一、Sqoop概述
1.1 Sqoop简介
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库(如MySQL,Oracle,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Sqoop2的最新版本1.99.7;注意:2与1不兼容,且特征不完整,它并不打算用于生产部署;
Sqoop1使用最多。
1.2 Sqoop原理
将导入或导出命令翻译成mapreduce程序来实现;
在翻译出的mapreduce中主要是对inputformat和outputformat进行定制。
1.3 Sqoop架构
sqoop架构非常简单,是hadoop生态系统架构最简单的框架。
sqoop1由client端直接接入hadoop,任务通过解析生成对应的mapreduce执行;
sqoop1:仅有一个客户端,架构简单明了,部署即用,使用门槛比较低;但是耦合性强,用户密码暴露不安全;
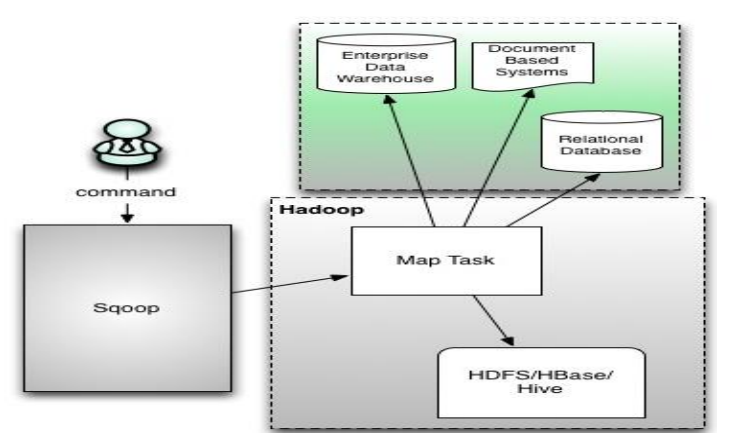
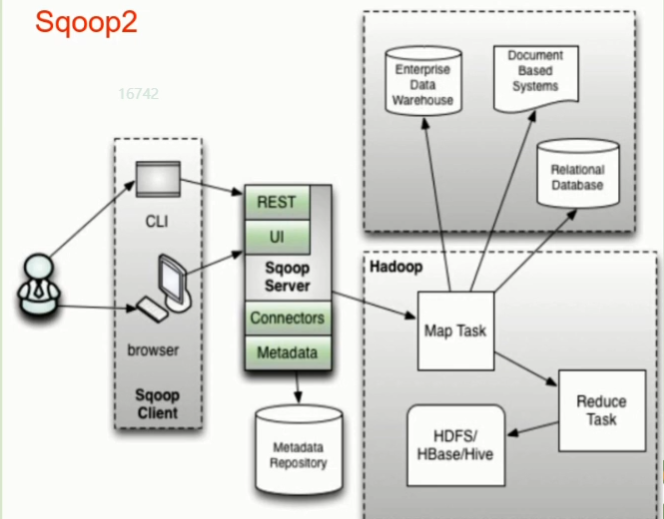
sqoop2:服务端部署,运行,提供client、rest api、web ui等入口,connector集中管理,rdbms账户控制更安全,但是sqoop2仅负责数据的读写操作,架构相对复杂。
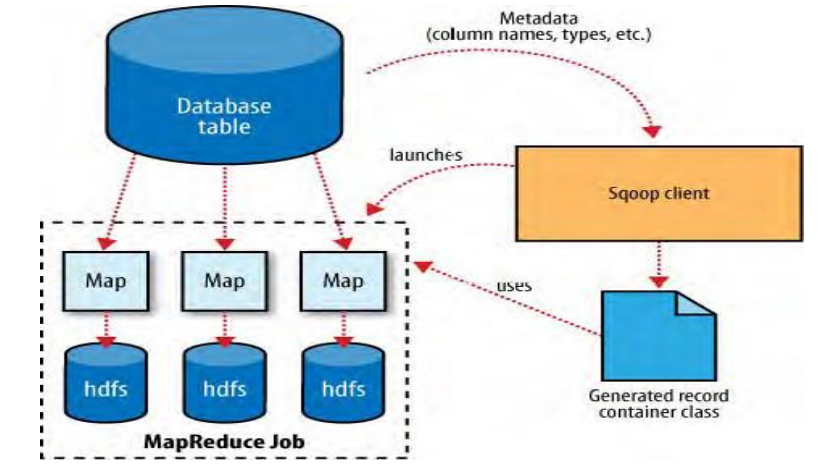
1.4 Sqoop1导入
把数据从数据库导入到hdfs中(大数据生态圈)
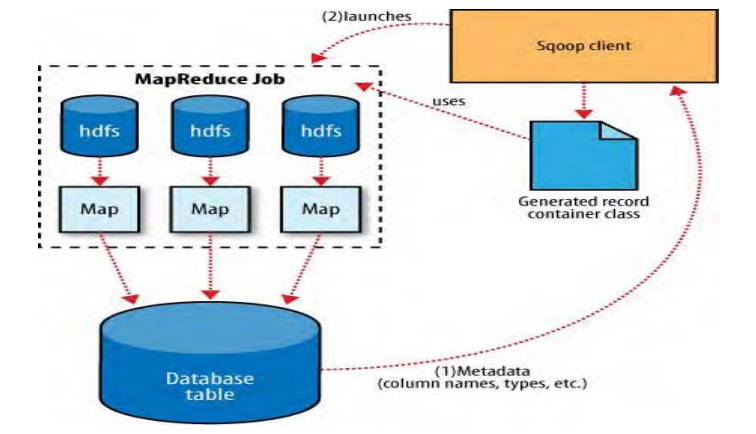
1.5 Sqoop1导出
把数据从大数据生态圈(hdfs)导出到数据库里面
二、Sqoop工具
| 选项 | 含义说明 |
|---|---|
| –connect | 指定JDBC连接字符串 |
| –connection-manager | 指定要使用的连接管理器类 |
| –driver | 指定要使用的JDBC驱动类 |
| –hadoop-mapred-home
| 指定HADOOP_MAPRED_HOME路径 |
| –help | 万能帮助 |
| –password-file | 设置用于存放认证的密码信息文件的路径 |
| -P | 从控制台读取输入的密码 |
| –password | 设置认证密码 |
| –username | 设置认证用户名 |
| –verbose | 打印详细的运行信息 |
| –connection-param-file | 指定存储数据库连接参数的属性文件 |
2.1 导入工具:import
| 选项 | 含义说明 |
|---|---|
| –append | 将数据追加到HDFS上一个已存在的数据集上 |
| –as-avrodatafile | 将数据导入到Avro数据文件 |
| –as-sequencefile | 将数据导入到SequenceFile |
| –as-textfile | 将数据导入到普通文本文件(默认) |
| –boundary-query | 边界查询,用于创建分片(InputSplit) |
| –columns <col,col,col…> | 从表中导出指定的一组列的数据 |
| –delete-target-dir | 如果指定目录存在,则先删除掉 |
