目的
大家说到kafka,肯定就会想到“快”和“高吞吐量”,特别是吞吐量这一点,好像目标就没有超越kafka的。
本文就是解释了kafka怎么做到“快”和“高吞吐量”。
producer
producer客户端有4个跟吞吐量相关的配置:
- max.in.flight.requests.per.connection,每个连接没有收到响应的最大请求数,默认5。未确认的请求数达到该配置,那么对应的连接就不能再用来发消息
- compression.type,配置对发送的消息使用的压缩方式,默认不压缩
- max.request.size,限制客户端能发送的消息的最大大小,默认1MB
- linger.ms,如果消息的大小没有到达max.request.size,那么会等到linger.ms配置的毫秒数,再把消息发出去
max.in.flight.requests.per.connection,很好理解,不用等到上一个请求被响应就接着发下一个请求,并发的发送请求会比串行的效率高。
compression.type,对消息进行压缩,那么传输的数据量会变小,,传输的速度就会变快,吞吐量就会更高。
linger.ms和max.request.size是一对组合。举个例子,linger.ms配置为10,我们的应用程序在10ms内会发送100个消息,消息总大小为9KB,由于没有达到max.request.size配置的值,所以这100个消息会停留到10ms,最后9KB的数据作为一个请求发送给broker。这样能减少网络传输的次数,原来要100次网络传输,变成了1次。
如果是compression.type+max.request.size+linger.ms效果会更明显,以上面的例子,9KB的数据会作为一个整体进行压缩,压缩比会比压缩单个消息提高不少。
但这些参数使用起来,也要小心一些,因为会有些副作用,需要根据自己实际情况做选择。
max.in.flight.requests.per.connection,当出现发送失败,重试发送的情况下,可能导致消息乱序!
linger.ms,如果设置过大,导致消息的实时性降低,也有可能造成无用的等待,例如每10ms我们最多只发1个消息,那么linger.ms配置为10,完全没有意义。
max.request.size,每个请求的大小,不是无限制的,broker有另外一个配置message.max.bytes限制接收到的消息大小,如果超过该配置,消息会被拒绝。
broker
当producer发送消息给broker时,broker会把消息写入到磁盘中,将数据罗盘,保证数据的持久化存储。
kafka基于磁盘,然后采用了两种技术来优化写入速度:
- 顺序写入
- MMFiles(Memory Mapped Files)
使用零拷贝技术来优化数据发送给消费者的速度。
顺序写入
一般,大家都会觉得磁盘的读写速度远远低于内存的读写,但这其实不是绝对的。 磁盘的读写快慢取决于你如何使用它,顺序VS随机。
磁盘是机械结构,操作数据的时候都需要经过【寻址->写入】的过程,大部分的时间都是花费在“寻址”上。随机I/O,每次操作都需要重新“寻址”,花费的时间多,性能低;但是顺序I/O,只需要进行一次“寻址”,所以效率高,性能能赶得上内存随机I/O的性能。
所以kafka使用了顺序写入的方式来提交写入速度。除此之外,我们的操作做系统自身也对顺序I/O做了很多优化,例如read-ahead、write-behind和磁盘缓存等。
使用磁盘还有另外两个好处:
- JVM的GC效率低,内存占用大,使用磁盘可以避免这一问题。
- .系统冷启动后,磁盘上的缓存依然可用。内存一旦关机数据就会清空,持久化到磁盘上则不会。
MMFiles
Memory Mapped Files被翻译为内存映射文件。原理就是直接利用操作系统的Page来实现文件到物理内存的直接映射。建立映射之后,我们对物理内存的操作会被同步到磁盘上。java中的MappedByteBuffer就是干这个事情,写成qmq也是用这种方式来将数据落盘。
