序言:
Kafka是一个依赖磁盘来存储和缓存消息,一般对于磁盘的读写我们认为它的速度很慢的(实际上对于磁盘的读写速度也是根据我们的使用方式来决定它的快慢,例如如果我们进行顺序读写那么它的速度和随机内存访问相差无几,但若我们进行随机读写时,该效率与内存相差千倍),关于服务器中各存储介质的读写速度可参考以下图。
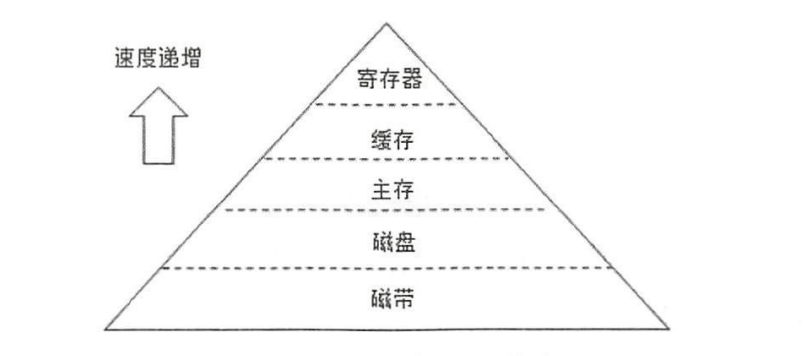
从上述我们可以看出磁盘处于一个底层的位置,而缓存(内存)处于金字塔位置。那么Kafka为何不向Rabbitmq那样采用内存作为默认的存储介质,使用磁盘作为备用(使用磁盘作为消息的持久化,避免内存丢失)来以此实现高吞吐和低延迟的特性 。这与Kafka的设计有一定关系,Kafka在创立之初就是作为日志系统采集的中间件而使用,对于日志文件每日可产生海量的数据,而且这些数据可能被进行落地存储一定日期,对于这些数据我们如果的存储在内存中,很显然第一成本很大,第二不一定有那么大的内存硬件供我们使用(kafka也会使用到内存,只不过不会非常依赖(当然内存大在数据体量大的时候也会有好处,后文叙述),这也是我们在大数据场景中可以看到kafka的原因-内存比磁盘贵)。而Rabbitmq它的设计模式是为了更快的将数据push给消费者,并且当消费者进行ack时,该条消息就会标记删除,后续会有其它线程进行del。 第二也是最重要的一点Kafka通过设计了存储的数据结构,读写的使用方式来规避了磁盘的缺点,放大磁盘的优点,最终达到高吞吐和低延迟的特性,对比Rabbitmq来说,吞吐量比Rabbitmq高而延迟相对于Rabbitmq的ns Kafka的ms也是可以接受。
1:顺序读写
Kafka对于数据写入磁盘文件,都以文件追加的形式,不会存在对之前数据的修改,(只有当满足一定条件会进行segment分段存储,即将最后文件置为可读,并创建新的log,及索引文件,并设置为读写,最后的offset作为文件名。这些条件有以下四种:
- 当log文件的体量超过超过broker设置的阈值(log.segment.bytes=1073741824-1G内存)
- 当index文件的体量超过来broker设置的阈值(log.index.size.max.bytes=10485760-10M配置的值)
- 当前日志分段中消息的最大时间戳与当前系统的时间戳的差值大于 log.roll.ms或log.roll.hours的参数配置的值。如果同时配置了 log.roll.ms log.roll.hours 参数,那么 log.roll.ms 的优先级高。默认情况下,只配置了 log.roll.hours 参数,其值为168即7天
- 当前文件中baseOffset与laxBaseOffset之间的差超过了 Integr.MAX_VALUE 要追加的消息的偏移量不能转变为相对偏移量,实际上索引文件中每一个索引由relativeOffset与posittion组成,每一个都占4b,而超过了Integr.MAX_VALUE无法存储到索引目录中)
图片来源于:https://queue.acm.org/detail.cfm?id=1563874

从上文可以看出顺序读写的效率还要优于随机内存的效率
2:页缓存
