文章目录
- 3.8 集合论
- nee中的元素在haystack中出现的次数,可以在任何可迭代对象上
- 3.8.1集合字面量
- 3.8.2 集合推导
- 3.8.3 集合操作
- 3.9 dict和set的背后
- 3.9.1 一个关于效率的实验
- 3.9.2 字典中的散列表
- 1.散列值和相等性
- 2.散列表算法
- 获取值:
- 添加新的元素
- 更新现有的键值
- 3.9.3 dict的实现及其导致的结果
- 1.键必须是可散列的
- 所有用户自定义的对象默认都是可散列的,因为它们的散列值由id()值获取,而且都是不相等的。
- 2.字典在内存上的开销巨大
- 3.键查询很快
- 4.键的次序取决于添加顺序
- 5.往字典里添加新键可能会改变已有键的顺序
- 3.9.4 set的实现以及导致的结果
3.8 集合论
集合的本质是许多唯一对象的聚集。一次,集合可以用于去重。
集合中的元素必须是可散列的,set类型本身是不可散列的,但是frozenset可以。因此可以创建一个包含不同frozenset的set.
- 什么叫做可散列的呢?“python里所有不可变类型都是可散列的”。
除了保证唯一性,集合还实现了很多基础的中缀表达式
| 中缀运算符 | 含义 |
|---|---|
| a&b | 返回它们的交集 |
| a | b |
| a-b | 返回它们的差集 |
nee中的元素在haystack中出现的次数,可以在任何可迭代对象上
found = len(set(nee) & set(haystack))
或者
found = len(set(nee).intersection(haystack))
除了快速的查找功能(归功于背后的散列表),内置的set和frozenset提供了额丰富的功能和操作。
3.8.1集合字面量
{1},{1,2,3}和数学形式一模一样
3.8.2 集合推导
例子:
>>> from unicodedata import name
>>> {chr(i) for i in range(32,256) if 'SIGN' in name(chr(i),'')}
{'×', '©', '%', '÷', '°', '¶', '+', '¤', '£', '¬', '®', '¢', '<', '±', 'µ', '=', '$', '§', '#', '¥', '>'}
3.8.3 集合操作
比较普遍,可以参考之前的文章
3.9 dict和set的背后
重视一下的几个问题:
- python里的dict和set的效率有多高?
- 为什么它们是无序的?
- 为什么并不是所有的python对象都可以当做dict的键或者set里面的元素?
- 为什么dict的键和set的顺序是根据它们被添加的次序而定的,以及为什么在映射对象的生命周期中,这个顺序呢并不是一成不变的?
- 为什么不应该在迭代循环dict或是set的同时往里添加元素?
3.9.1 一个关于效率的实验
最快的是集合,最糟糕的是列表。由于列表的背后没有散列表来支持in运算符,每次搜索都需要扫描一次完整的列表,导致所需的时间线性增长。
3.9.2 字典中的散列表
散列表其实是一个稀疏数组(总是有空白元素的数据称为稀疏数组)。一般认为,散列表中的单元通常叫作表元(bucket)。在dict的散列表当中,每个键值对都占用一个表元,每个表元都有两部分,一个是对键的引用,另一个是对值的引用。因为所有表元的大小一致,所有可以通过偏移量来读取某个表元。
因为python会设法保证大概还有三分之一的表元是空的,所以在快要达到这个阀值的时候,原有的散列值会被复制到一个更大的空间里面。
如果要把一个对象放入散列表,那么首先要计算这个元素键的散列值。python中可以用hash()方法来做这件事情。
1.散列值和相等性
内置的hash()方法可以用于所有的内置类型对象。如果是自定义对象调用hash()的话,实际上运行的是自定义的__hash__.如果两个对象在比较的时候是相等的,那么它们的散列值必须相等,否则就不能正常运行了。
2.散列表算法
获取值:
为了获取my_dict[search_key]背后的值,python首先会调用hash(search_key)来计算search_key的散列值,把这个值最低的几位数字当做偏移量,在散列表里查找表元(具体取几位,得看当前散列值的大小)。若找到的表元是空的,则抛出KeyError异常。若不是空的,则表元里会有found_key:found_value。这时候python会检验search_key == found_key是否为真,如果它们相等的话,就会返回found_value.
