一. 映射的弹性键查询
某个键在映射里不存在,我们也希望在通过这个键读取值的时候能得到一个默认值。有两个途径能帮我们达到这个目的,一个是通过 defaultdict 这个类型而不是普通的 dict,另一个是给自己定义一个 dict 的子类,然后在子类中实现 __missing__ 方法。
1.1 defaultdict:处理找不到的键的一个选择
在实例化一个 defaultdict 的时候,需要给构造方法提供一个可调用对象,这个可调用对象会在 __getitem__ 碰到找不到的键 的时候被调用,让 __getitem__ 返回某种默认值。
演示1 个用来生成默认值的可调用对象存放在名为 default_factory 的实例属性里
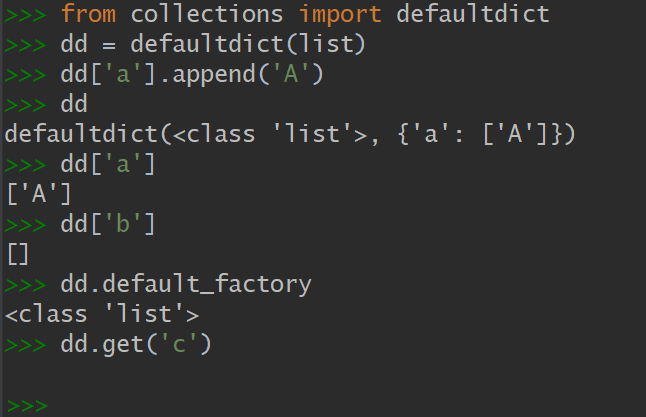
演示2 利用 defaultdict 实例而不是setdefault 方法(还是上一节的示例,改用defaultdict代替setdefault方法)
"""创建一个从单词到其出现情况的映射"""
import sys
import re
import collections
WORD_RE = re.compile(r'w+')
index = collections.defaultdict(list)
with open(sys.argv[1], encoding='utf-8') as f:
for line_no, line in enumerate(f, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start()+1
location = (line_no, column_no)
index[word].append(location)
for word in sorted(index, key=str.upper):
print(word, index[word])如果 index 并没有 word 的记录,那么 default_factory 会被调 用,为查询不到的键创造一个值。这个值在这里是一个空的列表,然后这个空列表被赋值给 index[word],继而被当作返回值返回,因此 .append(location) 操作总能成功。
注意:
-
如果在创建 defaultdict 的时候没有指定 default_factory ,查询不存在的键会触发 KeyError 。
-
defaultdict 里的 default_factory 只会在 __getitem__ 里被调用,在其他的方法里完全不会发挥作用。
-
比 如, dd 是个 defaultdict , k 是个找不到的键, dd[k] 这个表达式会调用 default_factory 创造某个默认值,而 dd.get(k) 则会 返回 None 。
-
所有这一切背后的功臣其实是特殊方法 __missing__。它会在 defaultdict 遇到找不到的键的时候调用 default_factory ,而实际 上这个特性是所有映射类型都可以选择去支持的。
1.2 特殊方法__missing__
如果有一个类继承了 dict,然后这个继承类提供了 __missing__ 方法,那么在 __getitem__ 碰到找不到的键的时候,Python 就会自动调用它, 而不是抛出一个 KeyError 异常。__missing__ 方法只会被 __getitem__ 调用(比如在表达式 d[k] 中)。提供 __missing__ 方法对 get 或者 __contains__(in 运算符会用到这个方法)这些方法的使用没有影响。
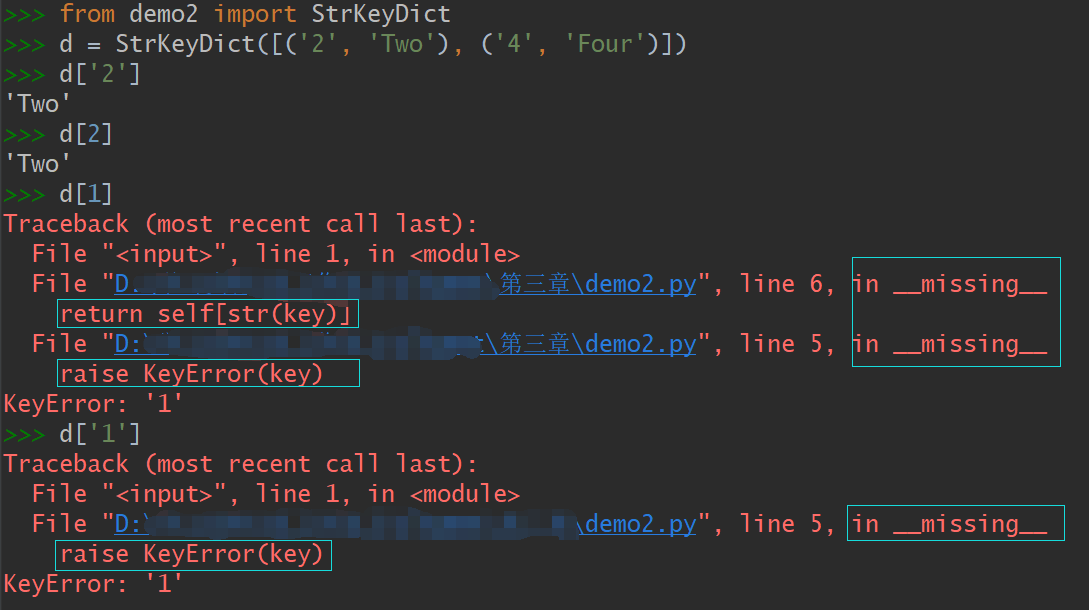