| –direct | 使用直接导入模式(优化导入速度) |
| –direct-split-size | 分割输入stream的字节大小(在直接导入模式下) |
| –fetch-size | 从数据库中批量读取记录数 |
| –inline-lob-limit | 设置内联的LOB对象的大小 |
| -m,–num-mappers | 使用n个map任务并行导入数据,默认是3个 |
| -e,–query | 导入的查询语句 |
| –split-by | 指定按照哪个列去分割数据 |
| –table | 导入的源表表名 |
| –target-dir
| 导入HDFS的目标路径 |
| –warehouse-dir
| HDFS存放表的根路径 |
| –where | 指定导出时所使用的查询条件 |
| -z,–compress | 启用压缩 |
| –compression-codec | 指定Hadoop的codec方式(默认gzip) |
| –null-string | 如果指定列为字符串类型,使用指定字符串替换值为null的该类列的值 |
| –null-non-string | 如果指定列为非字符串类型,使用指定字符串替换值为null的该类列的值 |
2.2 导出工具:export
| 选项 | 含义说明 |
|---|---|
| –validate | 启用数据副本验证功能,仅支持单表拷贝,可以指定验证使用的实现类 |
| –validation-threshold | 指定验证门限所使用的类 |
| –direct | 使用直接导出模式(优化速度) |
| –export-dir
| 导出过程中HDFS源路径 |
| –m,–num-mappers | 使用n个map任务并行导出 |
| –table | 导出的目的表名称 |
| –call | 导出数据调用的指定存储过程名 |
| –update-key | 更新参考的列名称,多个列名使用逗号分隔 |
| –update-mode | 指定更新策略,包括:updateonly(默认)、allowinsert |
| –input-null-string | 使用指定字符串,替换字符串类型值为null的列 |
| –input-null-non-string | 使用指定字符串,替换非字符串类型值为null的列 |
| –staging-table | 在数据导出到数据库之前,数据临时存放的表名称 |
| –clear-staging-table | 清除工作区中临时存放的数据 |
| –batch | 使用批量模式导出 |
三、Sqoop1
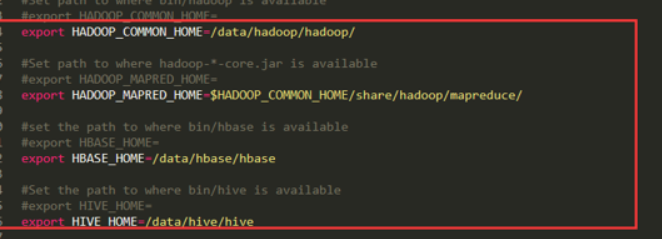
修改配置文件(复制conf/sqoop-env-template.sh为sqoop-env.sh)
验证sqoop:bin/sqoop help
测试sqoop是否能够成功连接数据库
bin/sqoop list-databases --connector jdbc:mysql://node7-1:3306/ --username root --password 123456
3.1 导入数据:import
在Sqoop中,“导入”概念指:从非大数据集群(RDBMS)向大数据集群(HDFS,HIVE,HBASE)中传输数据,叫做:导入,即使用import关键字。
