文章目录
- 前端性能优化篇
- 一、DOM的优化原理
- 二、图片优化
- 三、浏览器缓存策略
- 四、本地存储
- 五、CDN缓存与回源
- 六、浏览器运行机制
- 七、首屏加载优化(LazyLoad)
- 八、事件的节流(throttle)与防抖(debounce)
- 九、chrome performance看浏览器渲染过程
前端性能优化篇
从输入URL到页面加载完成,发生了什么?
1、浏览器的地址栏输入URL并按下回车。
2、浏览器查找当前URL是否存在缓存,并比较缓存是否过期。
3、DNS解析URL对应的IP。
4、根据IP建立TCP连接(三次握手)。
5、HTTP发起请求。
6、服务器处理请求,浏览器接收HTTP响应。
7、渲染页面,构建DOM树。
8、关闭TCP连接(四次挥手)。
一、DOM的优化原理
把 DOM 和 JavaScript 各自想象成一个岛屿,它们之间用收费桥梁连接。——《高性能 JavaScript》
我们每操作一次 DOM(不管是为了修改还是仅仅为了访问其值),都要过一次“桥”。过“桥”的次数一多,就会产生比较明显的性能问题。因此“减少 DOM 操作”的建议,并非空穴来风。
对 DOM 的修改引发样式的更迭
很多时候,我们对 DOM 的操作都不会局限于访问,而是为了修改它。当我们对 DOM 的修改会引发它外观(样式)上的改变时,就会触发回流或重绘。
-
回流:当我们对 DOM 的修改引发了 DOM 几何尺寸的变化(比如修改元素的宽、高或隐藏元素等)时,浏览器需要重新计算元素的几何属性(其他元素的几何属性和位置也会因此受到影响),然后再将计算的结果绘制出来。这个过程就是回流(也叫重排)。
-
重绘:当我们对 DOM 的修改导致了样式的变化、却并未影响其几何属性(比如修改了颜色或背景色)时,浏览器不需重新计算元素的几何属性、直接为该元素绘制新的样式(跳过了上图所示的回流环节)。这个过程叫做重绘。
举个我们常见的例子:
<div v-for="item in list">{{item.name}}</div>
this.list = res.data
this.list.map(ele => ele.name = 'aaa')
for (let i = 0; i< this.list.length;i++) {
this.list[i].name = "123"
}
// 建议做法
res.data.map(ele => ele.name = 'aaa')
this.list = res.data
重绘不一定导致回流,回流一定会导致重绘。硬要比较的话,回流比重绘做的事情更多,带来的开销也更大。但这两个说到底都是吃性能的,所以都不是什么善茬。我们在开发中,要从代码层面出发,尽可能把回流和重绘的次数最小化。
// 假设有一段操作DOM的css代码
const container = document.getElementById('container')
container.style.width = '100px'
container.style.height = '200px'
container.style.border = '10px solid red'
container.style.color = 'red'
...(省略了许多类似的后续操作)
- 避免逐条改变样式,使用类名去合并样式
.basic_style {
width: 100px;
height: 100px;
background-color: yellow;
position: absolute;
}
const container = document.getElementById('container')
container.classList.add('basic_style')
-
将DOM“离线”
一旦我们给元素设置 display: none,将其从页面上“拿掉”,那么我们的后续操作,将无法触发回流与重绘——这个将元素“拿掉”的操作,就叫做 DOM 离线化。
let container = document.getElementById('container')
container.style.display = 'none'
