Comparator
常用方法
/**
返回一个比较器,该比较器强制此比较器的相反顺序(取反)
*/
default Comparator<T> reversed() {
return Collections.reverseOrder(this);
}
/*
接受从类型T中提取可比较排序键的函数,并返回按该排序键进行比较的
(通过传过来的行为进行排序)thenComparingInt这种类似 只是统一类型避免类型转换
*/
public static <T, U extends Comparable<? super U>> Comparator<T> comparing(
Function<? super T, ? extends U> keyExtractor)
{
Objects.requireNonNull(keyExtractor);
return (Comparator<T> & Serializable)
(c1, c2) -> keyExtractor.apply(c1).compareTo(keyExtractor.apply(c2));
}
/*
接受从类型T中提取排序键的函数,并返回比较器<T>,该比较器使用(参数中)指定的比较器与排序键进行比较。
将keyExtractor得到的数据通过keyComparator.apply()进行比较 返回比较器
*/
public static <T, U> Comparator<T> comparing(
Function<? super T, ? extends U> keyExtractor,
Comparator<? super U> keyComparator)
{
Objects.requireNonNull(keyExtractor);
Objects.requireNonNull(keyComparator);
return (Comparator<T> & Serializable)
(c1, c2) -> keyComparator.compare(keyExtractor.apply(c1),
keyExtractor.apply(c2));
}
/*
返回一个字典顺序比较器和另一个比较器。如果比较器认为两个元素相等,
即compare(a,b)==0(第一个比较器无法确定两个参数比较顺序),则使用other来确定顺序。
(当Comparator.comparingInt比较出现相同数据及 两者比较等于0时
此时才会去调用thenComparing 当前比较器
比较是正或者负 都不会去调用thenComparing)因为正负前比较器就可以确定大小调用后面没意义
注意:该方法不是先通过第一个比较器比完,在使用第二个比较器再次,第二个比较器是辅助第一个进行比较的
*/
default Comparator<T> thenComparing(Comparator<? super T> other) {
Objects.requireNonNull(other);
return (Comparator<T> & Serializable) (c1, c2) -> {
int res = compare(c1, c2);
/*
res 不等于0 说明已经区分大小写 比较顺序以第一个为主 第二个为辅
第一个比较器无法判断时在使用第二个比较器进行比较
*/
return (res != 0) ? res : other.compare(c1, c2);
};
}
示例
public class MyComparatorTest {
public static void main(String[] args) {
List<String> list = Arrays.asList("hello", "world", "nihao", "welcome");
// list.stream().sorted((x,y)->y.length()-x.length()).forEach(System.out::println);
/*
reversed 强行将一个比较器取反
*/
// Collections.sort(list, Comparator.comparingInt(String::length).reversed());
// list.forEach(System.out::println);
System.out.println("===========");
/*
Comparator.comparingInt 是将比较器再拿来比较此时推断不出来 参数类型
comparingInt(ToIntFunction<? super T> keyExtractor) 输入的参数?super T T也有可能是父类型之上的无法推断 所以此时无法推断时就会直接设为基类类型
所以显式添加参数类型只能是T类型(元素类型)之上的类型
*/
// Collections.sort(list, Comparator.comparingInt((String x) -> x.length()).reversed());
// list.forEach(System.out::println);
System.out.println("============");
// list.sort(Comparator.comparingInt(String::length).reversed());
// list.sort(Comparator.comparingInt((String x) -> x.length()).reversed());
System.out.println("============");
/*
先通过length 升序比较,在使用thenComparing()首字母不区分大小写排序CASE_INSENSITIVE_ORDER
当Comparator.comparingInt比较出现相同数据及 两者比较等于0时 此时才会去调用thenComparing 当前比较器
比较是正或者负 都不会去调用thenComparing
*/
// Collections.sort(list, Comparator.comparingInt(String::length).thenComparing(String.CASE_INSENSITIVE_ORDER));
// Collections.sort(list, Comparator.comparingInt(String::length)
// .thenComparing((x, y) -> x.toLowerCase().compareTo(y.toLowerCase())));
// Collections.sort(list, Comparator.comparingInt(String::length).thenComparing(Comparator.comparing(String::toLowerCase)));
System.out.println("=================");
/*
world
nihao
hello
welcome
前三个顺序逆转了 (具体看thenComparing )
*/
// Collections.sort(list, Comparator.comparingInt(String::length)
// .thenComparing(Comparator.comparing(String::toLowerCase, Comparator.reverseOrder())));
System.out.println("=======");
// Collections.sort(list, Comparator.comparingInt(String::length).reversed()
// .thenComparing(Comparator.comparing(String::toLowerCase, Comparator.reverseOrder())));
// list.forEach(System.out::println);
System.out.println("============");
/*
如果比较等于0 则顺序不变 第一个thenComparing 进行字母排序 compare 比较!=0
第二个thenComparing 也就未执行
*/
Collections.sort(list, Comparator.comparingInt(String::length).reversed().