如果search_key和found_key不匹配的话,就称为散列冲突。发生这种情况是因为,散列表所做的其实是把随机的元素映射到只有几位的数字上,而散列表本身的索引又只依赖这个数字的一部分。为了解决散列冲入,算法会在散列值中另外取几位,然后用特殊方法处理一下,把新得到的数字再当作索引来寻找表元。这次找到若表元若是空的,则同样会抛出KeyError。若非空,或者键匹配,则返回这个值;或者又发现散列冲突,则重复以上步骤。如下图:
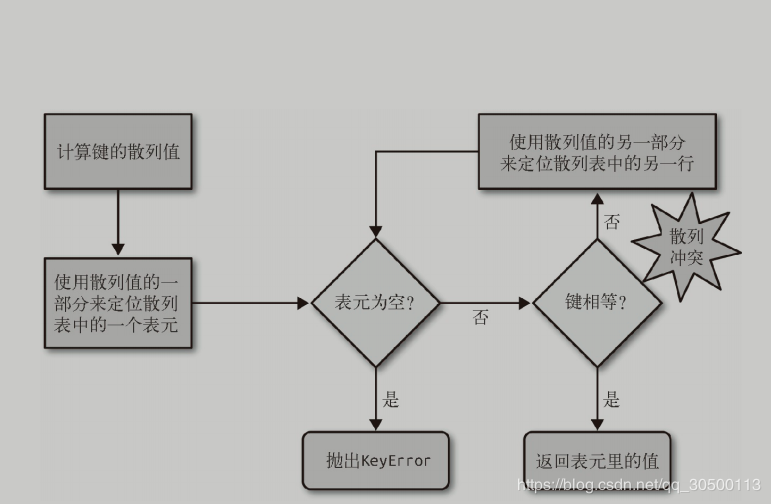
添加新的元素
在发现空表元的时候会放入一个新的元素
更新现有的键值
在找到相应的表元,原表中的值对象会被替换成新值
另外在插入新值时候,python可能会按照散列表的拥挤程度来决定是否要重新分配内存为它扩容。如果增加了散列表的大小,那散列值所占的位数和用作索引的位数都会随之增加,这样做是为了减少发生散列冲突的概率。
3.9.3 dict的实现及其导致的结果
1.键必须是可散列的
一个散列的对象必须包含下面要求:
- (1)支持hash()函数,并且通过__hash__()所得到的散列值是不可变的
- (2)支持通过__eq__()方法来检测相等性
- (3)若a == b 为真,则hash(a)== hash(b) 也为真
所有用户自定义的对象默认都是可散列的,因为它们的散列值由id()值获取,而且都是不相等的。
如果你实现了一个类的__eq__方法,并且希望它是可散列的,那么它一定要有个恰当的__hash__方法.
2.字典在内存上的开销巨大
因为字典使用了散列表,而散列表又必须是稀疏的,这导致了它在空间上的效率底下。
在用户自定义的类型中,__slot__属性可以改变实例属性的存储方式,由dict变成tuple.
在类中定义__slots__属性的目的是告诉解释器:“这个类中所有实力属性都在这儿了”
class Point():
__slots__ = ("x", "y")
def __init__(self, x, y):
self.x = x
self.y = y
def __str__(self):
return "X={}-Y={}".format(self.x,self.y)
3.键查询很快
dict是典型的空间换时间:字典类型有着巨大的内存开销,但是它们提供了无视数据大小的快速访问—只要字典被装在内存里。
4.键的次序取决于添加顺序
当往dict里添加新建而又发生散列冲突的时候,新键可能会被安排到另一个位置。
DIAL_CODES本身按照人口排序的,国家人口前10的国家
>>> DIAL_CODES=[
... (86,'China'),
... (91,'India'),
... (1,'United States'),
... (62,'Indonesia'),
... (55,'Brazil'),
... (92,'Pakistan'),
... (880,'Bangladesh'),
... (234,'Nigeria'),
... (7,'Russia'),
... (81,'Japan'),]
>>> d1= dict(DIAL_CODES)
>>> d1.keys()
dict_keys([86, 91, 1, 62, 55, 92, 880, 234, 7, 81])
>>> d2 = dict(sorted(DIAL_CODES)) # 按照国家的电话区号排序
>>> d2.keys()
dict_keys([1, 7, 55, 62, 81, 86, 91, 92, 234, 880])
>>> d3 = dict(sorted(DIAL_CODES, key=lambda x:x[1])) 按照国家英文名拼写排序
>>> d3.keys()
dict_keys([880, 55, 86, 91, 62, 81, 234, 92, 7, 1])
>>> d1 == d2 and d2 == d3
True
5.往字典里添加新键可能会改变已有键的顺序
无论何时往字典里添加新的键,python解释器都可能做出为字典扩容的决定。扩容导致的结果就是新建一个更大的散列表,并把字典里已经有的元素添加到新表里。这个过程可能呢会发生新的散列冲突,导致新散列表中的键的次序变化。要注意的是,上面提到的这些变化是否会发生以及如何发生,都依赖于字典背后的具体实现。
由此可知,不要对字典同时进行迭代和修改。如果想要扫描并修改一个字典,最好分成两步来进行:首先对字典迭代,以得出需要添加的内容,把这些内容放到一个新的字典里,迭代结束以后,再对原有字典进行更新。
3.9.4 set的实现以及导致的结果
set和frozenset的实现也依赖散列表,但在它们的散列表里存放的只有元素的引用(就像在字典中只有存放键而没有响应的值)
特点总结:
- 结合里的元素必须是散列的
- 结合很消耗内存
- 可以很高效的判断元素是否存在与某个集合
- 元素的次序取决于被添加到集合里的次序
- 往集合里面添加元素,可能会改变集合里已有元素的次序。
最后
以上就是优雅眼睛最近收集整理的关于python进阶(第三章2)字典和集合的全部内容,更多相关python进阶(第三章2)字典和集合内容请搜索靠谱客的其他文章。








发表评论 取消回复