container.style.width = '100px'
container.style.height = '200px'
container.style.border = '10px solid red'
container.style.color = 'red'
...(省略了许多类似的后续操作)
container.style.display = 'block'
-
Flush 队列:浏览器并没有那么简单
因为现代浏览器是很聪明的。浏览器自己也清楚,如果每次 DOM 操作都即时地反馈一次回流或重绘,那么性能上来说是扛不住的。于是它自己缓存了一个 flush 队列,把我们触发的回流与重绘任务都塞进去,待到队列里的任务多起来、或者达到了一定的时间间隔,或者“不得已”的时候,再将这些任务一口气出队。因此我们看到,上面就算我们进行了 4 次 DOM 更改,也只触发了一次 Layout 和一次 Paint。
二、图片优化
JPG
关键字:有损压缩、体积小、加载快、不支持透明
JPG 最大的特点是有损压缩。这种高效的压缩算法使它成为了一种非常轻巧的图片格式。另一方面,即使被称为“有损”压缩,JPG的压缩方式仍然是一种高质量的压缩方式:当我们把图片体积压缩至原有体积的 50% 以下时,JPG 仍然可以保持住 60% 的品质。此外,JPG 格式以 24 位存储单个图,可以呈现多达 1600 万种颜色,足以应对大多数场景下对色彩的要求,这一点决定了它压缩前后的质量损耗并不容易被我们人类的肉眼所察觉——前提是你用对了业务场景。
PNG-8 与 PNG-24
关键字:无损压缩、质量高、体积大、支持透明
PNG(可移植网络图形格式)是一种无损压缩的高保真的图片格式。8 和 24,这里都是二进制数的位数。按照我们前置知识里提到的对应关系,8 位的 PNG 最多支持 256 种颜色,而 24 位的可以呈现约 1600 万种颜色。
PNG 图片具有比 JPG 更强的色彩表现力,对线条的处理更加细腻,对透明度有良好的支持。它弥补了上文我们提到的 JPG 的局限性,唯一的 BUG 就是体积太大。
SVG
关键字:文本文件、体积小、不失真、兼容性好
SVG(可缩放矢量图形)是一种基于 XML 语法的图像格式。它和本文提及的其它图片种类有着本质的不同:SVG 对图像的处理不是基于像素点,而是是基于对图像的形状描述。
Base64
关键字:文本文件、依赖编码、小图标解决方案
Base64 并非一种图片格式,而是一种编码方式。Base64 和雪碧图一样,是作为小图标解决方案而存在的。在了解 Base64 之前,我们先了解一下雪碧图。
WebP
关键字:年轻的全能型选手
WebP 是今天在座各类图片格式中最年轻的一位,它于 2010 年被提出, 是 Google 专为 Web 开发的一种旨在加快图片加载速度的图片格式,它支持有损压缩和无损压缩。
三、浏览器缓存策略
缓存可以减少网络 IO 消耗,提高访问速度。浏览器缓存是一种操作简单、效果显著的前端性能优化手段。对于这个操作的必要性,Chrome 官方给出的解释似乎更有说服力一些:
通过网络获取内容既速度缓慢又开销巨大。较大的响应需要在客户端与服务器之间进行多次往返通信,这会延迟浏览器获得和处理内容的时间,还会增加访问者的流量费用。因此,缓存并重复利用之前获取的资源的能力成为性能优化的一个关键方面。
浏览器缓存机制有四个方面,它们按照获取资源时请求的优先级依次排列如下:
- Memory Cache — “from memory cache”
- Service Worker Cache — “from ServiceWorker”
- HTTP Cache
- Push Cache — HTTP2 的新特性
HTTP 缓存是我们日常开发中最为熟悉的一种缓存机制。它又分为强缓存和协商缓存。优先级较高的是强缓存,在命中强缓存失败的情况下,才会走协商缓存。
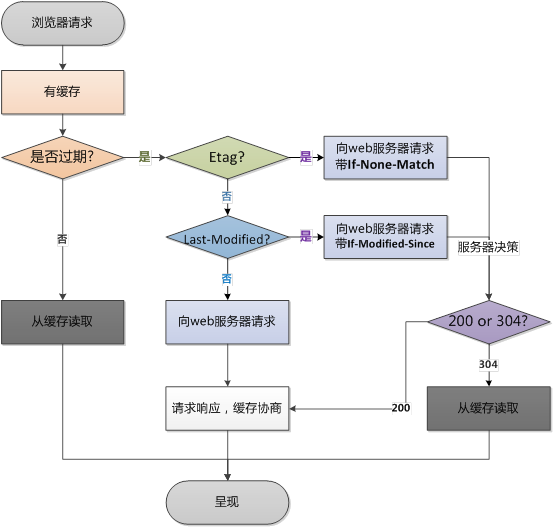
