Github地址:
https://github.com/RicardoDZX/wcPro
PSP:
PSP2.1表格
| PSP2.1 | PSP阶段 | 预估耗时 (分钟) | 实际耗时 (分钟) |
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 240 | 260 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 30 |
| · Design Spec | · 生成设计文档 | 0 | 0 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 0 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 15 |
| · Design | · 具体设计 | 10 | 10 |
| · Coding | · 具体编码 | 65 | 75 |
| · Code Review | · 代码复审 | 40 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 80 | 90 |
| Reporting | 报告 | 120 | 120 |
| · Test Report | · 测试报告 | 80 | 80 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 380 | 400 |
解题思路:
负责模块:
我负责的是排序部分的实现。
以及小组成员的代码整合(main部分)。
exe的生成与测试。
github上传。
已掌握可重用知识:
由于在上一个试验任务中,已经重新熟悉了久违的java,所以这个实验相对而言,就不会那么令人恐惧....
总结一下可重用的知识:
jar打包技术(虽然我这次打包的时候,还是出现了compiler的版本问题。但有了上次的经验,很快就解决了)
jar转exe技术
git/github的使用(add,commit,push,tag)
java读取文件流,写入文件的知识
排序算法/自带排序函数
时间复杂度的分析
需要学习的知识:
JUnit的使用
静态代码检查工具的使用
测试用例的设计
同行评审
设定接口:
首先,因为wcPro的功能和wordcount的功能还是有一定的相似度的。
比如(读取文件,写入文件),而且去除了一定的格式要求,输出要求,我认为是较wordcount程序在这部分做了一定的简化的。
但是也有一些新的任务,比如统计词频,比如进行排序。
但也都不算太难,我认为。
我们小组经过讨论,基于划分模块,减少耦合的想法,为了让每个人都能得到锻炼,主要划分了以下的任务:
输入部分:对命令行输入进行处理,获取文件路径,名称等等,有一定的错误判断机制。
接口:string类型的处理过的输入信息(文件名)。
统计词频部分:接受处理过的输入信息,打开并读取文件,统计词频。
接口:map<String,int>类型的词频信息(未排序)。
排序部分:这是我负责的任务。主要是接受词频信息,进行排序,保留频率最高的一百个单词信息(如果单词个数超出100)。
同一频率的单词按照字母表顺序排列。
接口:List<map.entry<String,int>>类型的排序后的,经过处理的单词信息。
输出部分:负责输出到result.txt中。
注:以上的接口信息为所在行上下两个部分之间的接口。
具体实现:
在这里先说一下我的最初一份代码:(未经过评审和改进)
由于考虑到老师的接下来的性能方面的要求,而且排序部分本来就是很耗时的,所以最初设计的时候我就思考如何能够尽量提高性能。
输入量有可能很大,首先按照频率进行排序,之后相同频率按照字母表顺序排序。
所以我的想法是:
1. 选用一个时间复杂度适当的排序算法,进行排序。
2. 截取前一百个元素(如果超过100),对这100个元素进行相同频率按字母表排序。
(这样就不会对所有的元素中相同频率的元素进行排序)
我的想法是先使用JAVA自带的包中的排序函数,在接下来比较性能的时候,自己写另外的排序算法,看一下哪个效率更高。


1 public List<Map.Entry<String,Integer>> mySort(Map<String,Integer> map){ 2 List<Map.Entry<String,Integer>> res=new ArrayList<Map.Entry<String,Integer>>(); 3 //如果map中存在单词的频率信息数据。 4 //进行排序。 5 //否则,返回空list。 6 if(map.size()!=0) { 7 mList = new ArrayList<Map.Entry<String, Integer>>(map.entrySet()); 8 Collections.sort(mList, new Comparator<Map.Entry<String, Integer>>() { 9 public int compare(Map.Entry<String, Integer> o1, 10 Map.Entry<String, Integer> o2) { 11 return o2.getValue()-o1.getValue(); 12 } 13 }); 14 15 16 int size_t; 17 if (map.size() <= 100) { 18 size_t = map.size(); 19 } else { 20 size_t = 100; 21 } 22 for (int i = 0; i < size_t; i++) { 23 res.add(mList.get(i)); 24 }
这是比较单词频率的一部分。
因为最开始对于compare比较器的原理不是很熟悉,
(后来搭档互评的时候告诉我可以在里面嵌套相同频率不同单词的字符串比较,但我考虑如果嵌套比较的话,那么所有的相同频率元素都会被比较,会更耗时一点)
这里暂且先不细说。
while (count < size_r) { //如果value值相同 if (value_diff == res.get(count).getValue()) { //存入temp中 temp.add(res.get(count)); } else { //如果只有一个元素(没有重复的情况),就不需要排序了,说不定还会出bug if (temp.size() != 1) { //对当前的temp进行排序(按key值) Collections.sort(temp, new Comparator<Map.Entry<String, Integer>>() { public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { return o1.getKey().compareTo(o2.getKey()); } }); //替换temp中的元素到res中 //注:之所以这里i的取值和函数最后的i的取值不同(相差1) //是因为,这里当前的count对应的元素是不符合要求的,不在当前的temp里的。 //而后面的count是符合要求的,已经添加到temp之中的。 for (int i = count - temp.size(); i < count; i++) { //这里temp.get(i)应该是从0下标开始。 res.set(i, temp.get(i + temp.size() - count)); } } //清空temp,value_diff改成下一个值 temp.clear(); value_diff = res.get(count).getValue(); //这里要添加第一个元素,不然下一个循环就是count+1,当前的count没有处理。 temp.add(res.get(count)); } //到现在为止,还没有处理,count=size-1的情况(最后几个value相等,但是还没处理就跳出了while循环) //前面无论是,if还是else的路径,都会add当前的count对应的元素。 if (count == size_r - 1) { if (temp.size() != 1) { Collections.sort(temp, new Comparator<Map.Entry<String, Integer>>() { public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { return o1.getKey().compareTo(o2.getKey()); } }); //替换temp中的元素到res中 //这里i的范围略有不同,因为当前count的元素已经添加 for (int i = count - temp.size() + 1; i <= count; i++) { res.set(i, temp.get(i + temp.size() - count - 1)); } } } count++; }
这里是相同词频的key的比较。
我的想法是,对于记录最多100个元素的list,因为前一步已经按照了频率排序,只不过相同频率的单词没有按字母表排序而已。
这一次就从头到尾只需要遍历一次,遍历过程中随时记录相同频率的元素。
当遇到不相同频率的元素,则清空记录,重新开始。
每次对所记录的元素进行按字母表排序。
这样其实是O(N)的时间复杂度。
测试用例:
在这里,我使用JUnit框架进行单元测试。
遇到的问题:
在这个步骤中,遇到的问题主要有两个吧。
首先,不知道我的IDE发了什么疯。我在使用Intellij idea附带的功能下载JUnit插件的时候一直报错。
所以只能手动配置...