通过这种方式,进程可以像读写硬盘一样读写内存,省去了用户空间到内核空间的复制开销。例如我们读取一个文件的内容,需要先把数据从磁盘督学到内核空间的内存里,再从内核空间复制到用户空间的内存。
Zero Copy——sendfile
在传统模式下,我们从文件读取数据,发送给远程的消费者,过程是这样的:
1.调用read函数,文件数据被copy到内核的缓冲区。
2.read函数返回,文件数据从内核缓冲区copy到用户缓冲区。
3.write函数调用,将文件数据从用户缓冲区copy到内核的Socket缓冲区。
4.数据从Socket缓冲区copy到网卡。
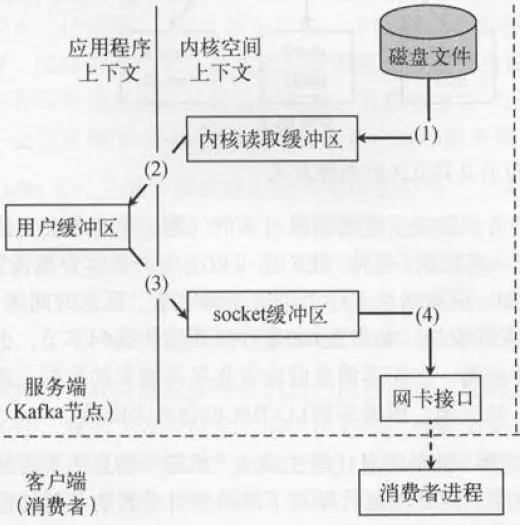
这个过程,数据总共经历了4次拷贝:磁盘—>内核读缓冲区—>用户缓冲区>socket缓冲区—>网卡
而使用sendfile系统调用,则会降拷贝次数降为2次:
1.调用read函数,文件数据被copy到内核的缓冲区。
2.将文件数据从内核缓冲区copy到网卡。
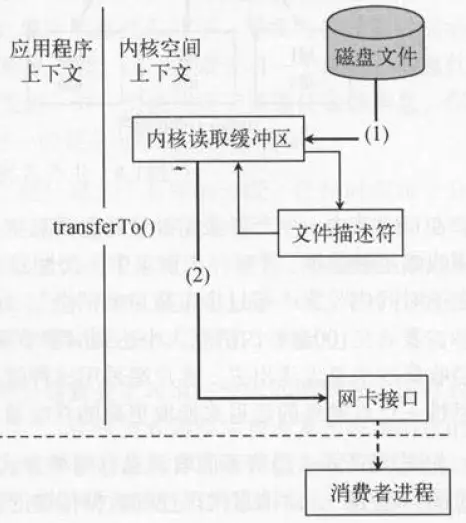
如果有10个消费者,传统方式下,数据复制次数为4*10=40次,而使用“零拷贝技术”只需要1+10=11次,一次为从磁盘复制到页面缓存,10次表示10个消费者各自读取一次页面缓存。
分区
同一个主题的不同分区,会被尽可能的分散到不同的broker节点,每个分区之间是并行的关系。所以适当的增加主题的分区数,能提高指定主题的吞吐量。但当分区数到达一定数量后,就不会增加了,反而会下降。
为啥会下降的?
个人猜测!!! broker节点数量是固定的,当分区数量太多的时候,每个broker节点被分配的分区数很多。而每个分区是有自己独立的存储文件的。在面对很多个文件的时候,kafka的顺序写,就可能变成随机读写了。一下读写这个文件,一下读写另外一个文件,不断的磁盘寻址。个人猜测而已哈~
consumer
consumer客户端有5个跟吞吐量有关系的配置:
- fetch.min.bytes,一次poll请求能从broker拉取的最小字节,不满足则会等待,默认1B。
- fetch.max.bytes,一次poll请求能从broker拉取的最搭字节,默认52428800B==50MB(单个消息大小大于该值,也能被消费)。
- fetch.max.wait.ms,与fetch.min.bytes配合,如果消息大小达不到fetch.min.bytes,就会等待的最大时间,默认500ms。
- max.patition.fetch.bytes, 一个poll请求,一个分区可以给consumer的最大数据量,默认1MB。
- max.poll.records,一次poll请求,最多给consumer返回多少个消息。
这5个配置,决定了一次poll请求最多等待多久,最少拉取多少数据,最大拉取多少数据,最多拉取多少个消息。如果设置得大一些,那么一次性拉取的数据量就会大一些,较小了网络开销,但实时性会差一些。
一些结论
除了broker端使用顺序I/O、Memory Mapped Files和zero copy技术来优化性能,提高吞吐量。
在producer和consumer客户端,都用了延时->聚集信息的方式来性能。
这对于整体来说,提高了吞吐量,但是对于单个消息来说,其实“变慢”了,因为需要经历发送的延时,拉取消息的延时。
所以说kafka快,是针对整体的吞吐量来说的,要在有大量消息被发送和消费的情况下,才能体现出它的优势。如果业务系统发送消息的频率很低,使用kafka就没有必要了,使用RocketMq或者RabbitMq这些应该会更合适。
最后
以上就是安静香氛最近收集整理的关于kafka为什么快,为什么吞吐量高的全部内容,更多相关kafka为什么快内容请搜索靠谱客的其他文章。








发表评论 取消回复