PageCahe是一个操作系统对于磁盘的缓存(其实可以类比为何我们在应用层面加入redis作为缓存,减少对db的访问),而PageCahe就是尽量减少对磁盘io的操作。本质上就是将磁盘中的数据缓存到内存中,把对磁盘的访问变更为对内存的访问,在一个进程准备读取磁盘中文件的内容时,操作系统会先查看待读取的数据所在的页是否存在pageCache,如果命中直接从pageCache中读取,如果没有命中就先从磁盘中读取并且再将数据存储到pageCache中最后将数据返回到进程中(该动作是否和我们在应用中使用redis做缓存一致)。当有进程对数据写入磁盘时,操作系统也会将查看数据在pageCache中是否存在,若不存在先创建在pageCache中创建对应的页,最后将数据写入到页中,若存在也会将数据进行变更,这些被修改过的页被称为脏页,在一定时间后操作系统就会将脏页中的数据写入到磁盘中保证数据的最终一致性(上述的操作实际就是linunx中write()与read()函数的体现-在redis中数据aof时也描述过这些函数,上述的动作会存在数据丢失的可能,我们可以通过调用sync()或fsync()强制在数据写入到pageCache后强制刷新到磁盘中,但该动作会极大消耗性能,Kafka中broker也提供了两个参数来决定flush到磁盘的阈值:log.flush.interval.messages 写入多少条消息进行磁盘写入,log.flush.interval.ms默认将内存中日志刷新到磁盘时间,Kafka默认是由操作系统来决定pageCache中数据什么时候写入到磁盘中,为何这样设置的原因在于这样的设置保证数据读写的性能最高,而关于数据的不丢失是Kafka通过多副本的机制来完成,没必要为了数据不丢失而这样设置)。
Linux 操作系统中的 vm.dirty_background_ratio 参数用来指定当脏页数量达到系统 内存的百分之多少之后就会触发pdflush/flush/kdmflush 等后台回写进程的运行来理脏页一般般设置为小于 10 的值即可,但不建议设置为0,与这个参数对应的还有 vm.dirty_ratio参数它用来指定当脏页数达到系统内存的百分之多少之后就不得不开始对脏页进行处理。在此过程中,新的 I/O 请求会被阻挡直至所有脏页被冲刷到磁盘中。
3:零拷贝(Zero-copy)
数据直接从磁盘文件复制到网卡设备中,而不需要经由应用程序。零拷贝大大提高了应用程序的性能,减少了内核和用户模式之间的上下文切换。如下所示是一个将数据从磁盘中读取出来写入到网卡设备中的过程(一个非zero-copy另外一种是zero-copy):
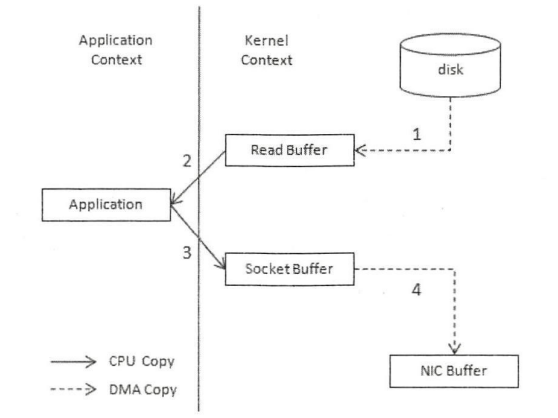
- 从磁盘中将数据写入到内核中的ReadBuffer中
- CPU控制将内核中的数据copy到应用进程(用户态)中数据
- CPU将用户态中的数据写入到内核的Socket Buffer中
- 将内核的Socket Buffer写入到网卡设备中发送
从上述可以看出,数据从磁盘到网卡发送总共经历来4次copy而用户态与内核态的的上下文切换也经历过4次
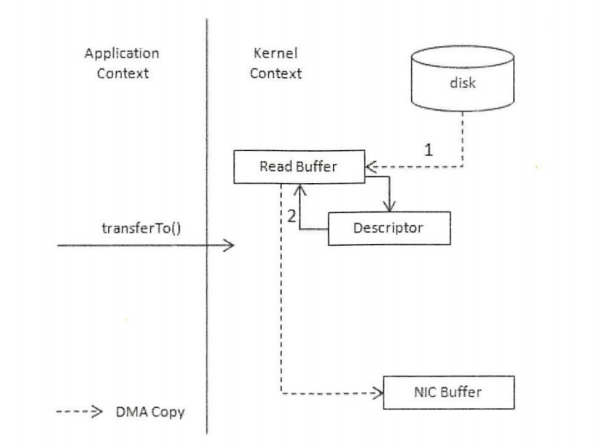
上文就是使用了zero-copy使得总体数据的copy只有2次,第一次:零拷贝技术通过 DMA (Direct Memory Access )技术将文件内容复制到内核模式下的 Read Buffer 。不过没有数据被复制到 Socke Buffer ,相反只有包含数据的位置和长度的信息的文件描述符被加到 Socket Buffer中(可以忽略不计),第二次:DMA引擎直接将数据从内核模式中传递到网卡设备。这里数据只经历了2次复制就从磁盘中传送出去了,并且上下文切换也变成了2次。 零拷贝是针对内核模式而言的数据在内核模式下实现了零拷贝。在linux中通过sendfile()函数实现,在Java NIO包中提供了零拷贝机制对应的API,即FileChannel.transferTo()方法实际上是是一个native方法,最终如果在linux中也是调用sendfile()函数的
最后
以上就是坚强奇迹最近收集整理的关于Kafka吞吐量为啥那么大的全部内容,更多相关Kafka吞吐量为啥那么大内容请搜索靠谱客的其他文章。








发表评论 取消回复