还有就是,java中的map传参很是费劲。
我在使用JUnit中,test函数中设定正确结果就有点费劲。
不知道是不是还没有学习到JUnit更深层的用法?
我的排序函数输出是一个List<map.entry<String,Integer>>,但是,我不能直接向一个List中传map.entry类型的参数(没法声明,也可能是我没找对办法)
map.entry只能是map转换。而如果我声明了map,map内部其实是用一定规则的hash序的,转换成map.entry之后,感觉并不能得出正确的我所需要的排序。
不知道....我的想法是不是有问题...
但我一直没能找到方法。
所以,最后我只好用一种比较取巧的方法。
我用List<Map>来存储结果,多写了一个函数,将List<map.entry>转换成List<map>,这样的话,才找到能够获得预计结果的方法。
个人觉得这个方法实在是挺蠢.....
但理论上应该可以正确完成测试的目标。
测试用例:
在这里我发现一个很重要的问题(我认为)!
就是,关于含有“——”的单词和正常的单词,同频率情况下的排序。
比如:
“aaa” 100
“a-a” 100
这两者应该按字母a-z哪个在前面呢?
老师在说明里好像没有给出具体说明......
我测试了一下,按照我写的代码判断,会先输出a-a,再输出aaa,也就是认为“——”的优先级比“a”字母还要高。(应该是ascii码的缘故)
![]()
![]()
可见,确实是这样,“---”的ascii码值小于字母,所以会排在前面。
在这里,我就按照这个默认来了。
测试用例如下:
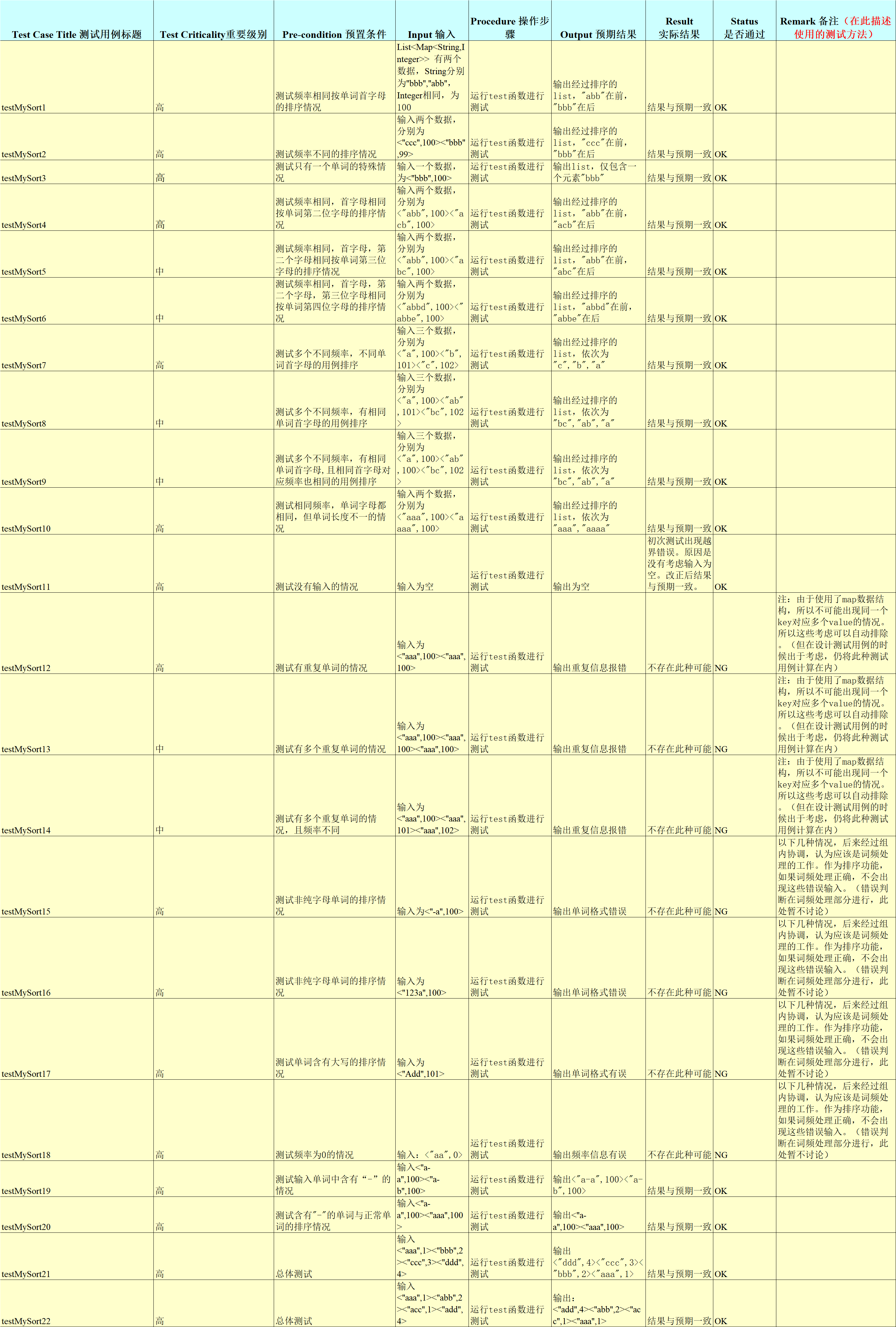
测试用例的设计:
因为我所负责的模块主要函数只有sort一个。
