kafka在众多消息队列中,性能肯定是第一梯队的,有着很高的吞吐量,每秒钟可以达到500M以上的吞吐量。
而kafka能够做到这么高的吞吐量,离不开高性能的IO,kafka是从以下几个方面来提升高性能IO的。
- 批处理
从生产者发送到消费者消费,整个过程中,kafka都进行了批处理的操作。
生产者发送一条消息,无论是同步还是异步发送的,kafka都不会立马把这条消息发送出去,而是先放到内存中,将多个单条消息组成一个批消息,发到broker端。
到了broker端,这一个批消息并不会被拆解开,而是仍旧作为一个批消息来读写磁盘,同步到其他副本中。
消费者消费的也是这一个批消息,消费者读取到这个批消息后,在客户端来将批消息拆解还原一条条消息,再对每条消息进行代码逻辑的处理。
- 消息压缩
kafka提供了消息压缩的能力,生产者发送一条批消息,可以开启压缩功能。当然,压缩和解压缩是比较耗费cpu的,所以,当系统cpu负载过高,不建议开启kafka的压缩。当系统带宽不足,cpu负载不高,可以开启压缩,节约大量的带宽。当开启压缩后,要注意保持生产者压缩算法和broker端压缩算法的一致。
- 顺序读写提升磁盘性能
这个不需要多解释了,磁盘随机读写,就需要进行寻址。而kafka使用顺序进行磁盘读写,一个log文件写满了,就继续写下一个log文件,大大提升了kafka在读写磁盘时的性能。
- pagecache加速读写
pagecache是操作系统的基本特性,是操作系统给磁盘文件在内存中建立的缓存。当使用操作系统api来读取文件,实际上是读取的pagecache缓存中的数据,如果缓存中没有相应的数据,就会引发一个操作系统的缺页中断,读取的线程进入阻塞,等待操作系统将文件内的数据读取到pagecache中,随后读取的线程继续工作读取数据。
kafka也是使用该操作系统的基本特性,操作如下图
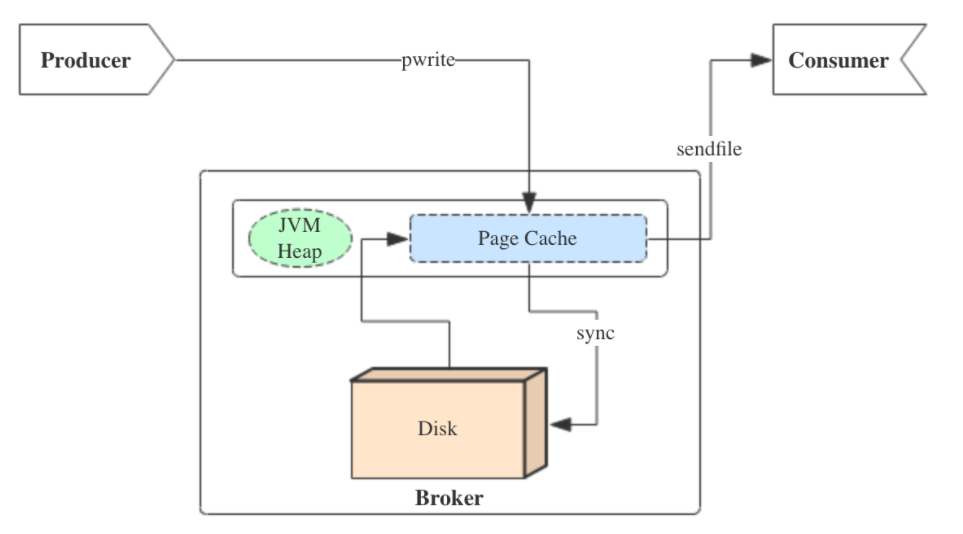
生产者写消息和消费者读消息,都是通过操作系统pagecache来进行。
- 零拷贝
操作系统进行读写数据,主要经过几次复制操作,拿通过网络读取数据来举例,文件中的数据首先会被读取到内核态,内核态的数据又会被复制到用户态,用户态的数据被复制到socket的缓冲区,通过网络被读取。
kafka中就是通过将pageCache中的数据直接复制到socket的缓冲区,减少了内核态到用户态再到socket缓冲区的复制过程。
最后
以上就是精明花生最近收集整理的关于kafka是如何实现高性能的全部内容,更多相关kafka是如何实现高性能内容请搜索靠谱客的其他文章。








发表评论 取消回复