3.1.1 RDBMS到HDFS
导入mysql和hadoop_mapper的jar包
全部导入
bin/sqoop import
--connect jdbc:mysql://192.168.56.1:3306/userscenter?serverTimezone=GMT%2B8
--username root
--password 123456
--table a_users
--target-dir = /sqoop1/a_users
--delete-target-dir
--num-mappers 1
--fields-terminated "t"
查询导入
bin/sqoop import
--connect jdbc:mysql://192.168.56.1:3306/userscenter?serverTimezone=GMT%2B8
--username root
--password 123456
--target-dir = /sqoop1/a_users
--delete-target-dir
--num-mappers 1
--fields-terminated "t"
# query和table是互斥的
# $CONDITIONS:sql语句的执行条件,由sqoop自己控制
--query 'select name,sex from a_users where id <=1 and $CONDITIONS;'
# 拆分的这一列不能重复,一般是主键
如果query后使用的是双引号,则$CONDITIONS前必须加转移符,防止shell识别为自己的变量。
导入指定列
bin/sqoop import
--connect jdbc:mysql://192.168.56.1:3306/userscenter?serverTimezone=GMT%2B8
--username root
--password 123456
--target-dir = /sqoop1/a_users
--delete-target-dir
--num-mappers 1
--fields-terminated "t"
--column id,sex
--table a_users
提示:columns中如果涉及到多列,用逗号分隔,分隔时不要添加空格
使用sqoop关键字筛选查询导入数据
bin/sqoop import
--connect jdbc:mysql://192.168.56.1:3306/userscenter?serverTimezone=GMT%2B8
--username root
--password 123456
--target-dir = /sqoop1/a_users
--delete-target-dir
--num-mappers 1
--fields-terminated "t"
--table a_users
--where "id=1"
3.1.2 RDBMS到HIVE
导入hive-common-3.1.1.jar的jar包
bin/sqoop import
--connect jdbc:mysql://192.168.56.1:3306/userscenter?serverTimezone=GMT%2B8
--username root
--password 123456