基于覆盖判断和路径的要求:
注:从所附的代码可以看出,进行的判断主要有:
1. map.size是否等于0(这个在上述的测试用例中已经说明,留给统计词频进行处理,暂且认为不存在为0的情况)
2. map.size是否小于100(输入元素个数)
3. res.size是否小于100(进行按词频排序后的元素个数)
4. 记录词频相同的单词的list,size是否等于1(没有相同词频的多余单词)
我不太清楚,当测试的元素个数很多的时候,如何通过JUnit进行测试。
输入样本,和期望结果的时候,是要一个一个输进去么?
或者,我们可以从外部传参。直接将正确结果赋给变量。
但问题是,目前我们就是要测这个排序的正确性。
我如何得到正确的,大规模数量的排序结果呢?
基于这个原因,我没有覆盖所有的路径。
(size>100的情况)
发现的问题:
我在设计测试用例和测试的过程中,发现了一个问题。
就是,我之前的思想是,仅保留前100个最高词频的单词,进行同词频按照字母表排序。
但是,有一种特殊情况!!!
就是,假如,第95-105个单词,词频是相同的(假设都是50)
但此时,还没有经过按首字母的排序。
假如:
aaa,zzz,bbb,yyy,ccc,sss,ddd,uuu,iii,ooo,ppp这十个单词。
按照我的方法:
会截取:aaa,zzz,bbb,yyy,ccc,和前面的95个单词,进行同词频按首字母排序。
但是,正确的结果应该是:
截取:aaa,bbb,ccc,ddd,iii,和前面的95个单词。
不知道老师和助教理解没理解。
我的解决方法:
我的想法是,会保留100+n个单词。(n是超出100,但与之前的单词同词频的单词数量)
然后按我的方法再排序,之后再截取100个。