演示3 自定义映射类型,在查询的时候把非字符串的键转换为字符串
class StrKeyDict(dict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def get(self, key, default=None):
try:
return self[key]
except KeyError:
return default
def __contains__(self, key):
return key in self.keys() or str(key) in self.keys()注:
-
为什么 isinstance(key, str) 测试在上面的 __missing__ 中是必需的?如果没有这个测试,只要 str(k) 返回的是一个存在的键,那么 __missing__ 方法是没问题的,不管是字符串键还是非字符串键,它都能正常运行。但是如果 str(k) 不是一个存在的键,代码就会陷入无限递归。这是因为 __missing__ 的最后一行中的 self[str(key)] 会调用 __getitem__ ,而这个 str(key) 又不存在,于是 __missing__ 又会被调用。
-
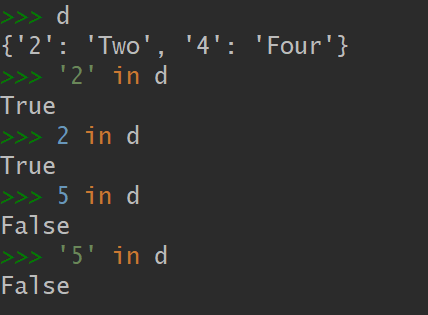
为了保持一致性,__contains__ 方法在这里也是必需的。这是因为 k in d 这个操作会调用它,但是我们从 dict 继承到的 __contains__ 方法不会在找不到键的时候调用 __missing__ 方法。 __contains__ 里还有个细节,就是我们这里没有用更具 Python 风格的方式 —— k in my_dict—— 来检查键是否存在,因为那也会导致 __contains__ 被递归调用。为了避免这一情况,这里采取了更显式的方法,直接在这个 self.keys() 里查询。
-
像 k in my_dict.keys() 这种操作在 Python 3 中是很快 的,而且即便映射类型对象很庞大也没关系。这是因为 dict.keys() 的返回值是一个 “ 视图 ” 。视图就像一个集合,而且跟 字典类似的是,在视图里查找一个元素的速度很快。
1)__getitem__在获取键失败时,会自动调用__missing__方法
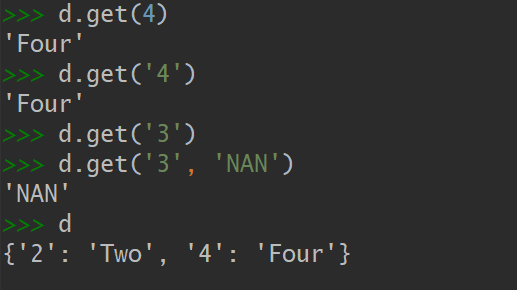
2)get 方法把查找工作用 self[key] 的形式委托给 __getitem__,这样在宣布查找失败之前,还能通过 __missing__ 再给某个键一个机会:
3)为了保持一致性,__contains__ 方法在这里也是必需的:
二. 字典的变种
这一节总结了标准库里 collections 模块中,除了 defaultdict 之外的不同映射类型。
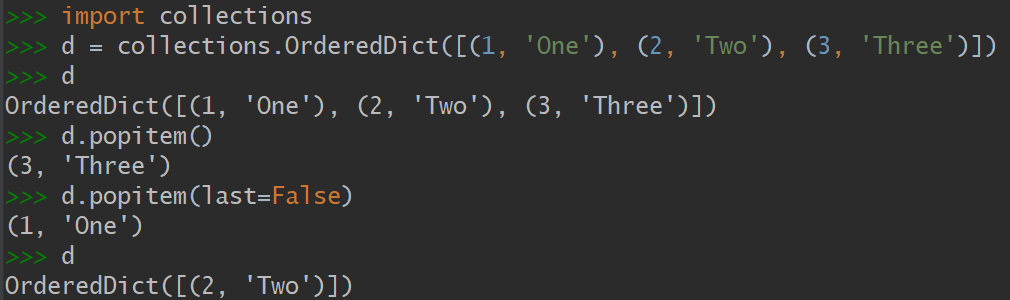
3.1 collections.OrderedDict
这个类型在添加键的时候会保持顺序,因此键的迭代次序总是一致的。OrderedDict 的 popitem 方法默认删除并返回的是字典里的最后一个元素,但是如果像 my_odict.popitem(last=False) 这样调用它,那么它删除并返回第一个被添加进去的元素。
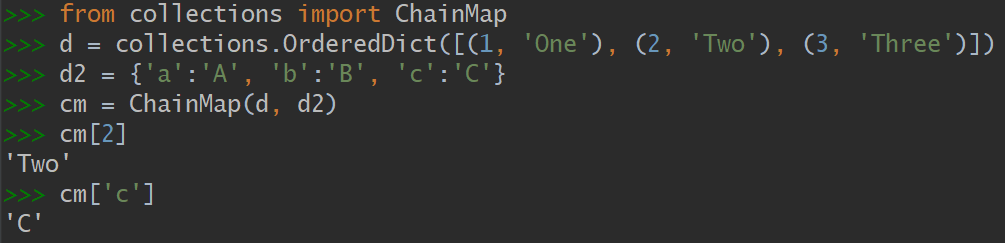
3.2 collections.ChainMap
该类型可以容纳数个不同的映射对象,然后在进行键查找操作的时候,这些对象会被当作一个整体被逐个查找,直到键被找到为止。
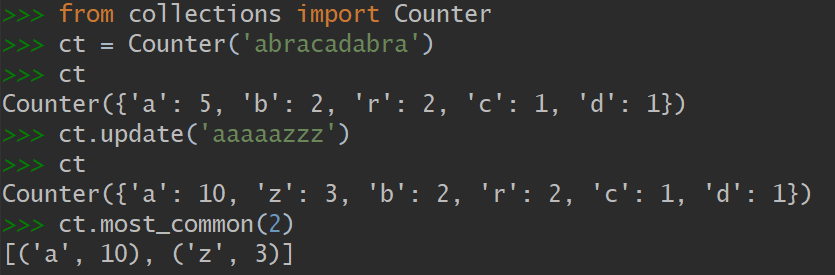