在http1.1中以cache-control为准,cache-control有很多种值,具体可以百度,这里只说cache-control的使用,在第一次访问一个页面时会从服务器取到一些js、css文件,这时返回的httpcode是200,表示成功从服务器获取到。在第一次访问后,服务器会返回文件缓存的时间expires、max-age等表示过期时间的数值给到客户端,客户端会连文件和这些信息一起缓存在浏览器,在第二次请求时,会判断缓存时间是否过期,如果没过期则会直接从本地获取缓存的css、js等文件,这个过程是不发送http请求的,也就是没有网络依然可以获取到。如果缓存过期则还是会发送http请求到服务器,但是并不是每次都会重新抓取服务器文件并返回,这就要牵涉到lastmodify和etag的问题了。
Lastmodify无法从请求头和响应头中看到,它不显示,但是在第一次请求是会返回给客户端,然后客户端在下一次请求是在requestheader的if-modified-since中传递给服务端,服务端接手后会去和lastmodify做判断,如果一致则返回304,如果不一致则返回200并从新拉取文件。这样做的好处是,可以在文件没有更改但缓存过期的时候避免传递同样的文件给客户端,节约了带宽。
既然已经有lastmodify和cache-control控制了客户端和服务端的缓存,那etag有什么用呢?etag其实是来弥补lastmodify的坑的。假设一种情况,你删掉了文件中的一个空行,导致文件的修改时间变化了,那就会导致lastmodify判断失败进而从新拉取文件浪费带宽,因为实际内容根本没变,而如果开启了etag,则etag会使用一种算法去计算出一个hash值,随后返回给客户端,客户端再一次请求将此值放入if-none-match穿给服务端,服务端判断如果一致则返回304,避免返回文件实体。
详细设置参数cache-ctrol
四、本地存储
Cookie
Cookie 是有体积上限的,它最大只能有 4KB。Cookie 是紧跟域名的。我们通过响应头里的 Set-Cookie 指定要存储的 Cookie 值。默认情况下,domain 被设置为设置 Cookie 页面的主机名。
Local Storage
Local Storage 是持久化的本地存储,存储在其中的数据是永远不会过期的,使其消失的唯一办法是手动删除
Session Storage
Session Storage 是临时性的本地存储,它是会话级别的存储,当会话结束(页面被关闭)时,存储内容也随之被释放。
Web Storage 根据浏览器的不同,存储容量可以达到5-10M 之间。
终极形态:IndexDB
IndexDB 是一个运行在浏览器上的非关系型数据库。既然是数据库了,那就不是 5M、10M 这样小打小闹级别了。理论上来说,IndexDB 是没有存储上限的(一般来说不会小于 250M)。它不仅可以存储字符串,还可以存储二进制数据。
1.打开/创建一个 IndexDB 数据库(当该数据库不存在时,open 方法会直接创建一个名为 xiaoceDB 新数据库)。
// 后面的回调中,我们可以通过event.target.result拿到数据库实例
let db
// 参数1位数据库名,参数2为版本号
const request = window.indexedDB.open("xiaoceDB", 1)
// 使用IndexDB失败时的监听函数
request.onerror = function(event) {
console.log('无法使用IndexDB')
}
// 成功
request.onsuccess = function(event){
// 此处就可以获取到db实例
db = event.target.result
console.log("你打开了IndexDB")
}
2.创建一个 object store(object store 对标到数据库中的“表”单位)。
// onupgradeneeded事件会在初始化数据库版本发生更新时被调用,我们在它的监听函数中创建object store
request.onupgradeneeded = function(event){
let objectStore
// 如果同名表未被创建过,则新建test表
if (!db.objectStoreNames.contains('test')) {