这一点改进,具体在扩展功能进行描述。这里暂且不提。
测试用例运行:

总的来说,性能和质量还是可以的(除了最开始输入为空的情况没有加以判断。改正后就没问题了。)
关于性能,我会在后面专门进行测试。这里由于多了一个转换步骤,我认为性能可能有所损失。
git-tag推送:
关于tag推送,我是直接在github中进行的。
具体方法如下。
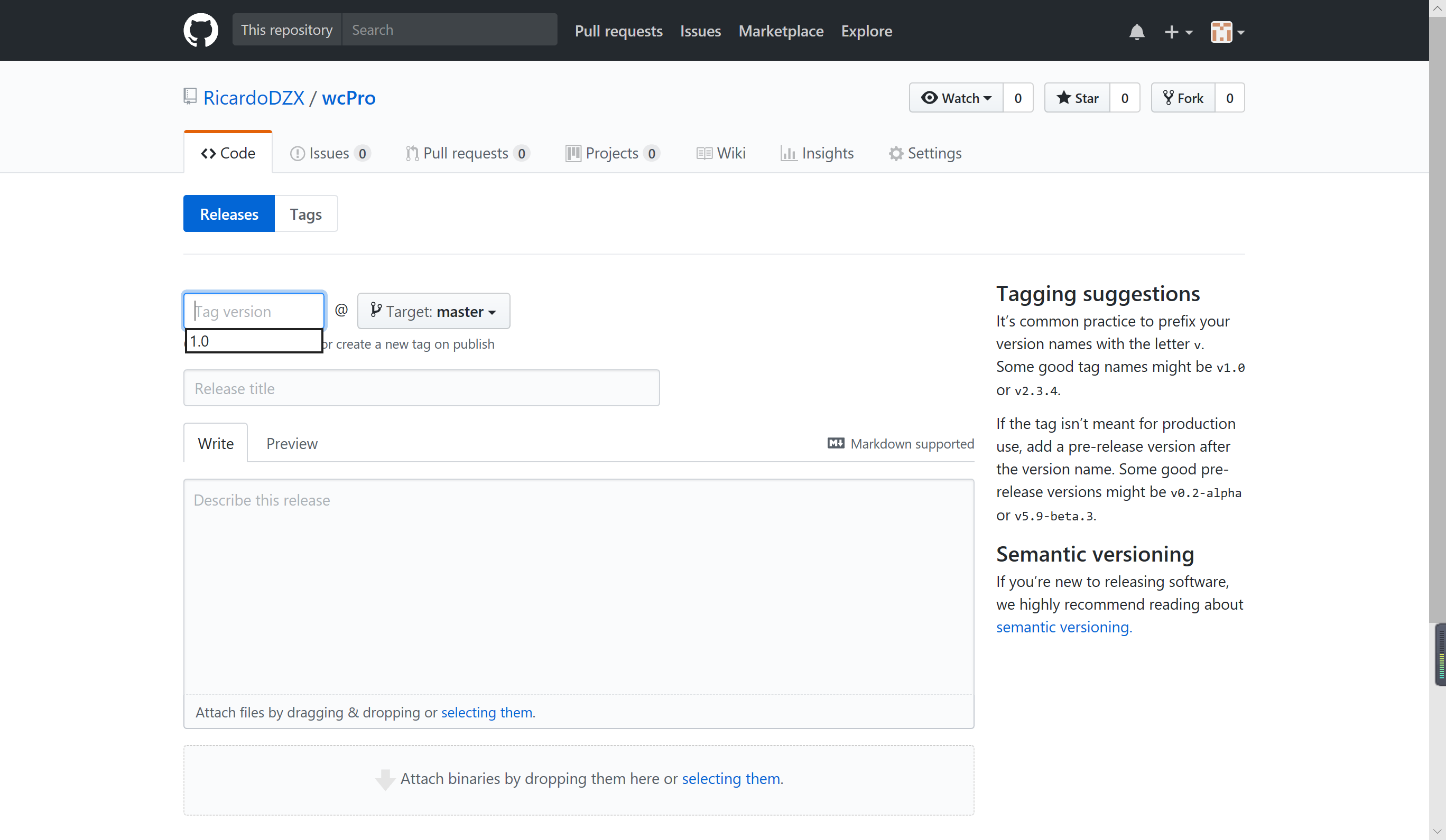
小组贡献:
经过讨论,小组贡献分0.28
大致是因为虽然排序部分代码量不算特别多,但我在其他方面,包括整合,统筹等等吧,多费了一些心思,所以贡献度还可以。
组内情况:
16984: 0.28
17008: 0.26
17003: 0.24
17007: 0.22
扩展任务:
选择代码规范:
由于我们使用JAVA进行开发,我选择的是阿里巴巴的JAVA编程规范。
选择静态测试工具:
我选择的是阿里巴巴的测试IDE插件。
通过Intellij idea的内置插件搜索和下载。
所以在这里就没有给出下载地址。
同行评审:
首先,我们组先进行的同行评审。
我考虑到功能的相似性和承接性,觉得让董德民和我互相评审(分别负责词频统计,排序),唐桥保和罗迪互相评审(分别负责输入,输出模块)比较好。
组员们也同意了这一分配。
我负责董德民同学的代码评审:(学号:17008)
在同行评审的过程中。董德民同学发现的我的代码的问题如下:

还有就是提出我的排序逻辑(对于相同词频的单词)太麻烦了。可以简单实现。
我对董德民同学的评测结果:
董德民同学的代码基本上没有代码规范问题。(包括我后来偷偷用静态扫描工具测试了一下,也只有“没有注明作者”的一个小问题)
对于董德民同学的代码实现,我提出了如下困惑。
