到目前为止,有关Redis客户端的相关知识基本已经介绍完毕,本节将
通过Redis开发运维中遇到的两个案例分析,让读者加深对于Redis客户端相
关知识的理解。
4.6.1 Redis内存陡增
1.现象
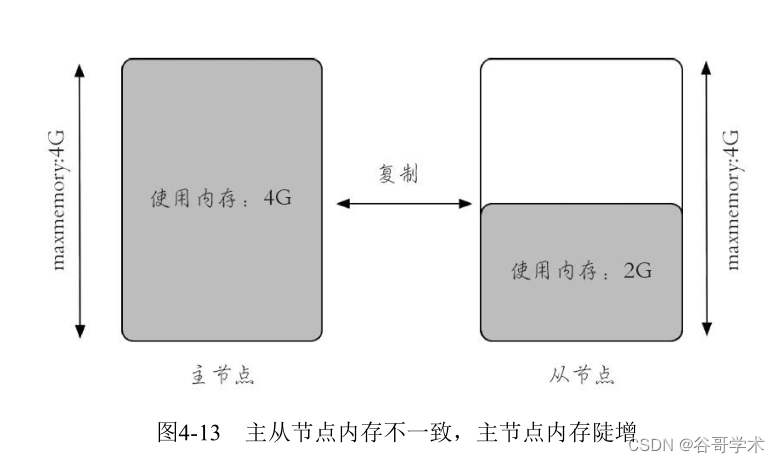
服务端现象:Redis主节点内存陡增,几乎用满maxmemory,而从节点
内存并没有变化(第5章将介绍Redis复制的相关知识,这里只需要知道正常
情况下主从节点内存使用量基本相同),如图4-13所示。
客户端现象:客户端产生了OOM异常,也就是Redis主节点使用的内存
已经超过了maxmemory的设置,无法写入新的数据:
redis.clients.jedis.exceptions.JedisDataException: OOM command not allowed when
used memory > 'maxmemory'
2.分析原因
从现象看,可能的原因有两个。
1)确实有大量写入,但是主从复制出现问题:查询了Redis复制的相关
信息,复制是正常的,主从数据基本一致。
主节点的键个数:
127.0.0.1:6379> dbsize
(integer) 2126870
从节点的键个数:
127.0.0.1:6380> dbsize
(integer) 2126870
2)其他原因造成主节点内存使用过大:排查是否由客户端缓冲区造成
主节点内存陡增,使用info clients命令查询相关信息如下:
127.0.0.1:6379> info clients
# Clients
connected_clients:1891
client_longest_output_list:225698
client_biggest_input_buf:0
blocked_clients:0
很明显输出缓冲区不太正常,最大的客户端输出缓冲区队列已经超过了
20万个对象,于是需要通过client list命令找到omem不正常的连接,一般来
说大部分客户端的omem为0(因为处理速度会足够快),于是执行如下代
码,找到omem非零的客户端连接:
redis-cli client list | grep -v "omem=0"
找到了如下一条记录:
id=7 addr=10.10.xx.78:56358 fd=6 name= age=91 idle=0 flags=O db=0 sub=0 psub=0
multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=224869 omem=2129300608 events=rw cmd=monitor
已经很明显是因为有客户端在执行monitor命令造成的。
3.处理方法和后期处理
对这个问题处理的方法相对简单,只要使用client kill命令杀掉这个连
接,让其他客户端恢复正常写数据即可。但是更为重要的是在日后如何及时
发现和避免这种问题的发生,基本有三点:
·从运维层面禁止monitor命令,例如使用rename-command命令重置
monitor命令为一个随机字符串,除此之外,如果monitor没有做rename-
command,也可以对monitor命令进行相应的监控(例如client list)。
·从开发层面进行培训,禁止在生产环境中使用monitor命令,因为有时
候monitor命令在测试的时候还是比较有用的,完全禁止也不太现实。
·限制输出缓冲区的大小。
·使用专业的Redis运维工具,例如13章会介绍CacheCloud,上述问题在
Cachecloud中会收到相应的报警,快速发现和定位问题。
4.6.2 客户端周期性的超时
1.现象
客户端现象:客户端出现大量超时,经过分析发现超时是周期性出现
的,这为问题的查找提供了重要依据:
Caused by: redis.clients.jedis.exceptions.JedisConnectionException: java.net.