objectStore = db.createObjectStore('test', { keyPath: 'id' })
}
}
3.构建一个事务来执行一些数据库操作,像增加或提取数据等。
// 创建事务,指定表格名称和读写权限
const transaction = db.transaction(["test"],"readwrite")
// 拿到Object Store对象
const objectStore = transaction.objectStore("test")
// 向表格写入数据
objectStore.add({id: 1, name: 'xiuyan'})
五、CDN缓存与回源
CDN (Content Delivery Network,即内容分发网络)指的是一组分布在各个地区的服务器。这些服务器存储着数据的副本,因此服务器可以根据哪些服务器与用户距离最近,来满足数据的请求。 CDN 提供快速服务,较少受高流量影响。
CDN 往往被用来存放静态资源。上文中我们举例所提到的“根服务器”本质上是业务服务器,它的核心任务在于生成动态页面或返回非纯静态页面,这两种过程都是需要计算的。业务服务器仿佛一个车间,车间里运转的机器轰鸣着为我们产出所需的资源;相比之下,CDN 服务器则像一个仓库,它只充当资源的“栖息地”和“搬运工”。
所谓“静态资源”,就是像 JS、CSS、图片等不需要业务服务器进行计算即得的资源。而“动态资源”,顾名思义是需要后端实时动态生成的资源,较为常见的就是 JSP、ASP 或者依赖服务端渲染得到的 HTML 页面。
六、浏览器运行机制
浏览器的“心”,说的就是浏览器的内核。在研究浏览器微观的运行机制之前,我们首先要对浏览器内核有一个宏观的把握。
目前市面上常见的浏览器内核可以分为这四种:Trident(IE)、Gecko(火狐)、Blink(Chrome、Opera)、Webkit(Safari)。
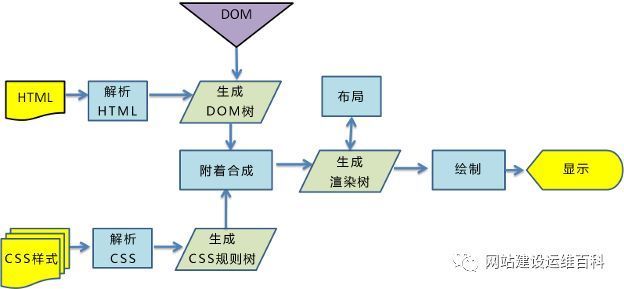
从这个流程来看,浏览器呈现网页这个过程,宛如一个黑盒。在这个神秘的黑盒中,有许多功能模块,内核内部的实现正是这些功能模块相互配合协同工作进行的。其中我们最需要关注的,就是HTML 解释器、CSS 解释器、图层布局计算模块、视图绘制模块与JavaScript 引擎这几大模块:
•HTML 解释器:将 HTML 文档经过词法分析输出 DOM 树。
•CSS 解释器:解析 CSS 文档, 生成样式规则。CSS 引擎查找样式表,对每条规则都按从右到左的顺序去匹配。
•图层布局计算模块:布局计算每个对象的精确位置和大小。
•视图绘制模块:进行具体节点的图像绘制,将像素渲染到屏幕上。
•JavaScript 引擎:编译执行 Javascript 代码。
CSS 的阻塞
CSS 是阻塞的资源。浏览器在构建CSSOM的过程中,不会渲染任何已处理的内容。只有当我们开始解析 HTML 后、解析到 link 标签或者 style 标签时,CSS 才登场,CSSOM 的构建才开始。很多时候,DOM 不得不等待 CSSOM。因此我们可以这样总结:
CSS 是阻塞渲染的资源。需要将它尽早、尽快地下载到客户端,以便缩短首次渲染的时间。
因此将CSS放在head标签里和尽快(启用 CDN 实现静态资源加载速度的优化)。这个“把 CSS 往前放”的动作,对很多同学来说已经内化为一种编码习惯。那么现在我们还应该知道,这个“习惯”不是空穴来风,它是由 CSS 的特性决定的。
JS 的阻塞
JS 的作用在于修改,它帮助我们修改网页的方方面面:内容、样式以及它如何响应用户交互。这“方方面面”的修改,本质上都是对 DOM 和 CSSDOM 进行修改。因此 JS 的执行会阻止 CSSOM,在我们不作显式声明的情况下,它也会阻塞 DOM。
七、首屏加载优化(LazyLoad)
首屏加载是针对图片加载时机的优化:在一些图片量比较大的网站(比如电商网站首页,或者团购网站、小游戏首页等),如果我们尝试在用户打开页面的时候,就把所有的图片资源加载完毕,那么很可能会造成白屏、卡顿等现象,因为图片真的太多了,一口气处理这么多任务,浏览器做不到啊!