3.3 collections.Counter
这个映射类型会给键准备一个整数计数器。每次更新一个键的时候都会增加这个计数器。所以这个类型可以用来给可散列表对象计数,或者是当成多重集合来用——多重集合就是集合里的元素可以出现不止一次。Counter 实现了 + 和 - 运算符用来合并记录,以及 most_common([n]) 这类很有用的方法。most_common([n]) 会按照次序返回映射里最常见的 n 个键和它们的计数。
演示4 利用Counter来计算单词中各个字母出现的次数
3.4 collections.UserDict
这个类其实就是把标准 dict 用纯 Python 又实现了一遍。跟 OrderedDict、ChainMap 和 Counter 这些开箱即用的类型不 同,UserDict 是让用户继承写子类的。
三. 子类化UserDict
就创造自定义映射类型来说,以 UserDict 为基类,总比以普通的 dict 为基类要来得方便。而更倾向于从 UserDict 而不是从 dict 继承的主要原因是,后者有时会在某些方法的实现上走一些捷径,导致我们不得不在它的子类中重写这些方法,但是UserDict 就不会带来这些问题。
另外一个值得注意的地方是,UserDict 并不是 dict 的子类,但是UserDict 有一个叫作 data 的属性,是 dict 的实例,这个属性实际上是 UserDict 最终存储数据的地方。
演示5 自定义映射类型,无论是添加、更新还是查询操作,StrKeyDict 都会把非字符串的键转换为字符串
from collections import UserDict
class StrKeyDict(UserDict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def __contains__(self, key):
return str(key) in self.data
def __setitem__(self, key, value):
self.data[str(key)] = value与直接继承dict相比,此处继承UserDict有以下明显的优势:
-
__contains__ 则更简洁些。这里可以放心假设所有已经存储的键都是字符串。因此,只要在 self.data 上查询就好了,并不需要去麻烦 self.keys();
-
__setitem__ 会把所有的键都转换成字符串。由于把具体的实现委 托给了 self.data 属性,这个方法写起来也不难。
- 因为 UserDict 继承的是 MutableMapping,所以 StrKeyDict 里剩下的那些映射类型的方法都是从 UserDict、MutableMapping 和 Mapping 这些超类继承而来的。特别是最后的 Mapping 类,它虽然是一个抽象基类(ABC),但它却提供了好几个实用的方法。以下两个方法值得关注:
- MutableMapping.update:这个方法不但可以为我们所直接利用,它还用在 __init__ 里,让构造方法可以利用传入的各种参数(其他映射类型、元素是 (key, value) 对的可迭代对象和键值参数)来新建实例。因为这个方法在背后是用 self[key] = value 来添加新值的,所以它其实是在使用我们的 __setitem__ 方法。
- Mapping.get:在直接继承dict时,我们不得不改写 get 方法,好让它的表现跟 __getitem__ 一致。而继承UserDict后无需重写get方法,因为它继承了 Mapping.get 方法,会将操作委托给__getitem__:
class Mapping(Collection):
...