--table a_users
--num-mappers 1
--fields-terminated "t"
--hive-overwrite
--hive-table hive_users
该过程分为两步:第一步将数据导入到HDFS;第二步将导入到HDFS的数据迁移到Hive仓库。
3.1.3 RDBMS到HBase
导入hbase-client-2.2.5.jar的jar包
sqoop1.4.6只支持HBase1.0.1之前的版本的自动化创建
bin/sqoop import
--connect jdbc:mysql://192.168.56.1:3306/userscenter?serverTimezone=GMT%2B8
--username root
--password 123456
--table a_users
--columns "id,name,sex"
--columns-family 'cf'
--hbase-create-table
--hbase-row-key "id"
--hbase-table "hbase_users"
--num-mappers 1
--split-by id
提示:sqoop1.4.6只支持HBase1.0.1之前的版本的自动创建HBase表的功能
解决方案:手动创建HBase表
3.2 导出数据:export
在Sqoop中,“导出”概念指:从大数据集群(HDFS,HIVE,HBASE)向非大数据集群(RDBMS)中传输数据,叫做:导出,即使用export关键字。
HIVE/HDFS到RDBMS
bin/sqoop export
--connect jdbc:mysql://192.168.56.1:3306/userscenter?serverTimezone=GMT%2B8
--username root
--password 123456
--verbose
--table a_users
--export-dir /sqoop/a_users
--input-fields-terminated-by "/t"
MySQL中如果表不存在,不会自动创建
3.3 脚本打包
-
创建job
bin/sqoop job --create myjob --import --connect jdbc:mysql://192.168.56.1:3306/userscenter?serverTimezone=GMT%2B8 --username root --password 123456 --verbose --fetch-size 30 --query 'select * from a_users where $CONDITIONS' --split-by id --target-dir = /sqoop1/a_users -
查看所有job
bin/sqoop job --list -
查看单个job
bin/sqoop job --show myjob -
执行job
bin/sqoop job -exec myjob -
删除job
bin/sqoop job --delete myjob
四、Sqoop2
4.1 服务器端
-
解压,重命名
-
修改hadoop中的配置文件(core-site.xml)
<property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> -