再者用户真的需要这么多图片吗?用户点开页面的瞬间,呈现给他的只有屏幕的一部分(我们称之为首屏)。只要我们可以在页面打开的时候把首屏的图片资源加载出来,用户就会认为页面是没问题的。至于下面的图片,我们完全可以等用户下拉的瞬间再即时去请求、即时呈现给他。这样一来,性能的压力小了,用户的体验却没有变差——这个延迟加载的过程,就是 Lazy-Load。
在懒加载的实现中,有两个关键的数值:一个是当前可视区域的高度,另一个是元素距离可视区域顶部的高度。当前可视区域的高度, 在和现代浏览器及 IE9 以上的浏览器中,可以用 window.innerHeight 属性获取。在低版本 IE 的标准模式中,可以用 document.documentElement.clientHeight 获取,这里我们兼容两种情况:
const viewHeight = window.innerHeight || document.documentElement.clientHeight
下面是简单懒加载的例子:
// 获取所有的图片标签
const imgs = document.getElementsByTagName('img')
// 获取可视区域的高度
const viewHeight = window.innerHeight || document.documentElement.clientHeight
// num用于统计当前显示到了哪一张图片,避免每次都从第一张图片开始检查是否露出
let num = 0
function lazyload(){
for(let i=num; i<imgs.length; i++) {
// 用可视区域高度减去元素顶部距离可视区域顶部的高度
let distance = viewHeight - imgs[i].getBoundingClientRect().top
// 如果可视区域高度大于等于元素顶部距离可视区域顶部的高度,说明元素露出
if(distance >= 0 ){
// 给元素写入真实的src,展示图片
imgs[i].src = imgs[i].getAttribute('data-src')
// 前i张图片已经加载完毕,下次从第i+1张开始检查是否露出
num = i + 1
}
}
}
// 监听Scroll事件
window.addEventListener('scroll', lazyload, false);
八、事件的节流(throttle)与防抖(debounce)
懒加载时用的 scroll 事件是一个非常容易被反复触发的事件。其实不止 scroll 事件,resize 事件、鼠标事件(比如 mousemove、mouseover 等)、键盘事件(keyup、keydown 等)都存在被频繁触发的风险。
频繁触发回调导致的大量计算会引发页面的抖动甚至卡顿。为了规避这种情况,我们需要一些手段来控制事件被触发的频率。就是在这样的背景下,throttle(事件节流)和 debounce(事件防抖)出现了。
Throttle: 第一个人说了算
throttle 的中心思想在于:在某段时间内,不管你触发了多少次回调,我都只认第一次,并在计时结束时给予响应。
// fn是我们需要包装的事件回调, interval是时间间隔的阈值
function throttle(fn, interval) {
// last为上一次触发回调的时间
let last = 0
// 将throttle处理结果当作函数返回
return function () {
// 保留调用时的this上下文
let context = this
// 保留调用时传入的参数
let args = arguments
// 记录本次触发回调的时间
let now = +new Date()
// 判断上次触发的时间和本次触发的时间差是否小于时间间隔的阈值
if (now - last >= interval) {