1.关于词频统计的边界条件。为什么不放在循环内部,而是在循环外部单独再进行一次判定。
回答:最开始确实是放在内部,不过在判断的时候会报错越界。
2. aaa123-321aaa类似的单词是如何进行处理的。
董德民同学的回复:

静态扫描:
初次扫描:
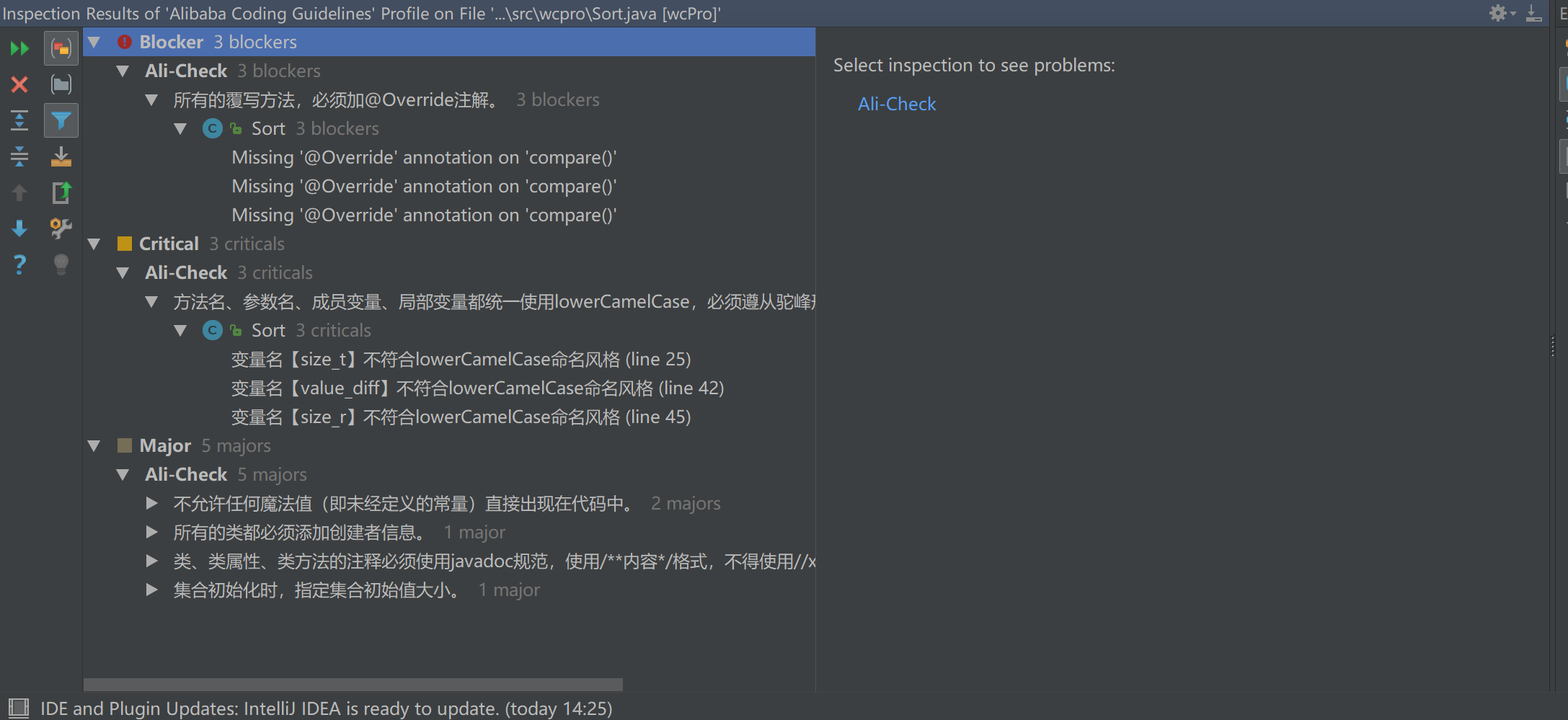
改正后:
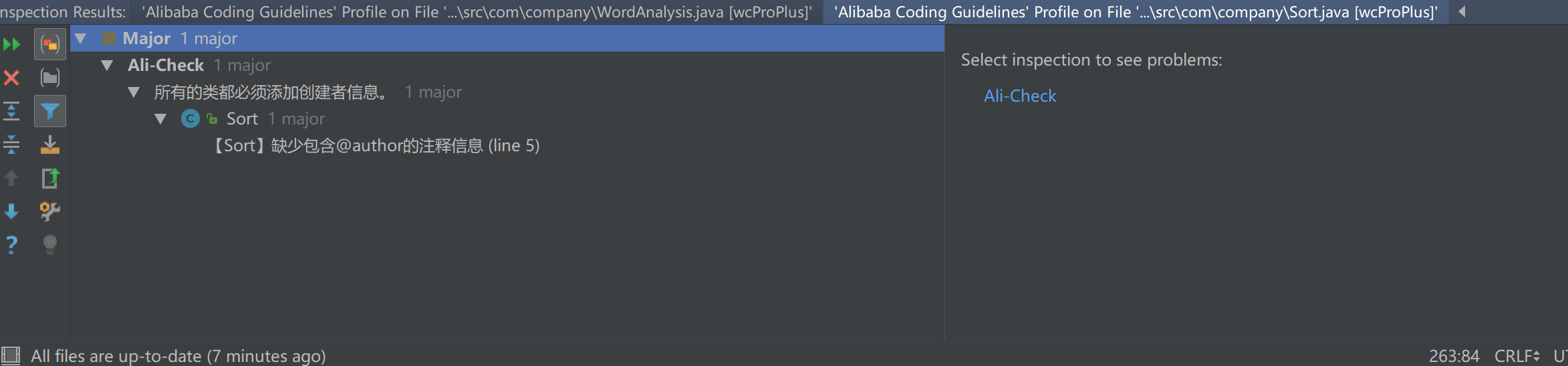
代码评审总结与改进:
对于我的代码
1.修改了上文提到的存在的问题(bug)(可能误删一些应该保留的边界单词)
2. 重写了判断逻辑。比之前大大简化。
3. 进行代码规范。
对于小组的代码:
由于我还负责最后的整合,exe的生成和代码推送。
所以...对于其他人的代码也发现了一些问题。
具体如下:
唐桥保(输入部分):
主要是一个bug。在运行exe文件的时候,使用wcPro.exe filename的形式。
之前写代码的时候,没有注意到arg[0]就是filename。认为arg[0]是“wcPro.exe”
总体来讲,经过上课的讲解和评测的任务,组员的代码大部分都比较规范。
性能测试与优化:
我使用的方法是:
System.currentTimeMillis()
我本人主要针对排序模块进行优化。
测试集:
设计思路:
对于这个程序而言,测试集应该主要是单词的形式(英文),同时,为了测试排序性能,要求单词重复度不能太高(不然单词数量会很少,排序就没什么必要了)
为了测试大数据下的性能,应设计一个能够提供较大压力的测试集。
具体使用的测试集合是我找的一些程序源码。
(英文,且具备一定的词频特性,单词数目足够)
1. 470KB的txt文档:
![]()
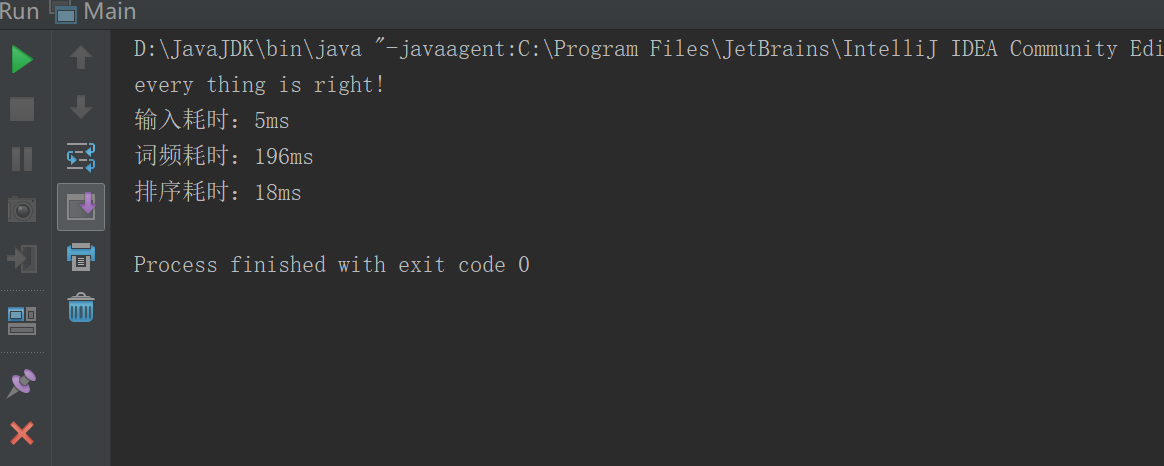
