在上1篇里,我们主要从使用层面介绍了Consumer的负载均衡机制。这一篇,我们将深入到源码内部,深入分析负载均衡的过程。
如果把RocketMQ的负载均衡和Kafka的对比一下,我们会发现有一些重要的不同之处。
收集信息 – 存储在Broker还是NameServer上面?
要做负载均衡,首先要解决的一个问题就是收集信息。所谓收集信息,就是我得知道每一个consumer group都有哪些consumer,对应的topic是谁?
这样一份全局的信息,是存放在Broker,还是NameServer上面呢?
Client发送心跳消息
RocketMQ选择了存放在Broker上面。具体做法是:客户端会通过心跳消息,不停的上报自己,RegisterConsumer。
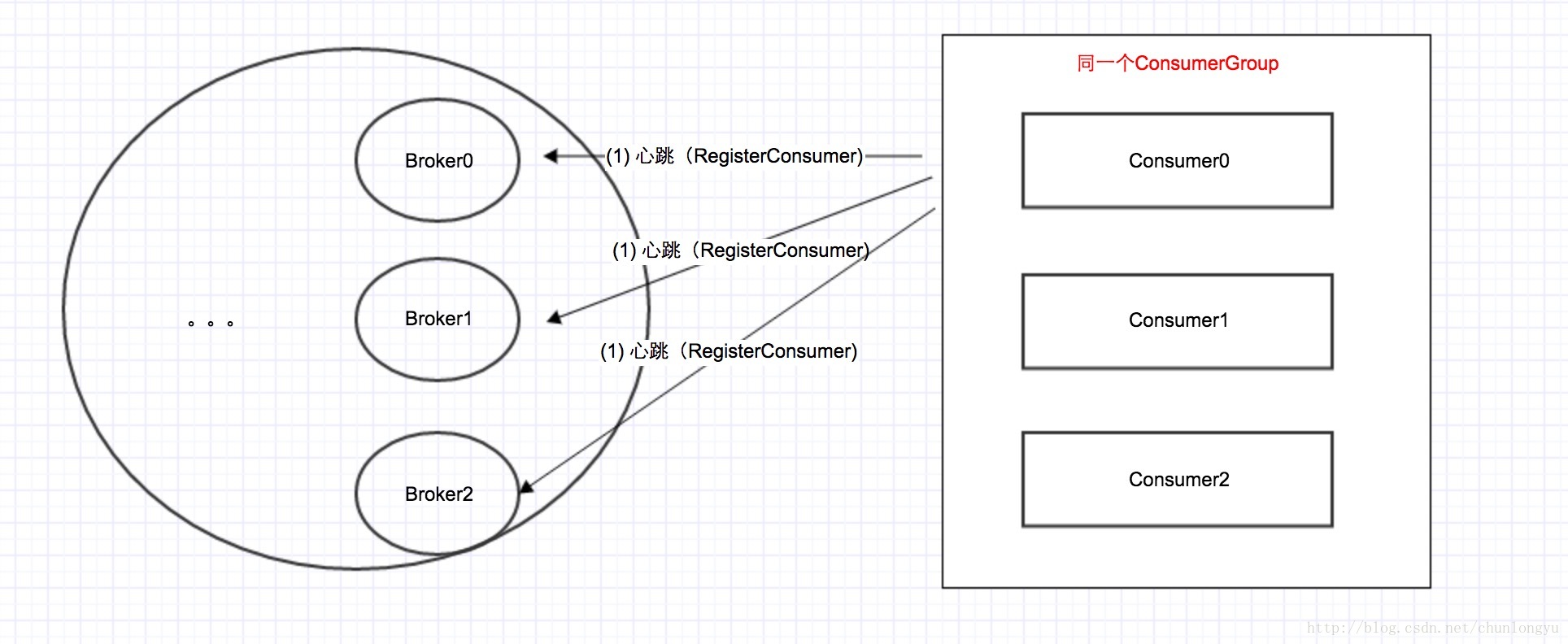
代码如下:
private void startScheduledTask() {
..
