time Series
rng = pd.date_range('1/1/2012', periods=100, freq='S')
print rng
ts = pd.Series(np.random.randint(0, 500, len(rng)), index=rng)
print ts
print ts.resample('5Min').sum()
数据可视化
很多时候,我们希望能把数据直观的表示出来,这就要用到数据可视化
Python有许多可视化工具,这里使用的是matplotlib。
matplotlib的图像都位于Figure对象中,你可以在matplotlib的文档中找到各种图标类型,matplotlib的plot函数接受一组X和Y坐标,还可以接受一个表示颜色和线型的字符串缩写
def plot():
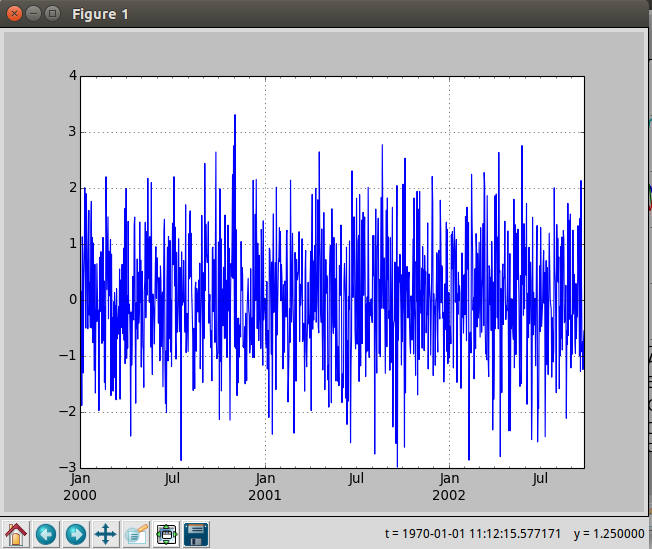
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))
print ts
plt.figure()
ts.plot()
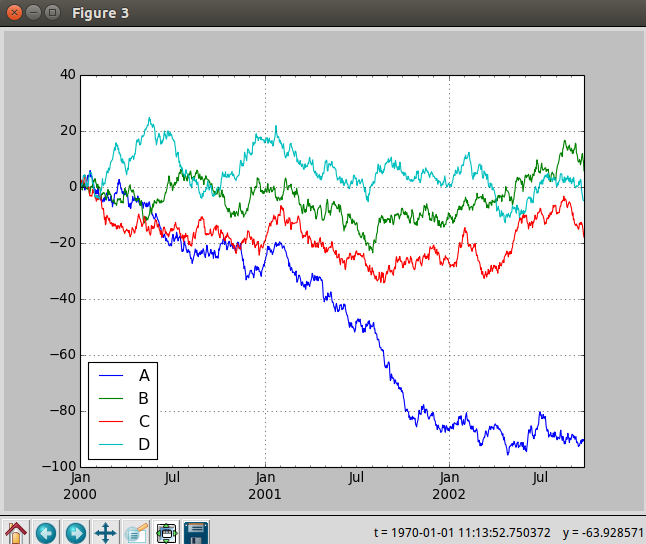
df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index,
columns=['A', 'B', 'C', 'D'])
df = df.cumsum()
plt.figure(); df.plot(); plt.legend(loc='best')
plt.show()
绘图的质量还是很高的,也支持导出为多种格式:
最后
以上就是饱满汉堡最近收集整理的关于pandas数据处理常用函数demo之缺失值/merge/concact/绘图的全部内容,更多相关pandas数据处理常用函数demo之缺失值/merge/concact/绘图内容请搜索靠谱客的其他文章。








发表评论 取消回复