thenComparing(Comparator.comparing(String::toLowerCase, Comparator.reverseOrder())).
thenComparing(Comparator.reverseOrder()));
list.forEach(System.out::println);
}
}
自定义收集器
示例1
public class MySetCollector<T> implements Collector<T, Set<T>, Set<T>> {
@Override
public Supplier<Set<T>> supplier() {
System.out.println("suppliper invoked");
//返回的结果对象就是 A 中间结果容器
return HashSet::new;
}
@Override
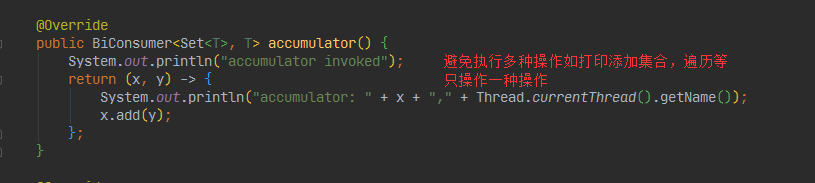
public BiConsumer<Set<T>, T> accumulator() {
System.out.println("accumulator invoked");
return Set::add;
//supplier 返回的中间容器可能跟此不对应
// return HashSet::add;
}
@Override
public BinaryOperator<Set<T>> combiner() {
System.out.println("combiner invoked");
return (x, y) -> {
x.addAll(y);
return x;
};
}
@Override
public Function<Set<T>, Set<T>> finisher() {
System.out.println("finisher invoked");
// return (x -> x);
//等同上
return Function.identity();
}
@Override
public Set<Characteristics> characteristics() {
System.out.println("characteristics invoked");
/*
unmodifiableSet: 方法返回只读不可变集合
EnumSet 用于枚举类型的专用集合实现
of 创建最初包含指定元素的枚举集。