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
MQClientInstance.this.cleanOfflineBroker();
MQClientInstance.this.sendHeartbeatToAllBrokerWithLock();
} catch (Exception e) {
log.error("ScheduledTask sendHeartbeatToAllBroker exception", e);
}
}
}, 1000, this.clientConfig.getHeartbeatBrokerInterval(), TimeUnit.MILLISECONDS);
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
private void sendHeartbeatToAllBroker() {
final HeartbeatData heartbeatData = this.prepareHeartbeatData()
...
this.mQClientAPIImpl.sendHearbeat(addr, heartbeatData, 3000)
}
private HeartbeatData prepareHeartbeatData() {
HeartbeatData heartbeatData = new HeartbeatData()
// clientID
heartbeatData.setClientID(this.clientId)
// Consumer
for (Map.Entry<String, MQConsumerInner> entry : this.consumerTable.entrySet()) {
MQConsumerInner impl = entry.getValue()
if (impl != null) {
ConsumerData consumerData = new ConsumerData()
consumerData.setGroupName(impl.groupName())
consumerData.setConsumeType(impl.consumeType())
consumerData.setMessageModel(impl.messageModel())
consumerData.setConsumeFromWhere(impl.consumeFromWhere())
consumerData.getSubscriptionDataSet().addAll(impl.subscriptions())
consumerData.setUnitMode(impl.isUnitMode())
heartbeatData.getConsumerDataSet().add(consumerData)
}
}
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
Broker接收心跳消息,维护全局的consumer信息
Broker收到该心跳消息,把它维护在一个叫做ConsumerManager的对象里面。
public class BrokerController {
...
private final ConsumerManager consumerManager; //关键
public class ClientManageProcessor implements NettyRequestProcessor {
@Override
public RemotingCommand processRequest(ChannelHandlerContext ctx, RemotingCommand request)
throws RemotingCommandException {
switch (request.getCode()) {
case RequestCode.HEART_BEAT:
return this.heartBeat(ctx, request);
}
public RemotingCommand heartBeat(ChannelHandlerContext ctx, RemotingCommand request) {
boolean changed = this.brokerController.getConsumerManager().registerConsumer(
data.getGroupName(),
clientChannelInfo,
data.getConsumeType(),
data.getMessageModel(),
data.getConsumeFromWhere(),
data.getSubscriptionDataSet(),
isNotifyConsumerIdsChangedEnable
);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
负载均衡是客户端做还是服务器做?
现在Broker有了每个topic的所有consumer group的所有consumers,那负载均衡谁来做呢?
2种方案:方案1,让broker来分配,分配好,发给每个consumer;方案2,consumer从broker那获取这份全局信息,自己做。
同Kafka一样,RocketMQ也是选择的第2种方案,就是客户端自己做!
为什么让客户端做,而不是服务器做,在Kafka的那篇文章中,已经有探讨,此处不再详述。
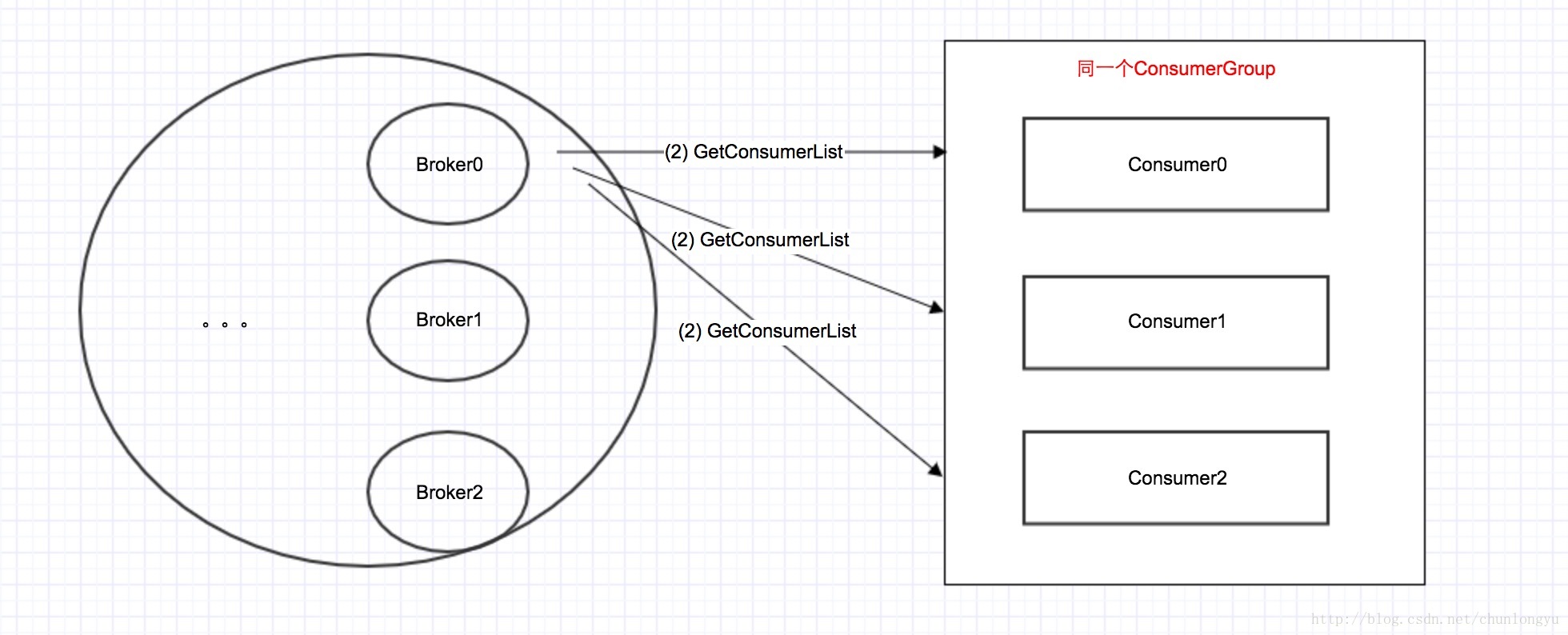
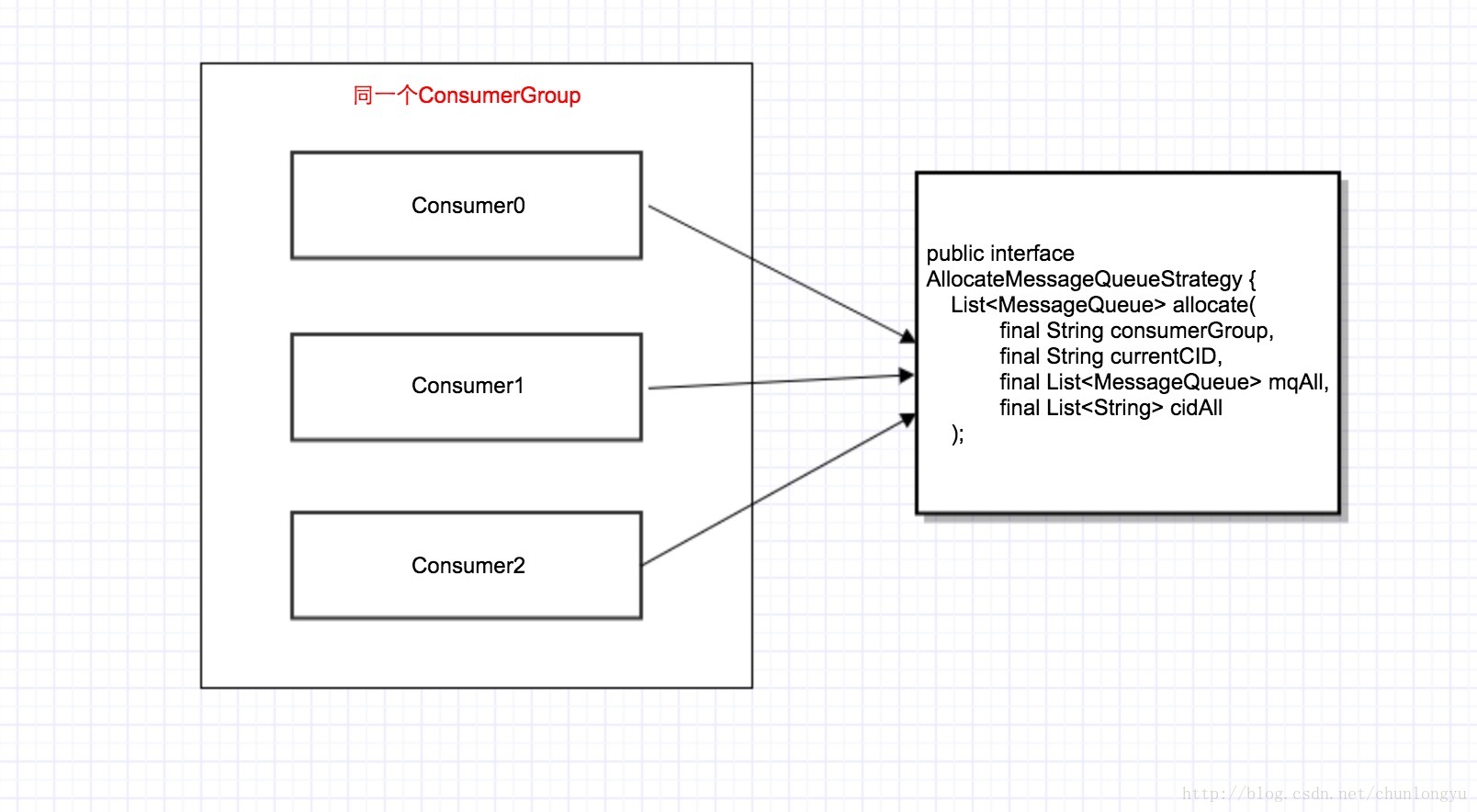
那么客户端具体如何做的呢?且看代码:
public void doRebalance(final boolean isOrder) {
Map<String, SubscriptionData> subTable = this.getSubscriptionInner();
if (subTable != null) {
for (final Map.Entry<String, SubscriptionData> entry : subTable.entrySet()) {
final String topic = entry.getKey();
try {
this.rebalanceByTopic(topic, isOrder);
} catch (Throwable e) {
if (!topic.startsWith(MixAll.RETRY_GROUP_TOPIC_PREFIX)) {
log.warn("rebalanceByTopic Exception", e);
}
}
}
private void rebalanceByTopic(final String topic, final boolean isOrder) {
switch (messageModel) {
case BROADCASTING: {
Set<MessageQueue> mqSet = this.topicSubscribeInfoTable.get(topic);
if (mqSet != null) {
boolean changed = this.updateProcessQueueTableInRebalance(topic, mqSet, isOrder);
if (changed) {
this.messageQueueChanged(topic, mqSet, mqSet);
log.info("messageQueueChanged {} {} {} {}",
consumerGroup,
topic,
mqSet,
mqSet);
}
} else {
log.warn("doRebalance, {}, but the topic[{}] not exist.", consumerGroup, topic);
}
break;