导入、替换jar包
将mysql的驱动包放到%Sqoop_home%serverlib中;
将hadoopsharehadoopcommonlib**guava-27.0-jre.jar**拷贝到/data/sqoop/sqoop-2/server/lib和/data/sqoop/sqoop-2/tools/lib中,删除老的,留下新的;
将comm-lang2.5拷贝到hadoop集群中。
-
修改配置文件(conf/sqoop.properties)
org.apache.sqoop.submission.engine.mapreduce.configuration.directory=/data/hadoop/hadoop/etc/hadoop/ -
修改配置文件(bin/sqoop.sh)
配置HADOOP_HOME环境变量
-
初始化,并且验证
bin/sqoop2-tool verify -
启动服务
bin/sqoop2-server start
4.2 工具
把元数据从derby导出
bin/sqoop2-tool repositorydump -o ~/data.json
元数据导入
sqoop2-tool repositoryload -i ~/data.json
4.3 创建link导数据
4.3.1 客户端
启动客户端
bin/sqoop2-shell
启动客户端图形界面服务
set option --name verbose --value true
set server --host node7-4 --port 12000 --webapp sqoop
检查是否连接成功
show version -all
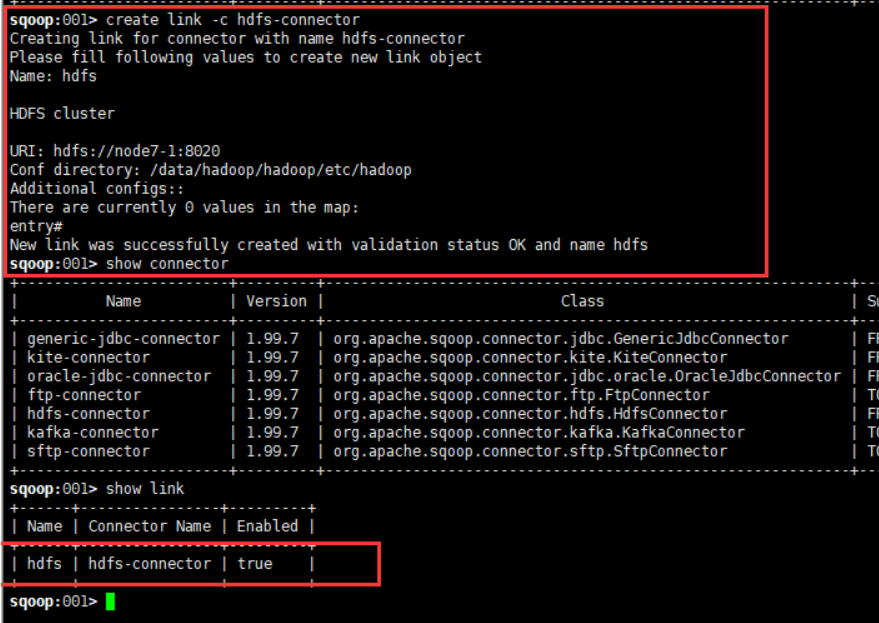
4.3.2 创建hdfs link
create link --connector hdfs-connector
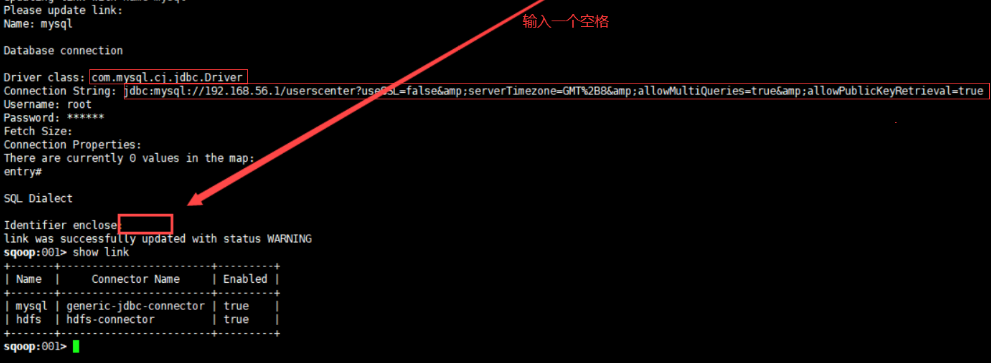
4.3.3 创建mysql link
create link --connector generic-jdbc-connector
4.3.4 创建一个job
-
从mysql link到hdfs link
create job --from mysql --to hdfs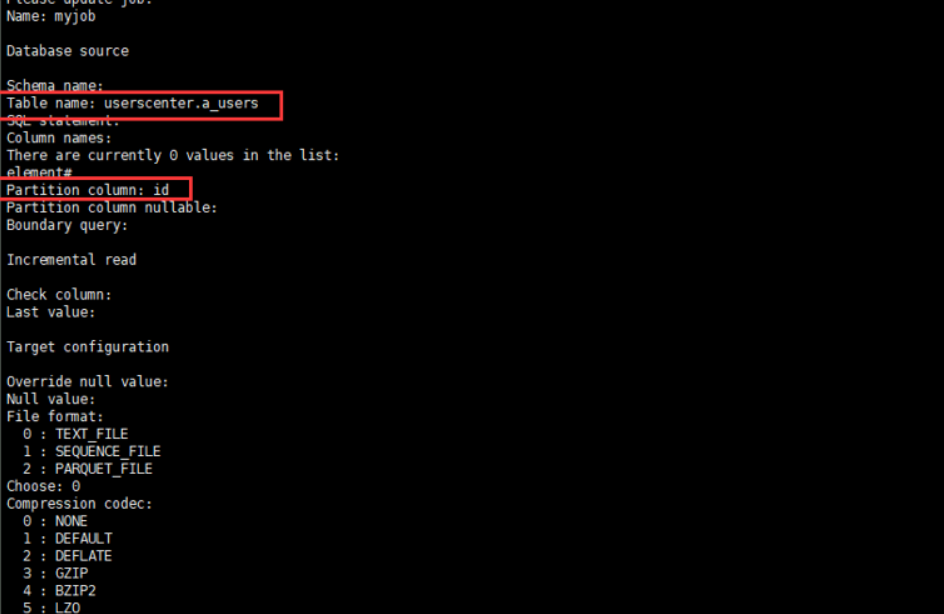
-
从hdfs link到mysql link
create job --from hdfs --to mysql
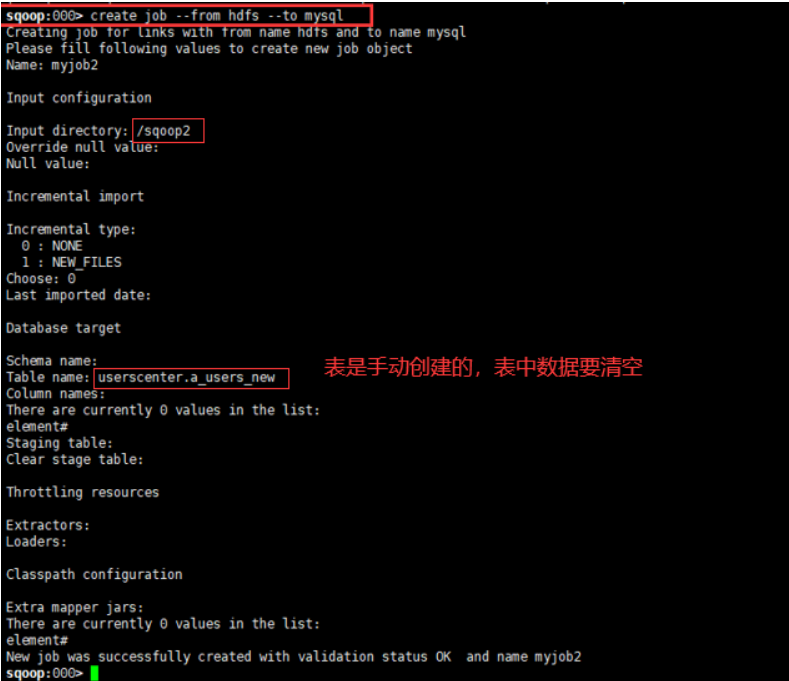
-
标注
表名和表sql语句是相互排斥的。如果表名提供,则表sql语句不应该提供;如果表sql语句提供,则表名不应该提供;
表列名只应在表名提供的情况下提供;
如果有具有类似名称的列,则需要起列别名。
4.3.5 启动job
启动job:start job --name myjob
查看任务的状态:status job --name myjob
删除任务:delete job --name myjob
最后
以上就是无情纸飞机最近收集整理的关于Sqoop知识点总结的全部内容,更多相关Sqoop知识点总结内容请搜索靠谱客的其他文章。








发表评论 取消回复