SocketTimeoutException: connect timed out
服务端现象:服务端并没有明显的异常,只是有一些慢查询操作。
2.分析
·网络原因:服务端和客户端之间的网络出现周期性问题,经过观察网
络是正常的。
·Redis本身:经过观察Redis日志统计,并没有发现异常。
·客户端:由于是周期性出现问题,就和慢查询日志的历史记录对应了
一下时间,发现只要慢查询出现,客户端就会产生大量连接超时,两个时间
点基本一致(如表4-6和图4-14所示)。
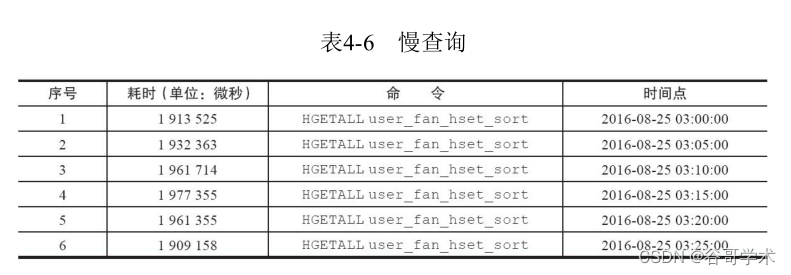
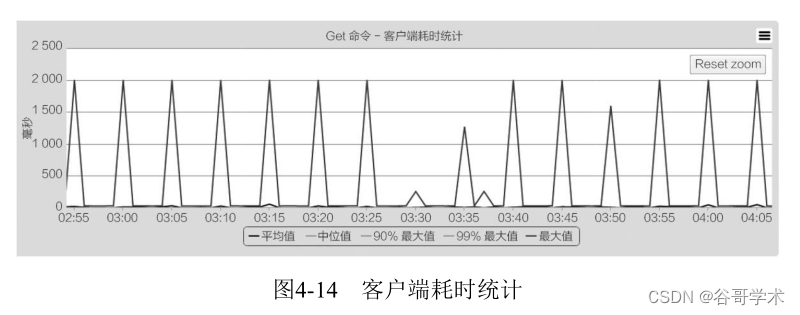
最终找到问题是慢查询操作造成的,通过执行hlen发现有200万个元
素,这种操作必然会造成Redis阻塞,通过与应用方沟通了解到他们有个定
时任务,每5分钟执行一次hgetall操作。
127.0.0.1:6399> hlen user_fan_hset_sort
(integer) 2883279
以上问题之所以能够快速定位,得益于使用客户端监控工具把一些统计
数据收集上来,这样能更加直观地发现问题,如果Redis是黑盒运行,相信
很难快速找到这个问题。处理线上问题的速度非常重要。
3.处理方法和后期处理
这个问题处理方法相对简单,只需要业务方及时处理自己的慢查询即
可,但是更为重要的是在日后如何及时发现和避免这种问题的发生,基本有
三点:
·从运维层面,监控慢查询,一旦超过阀值,就发出报警。
·从开发层面,加强对于Redis的理解,避免不正确的使用方式。
·使用专业的Redis运维工具,例如13章会介绍CacheCloud,上述问题在
CacheCloud中会收到相应的报警,快速发现和定位问题。
最后
以上就是要减肥缘分最近收集整理的关于Redis入门完整教程:客户端案例分析的全部内容,更多相关Redis入门完整教程内容请搜索靠谱客的其他文章。








发表评论 取消回复