@abstractmethod
def __getitem__(self, key):
raise KeyError
def get(self, key, default=None):
'D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None.'
try:
return self[key]
except KeyError:
return default
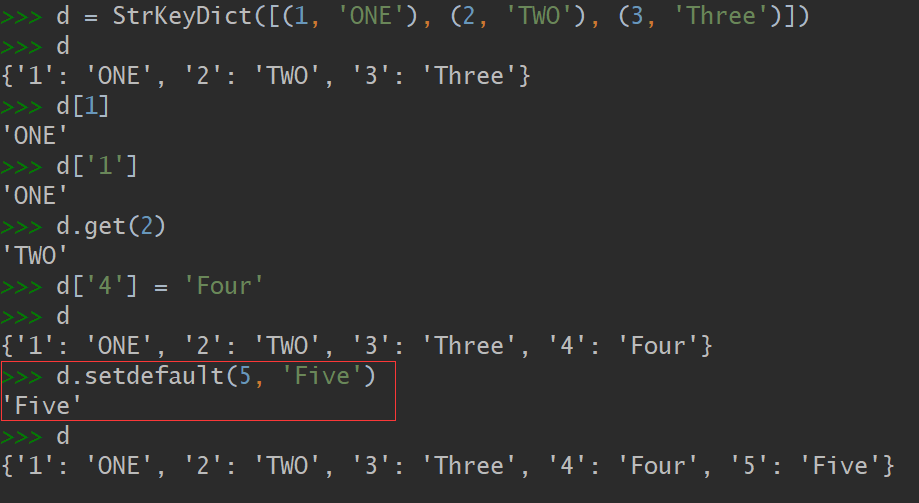
...在控制台导入上述的StrKeyDict,初始化时传入的键均为数值类型,最终存储的却是字符串类型。通过setdeafult设置也是一样的,需要注意的是setdefault设置值后,还会将value返回:
四. 不可变映射类型
标准库里所有的映射类型都是可变的,但有时候你会有这样的需求,比如不能让用户错误地修改某个映射。从 Python 3.3 开始,types 模块中引入了一个封装类名叫 MappingProxyType。如果给这个类一个映射,它会返回一个只读的映射视图。虽然是个只读视图,但是它是动态的。这意味着如果对原映射做出了改动,我们通过这个视图可以观察到,但是无法通过这个视图对原映射做出修改。
演示6 用 MappingProxyType 来获取字典的只读实例 mappingproxy
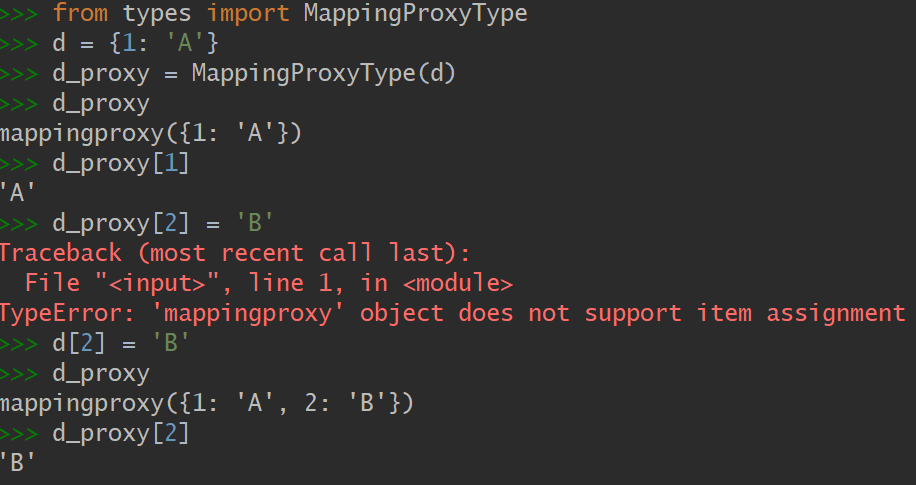
d 中的内容可以通过 d_proxy 看到,但是通过 d_proxy 并不能做任何修改。d_proxy 是动态的,也就是说对 d 所做的任何改动都会反馈到它上面。
最后
以上就是糟糕红牛最近收集整理的关于第三章(提炼)字典和集合(二)的全部内容,更多相关第三章(提炼)字典和集合(二)内容请搜索靠谱客的其他文章。








发表评论 取消回复