经过多次测量取平均值:
排序模块,约耗时:13ms
2.对于1M的文件:
![]()
排序时间,经多次测量取平均值。
约26ms(波动较大)
组内评审:
针对可能影响程序性能(制约因素),我们小组进行了组内评审,讨论。
主持:
杜卓轩(16984)
评审:
杜卓轩(16984)
唐桥保(17003)
罗迪(17007)
董德民(17008)
评审主题:
1.影响程序性能的主要因素。
2.有何建议。
我的观点:
我认为主要性能制约因素是:词频统计模块。
和读取文件,存入map的模块。
因为这涉及到文件的输入流,要逐行读取,分别处理。
这就耗费了很大时间,尤其是文件规模很大的情况。
为了证明我的观点,我进行了实际测试:

其他成员认同本人观点。
并提出:
输出部分耗时也很严重,是制约程序性能的另一大因素。
总结:
希望对词频统计和输出进行优化。若难度较大,优化效果不高,则着手排序功能进行优化。
性能提升:
我对排序所采用的方法就是我在前文中提到的。
在按照词频排序后,不对所有的相同词频的单词按字母表排序。
而是先进行选取,再对选取的单词按字母表排序。
这样能够获得一定的性能提升。
如图:
(排序1:原来的排序功能)
(排序2:改进后的排序功能)
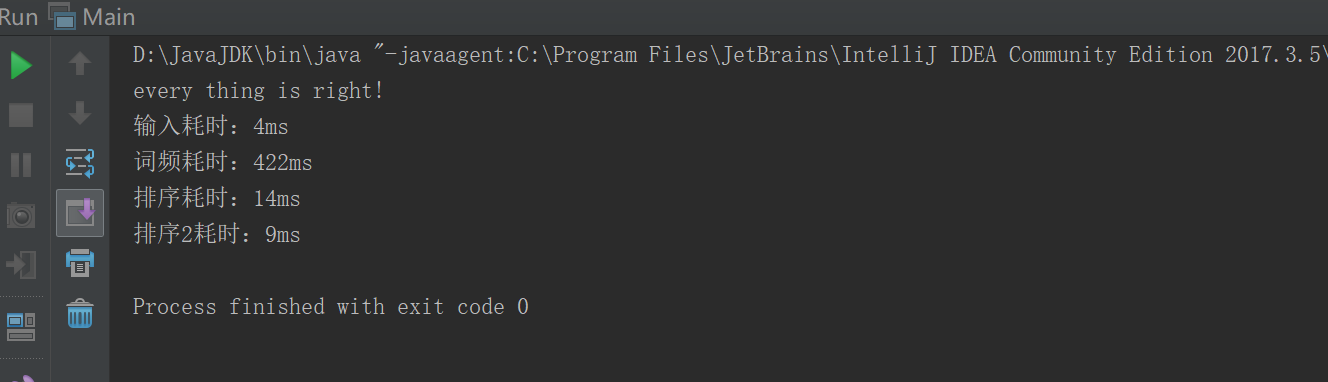
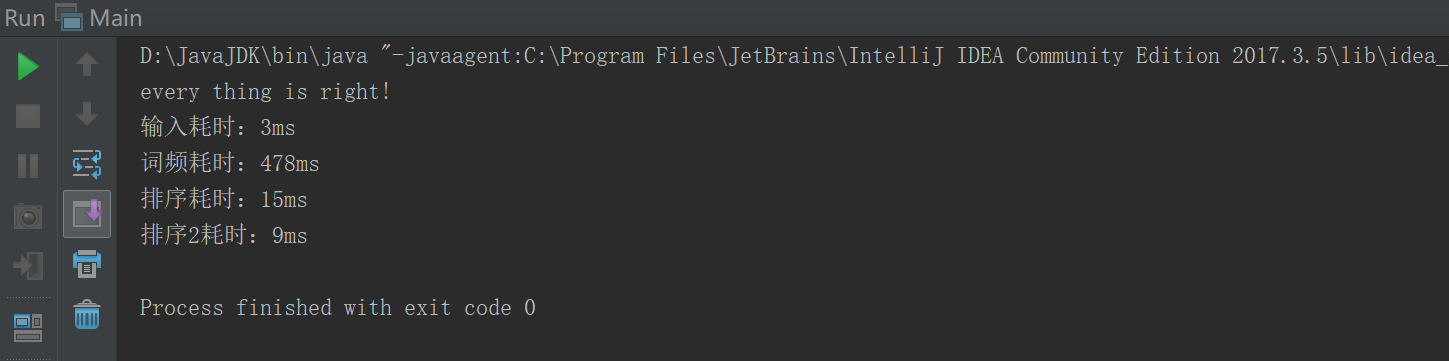
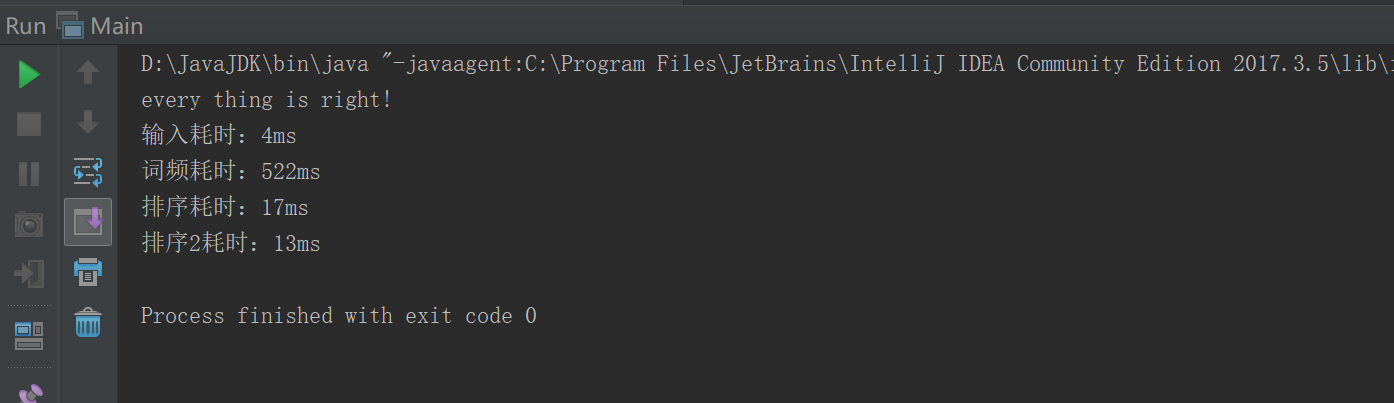
另外,我对于Java自带的排序函数,和快速排序的算法进行了比较。想从中择优选择。
具体是在比较单词频率的部分分别使用了快排和java的比较器。
结果:
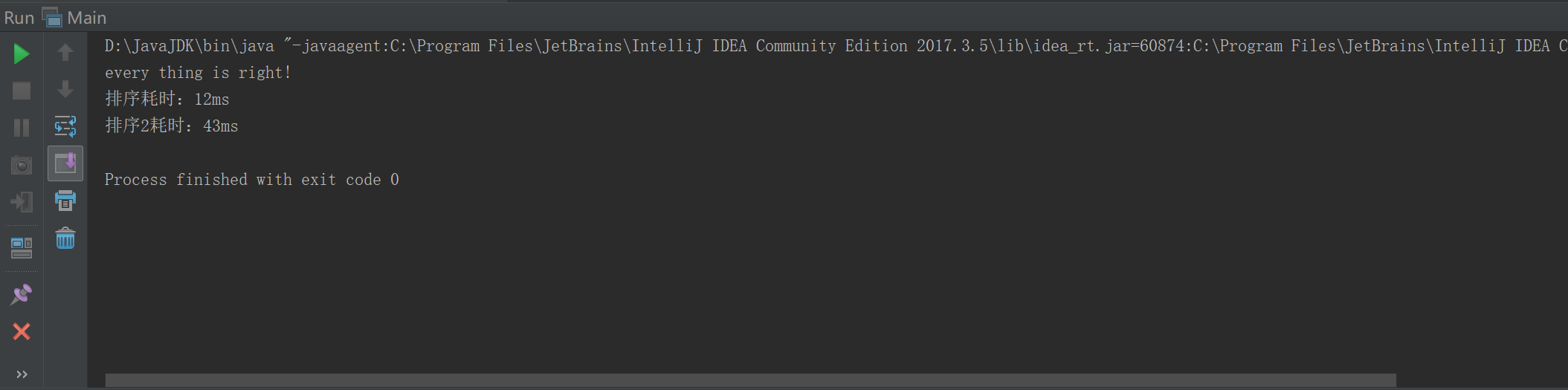
(比较器:排序1;快排:排序2)
出人意料的快排惨败。
分析原因:怀疑是所取的中间元没有随机,导致性能损失。
改进一下:(随机取中间元)
修改之后,有一些时候排序耗时比较接近,但仍有差距很大的时候。
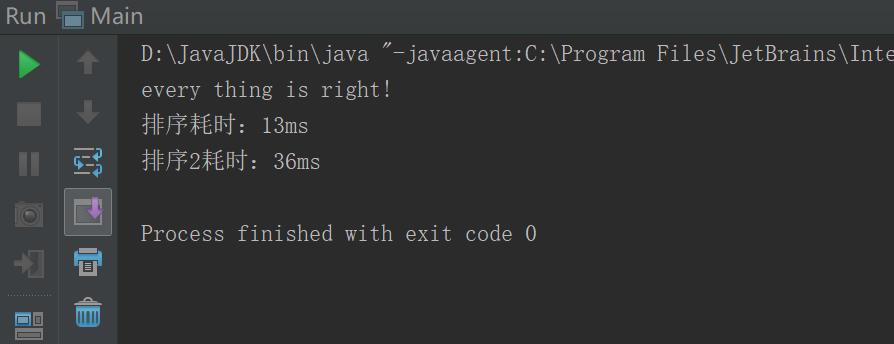
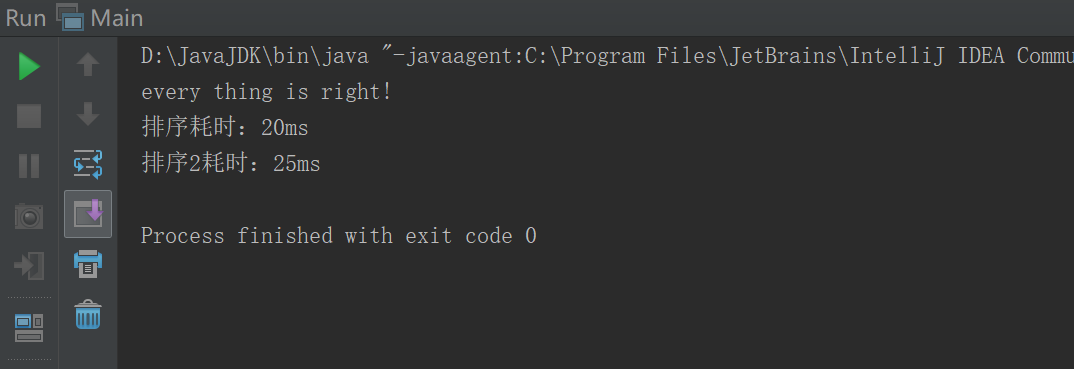
总的来说,实现的快排算法没有比较器的性能好。
综上所述,最终采用的是比较器的排序实现。
心得体会:
""通过基本任务、扩展任务、到高级任务的完成,如何体现软件开发、软件测试、软件质量之间的关系""
对于这一点,我通过本次实验,主要的想法是:
这三者之间是存在紧密的联系的。
软件开发离不开测试。不仅是相互的测试,专业测试员对代码的测试,程序开发者也应对自己的代码进行测试,来保证程序(软件)的质量。
这一点体会很深。
因为有的时候,程序员自己是最了解自己的逻辑的,也在一定角度上,是最容易发现自己的逻辑错误的。
(当然,他山之石,可以攻玉,其他人有时候也会发现程序员自身容易忽略的问题)
但是!很少会有人仔细的研究别人的代码,并找出隐藏的很深的逻辑错误。
而且,其他人进行测试,一来有可能测试用例设计的不好,且难以实现。二来,这样需要的成本也大大增加。
所以,最划算,最优的还是自身尽可能找出不规范的,错误的地方。
就比如我在自己审核自己的代码的时候,就发现了一个逻辑上的bug,在上文中有所赘述。
(参见 ”基本任务“模块中 ”发现的问题“子模块)
想要获得优良的质量,当然也需要不断的测试,发现问题并改进,也要主动的思考,审核程序在哪里制约了性能,并着手考虑其他更优方法。
总之,就是这样。
参考链接:
1. git tag推送:
https://blog.csdn.net/b735098742/article/details/78935748
2. map排序参考:
https://www.cnblogs.com/avivahe/p/5657070.html
3. 比较器:
https://blog.csdn.net/xiaokui_wingfly/article/details/42964695
4. JUnit参考
https://www.cnblogs.com/huaxingtianxia/p/5563111.html
5. 发现的一个读取txt文件的问题(可能解答)
https://blog.csdn.net/wangzhi291/article/details/41485403
6. 关于arg数组。
https://www.cnblogs.com/xy-hong/p/7197725.html
7.性能测试方面(统计时长)
https://blog.csdn.net/sinat_28789467/article/details/72808507
转载于:https://www.cnblogs.com/dzx1997/p/8728063.html
最后
以上就是震动电灯胆最近收集整理的关于软件质量与测试--第四周作业 wcProGithub地址:PSP:解题思路:测试用例:扩展任务:性能测试与优化:参考链接:的全部内容,更多相关软件质量与测试--第四周作业内容请搜索靠谱客的其他文章。






![[构建之法论坛] 助教之路](https://www.shuijiaxian.com/files_image/reation/bcimg19.png)

发表评论 取消回复