}
case CLUSTERING: {
Set<MessageQueue> mqSet = this.topicSubscribeInfoTable.get(topic);
List<String> cidAll = this.mQClientFactory.findConsumerIdList(topic, consumerGroup);
if (null == mqSet) {
if (!topic.startsWith(MixAll.RETRY_GROUP_TOPIC_PREFIX)) {
log.warn("doRebalance, {}, but the topic[{}] not exist.", consumerGroup, topic);
}
}
if (null == cidAll) {
log.warn("doRebalance, {} {}, get consumer id list failed", consumerGroup, topic);
}
if (mqSet != null && cidAll != null) {
List<MessageQueue> mqAll = new ArrayList<MessageQueue>();
mqAll.addAll(mqSet);
Collections.sort(mqAll);
Collections.sort(cidAll);
AllocateMessageQueueStrategy strategy = this.allocateMessageQueueStrategy;
List<MessageQueue> allocateResult = null;
try {
allocateResult = strategy.allocate(
this.consumerGroup,
this.mQClientFactory.getClientId(),
mqAll,
cidAll);
} catch (Throwable e) {
log.error("AllocateMessageQueueStrategy.allocate Exception. allocateMessageQueueStrategyName={}", strategy.getName(),
e);
return;
}
Set<MessageQueue> allocateResultSet = new HashSet<MessageQueue>();
if (allocateResult != null) {
allocateResultSet.addAll(allocateResult);
}
boolean changed = this.updateProcessQueueTableInRebalance(topic, allocateResultSet, isOrder);
if (changed) {
log.info(
"rebalanced result changed. allocateMessageQueueStrategyName={}, group={}, topic={}, clientId={}, mqAllSize={}, cidAllSize={}, rebalanceResultSize={}, rebalanceResultSet={}",
strategy.getName(), consumerGroup, topic, this.mQClientFactory.getClientId(), mqSet.size(), cidAll.size(),
allocateResultSet.size(), allocateResultSet);
this.messageQueueChanged(topic, mqSet, allocateResultSet);
}
}
break;
}
default:
break;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
可以看到,分配过程,就是关键的2步:
第1步: 每个consumer都会向broker获取一份全局信息,也就是该topic的consumer group中所有consumer的列表
第2步:把3个关键参数,自己的clientId, 所有consumer的clientIdList,该topic的MessageQueueList,传给分配器。
分配器计算出该consumer应该分到的MessageQueueList。客户端定义了几种不同的分配策略,如下:
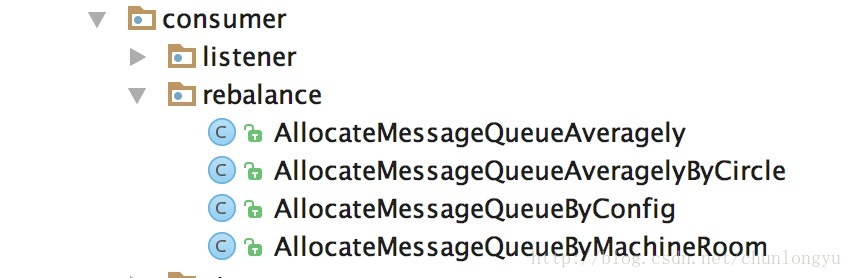
算法都比较简单,此处就不再详述。
clientId是如何生成的?
顺便提一下,这里分配算法要用到clientId,那这个clientId是根据什么规则生成的呢?
如下所示,也就是本机ip @ instanceName。instanceName缺省值为值”DEFAULT”,但在运行时,被设置为pid。unitName缺省为空。
public String buildMQClientId() {
StringBuilder sb = new StringBuilder();
sb.append(this.getClientIP());
sb.append("@");
sb.append(this.getInstanceName());
if (!UtilAll.isBlank(this.unitName)) {
sb.append("@");
sb.append(this.unitName);
}
return sb.toString();
}
public void changeInstanceNameToPID() {
if (this.instanceName.equals("DEFAULT")) {
this.instanceName = String.valueOf(UtilAll.getPid());
}
}
public static int getPid() {
RuntimeMXBean runtime = ManagementFactory.getRuntimeMXBean();
String name = runtime.getName();
try {
return Integer.parseInt(name.substring(0, name.indexOf('@')));
} catch (Exception e) {
return -1;
}
}
与Kafka Consumer负载均衡的不同点
分析完RocketMQ的负载均衡,我们发现它比Kafka的负载均衡要简单,Kafka在这1块搞了蛮复杂的通信协议,可以参见上面那篇文章。
具体来说,有2个地方,要简化很多:
(1) Kafka首先为每个Consumer Group选出了一个Coordinator,所有的Consumer要先找到这个Coordinator,然后和其通信,开始负载均衡。
RocketMQ直接省去了这个选Coordinator的过程,直接让consumer和所有broker广播通信。
(2) 虽然Kafka也是让客户端做负载均衡,但是做法和RocketMQ并不一样。Kafka是让Coordinator从所有Consumer中,选出了一个Master Consumer,让它负载分配。它分好之后,把分配结果传给其他的Consumer。
RocketMQ没搞这么复杂,而是所有Consumer都获取到这份全局的consumer列表,每个人自己分自己那一份!!少了上面的通信过程。
最后
以上就是高高口红最近收集整理的关于分布式消息队列RocketMQ源码分析之4 -- Consumer负载均衡与Kafka的Consumer负载均衡之不同点 收集信息 – 存储在Broker还是NameServer上面? 负载均衡是客户端做还是服务器做? 与Kafka Consumer负载均衡的不同点的全部内容,更多相关分布式消息队列RocketMQ源码分析之4内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复