// 如果时间间隔大于我们设定的时间间隔阈值,则执行回调
last = now;
fn.apply(context, args);
}
}
}
// 用throttle来包装scroll的回调
document.addEventListener('scroll', throttle(() => console.log('触发了滚动事件')
Debounce: 最后一个人说了算
防抖的中心思想在于:我会等你到底。在某段时间内,不管你触发了多少次回调,我都只认最后一次。
// fn是我们需要包装的事件回调, delay是每次推迟执行的等待时间
function debounce(fn, delay) {
// 定时器
let timer = null
// 将debounce处理结果当作函数返回
return function () {
// 保留调用时的this上下文
let context = this
// 保留调用时传入的参数
let args = arguments
// 每次事件被触发时,都去清除之前的旧定时器
if(timer) {
clearTimeout(timer)
}
// 设立新定时器
timer = setTimeout(function () {
fn.apply(context, args)
}, delay)
}
}
// 用debounce来包装scroll的回调
document.addEventListener('scroll', debounce(() => console.log('触发了滚动事件'
用 Throttle 来优化 Debounce
debounce 的问题在于它“太有耐心了”。试想,如果用户的操作十分频繁——他每次都不等 debounce 设置的 delay 时间结束就进行下一次操作,于是每次 debounce 都为该用户重新生成定时器,回调函数被延迟了不计其数次。频繁的延迟会导致用户迟迟得不到响应,用户同样会产生“这个页面卡死了”的观感。
为了避免弄巧成拙,我们需要借力 throttle 的思想,打造一个“有底线”的 debounce——等你可以,但我有我的原则:delay 时间内,我可以为你重新生成定时器;但只要delay的时间到了,我必须要给用户一个响应。这个 throttle 与 debounce “合体”思路,已经被很多成熟的前端库应用到了它们的加强版 throttle 函数的实现中
九、chrome performance看浏览器渲染过程
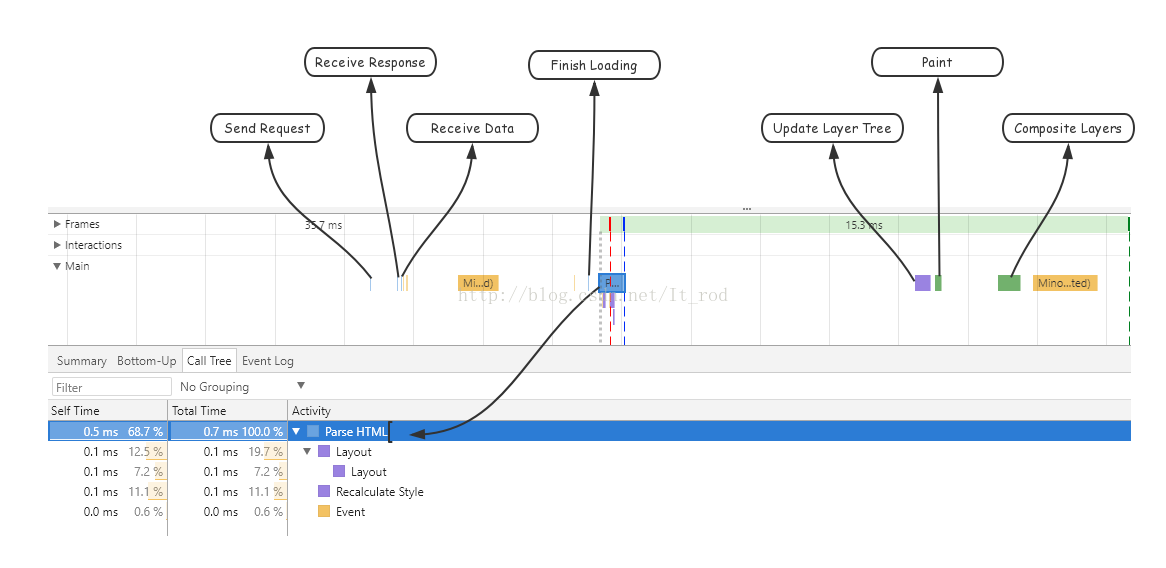
- Send Request—发送网络请求时触发
- Receive Response—响应头报文到达时触发
- Receive Data—请求的响应数据到达事件,如果响应数据很大(拆包),可能会多次触发该事件
- Finish Loading—网络请求完毕事件
- Parse HTML—浏览器执行HTML解析
- Update Layer Tree—(目前还没有找到具体的说明,后面会继续去查找,如果有了解的希望可以告知)。
- Paint—确定渲染树上的节点的大小和位置后,便可以对节点进行涂鸦(paint)
- Composite Layers—合成层;当渲染树上的节点涂鸦完毕后,便生成位图(bitmap),浏览器把此位图从CPU传输到GPU
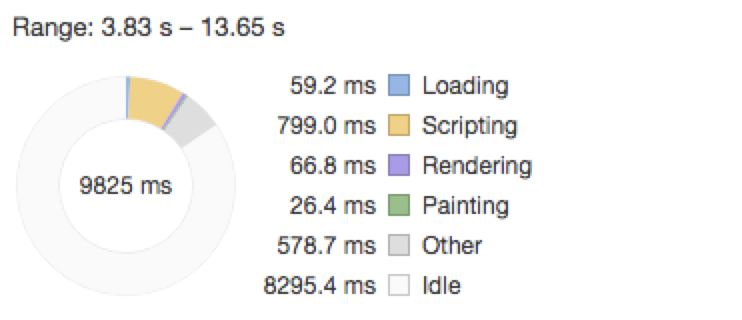
- 蓝色(Loading):网络通信和HTML解析
- 黄色(Scripting):JavaScript执行
- 紫色(Rendering):样式计算和布局,即重排
- 绿色(Painting):重绘
- 灰色(other):其它事件花费的时间
- 白色(Idle):空闲时间
最后
以上就是漂亮耳机最近收集整理的关于前端性能优化篇前端性能优化篇的全部内容,更多相关前端性能优化篇前端性能优化篇内容请搜索靠谱客的其他文章。








发表评论 取消回复