IDENTITY_FINISH 表示 一致性identity和结合性finisher是一个函数类型
(也就是中间容器类型的和最终返回结果类型一致)
UNORDERED 指示集合操作不承诺保留输入元素的相遇顺序。
(如果结果容器没有内在顺序(如集合),则可能是这样。
*/
return Collections.unmodifiableSet(EnumSet.of(IDENTITY_FINISH, UNORDERED));
}
public static void main(String[] args) {
List<String> list = Arrays.asList("hello", "world", "welcome", "hello");
//如果中间结果类型A和返回结果类型R一致finisher()方法将不会被调用
Set<String> set = list.stream().collect(new MySetCollector<>());
System.out.println(set);
}
}
打印结果
suppliper invoked
accumulator invoked
combiner invoked
characteristics invoked
characteristics invoked
[world, hello, welcome]
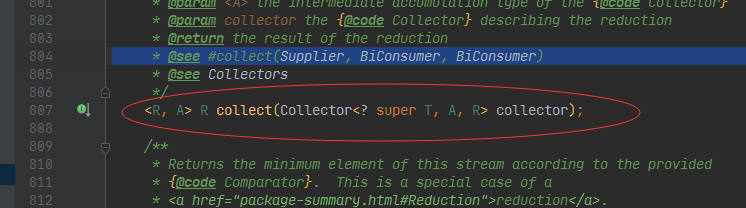
collect实现类
如下代码如果设置IDENTITY_FINISH这个类型 此时中间容器类型和返回结果类型必须一致
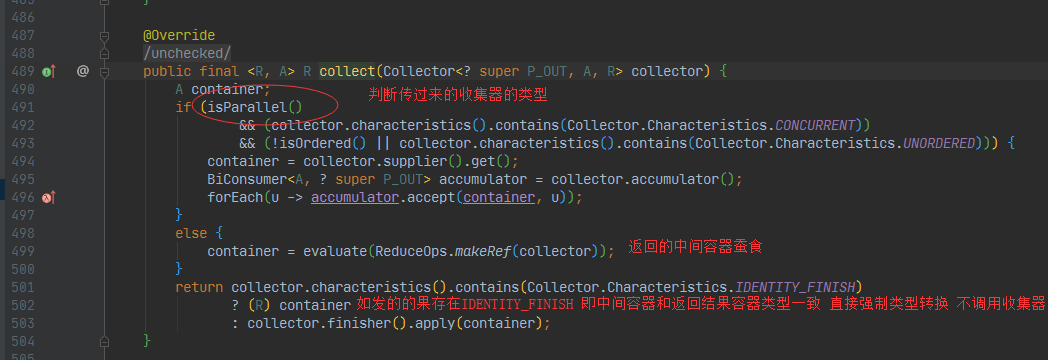
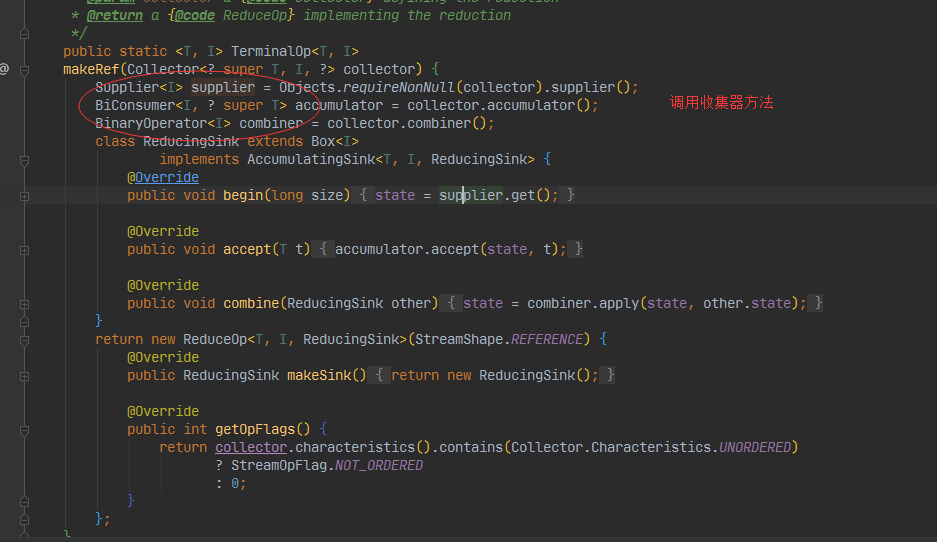
调用收集器的方法
示例2(重要)
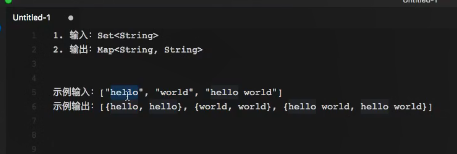
public class MyMapCollector<T> implements Collector<T, Set<T>, Map<T, T>> {
@Override
public Supplier<Set<T>> supplier() {
System.out.println("suppliper invoked");
// return HashSet::new;
return () -> {
/*
多线程调用打印对应次--------- 说明每个线程都生成一个中间结果容器
单线程调用 打印一次------ 说明值生成一个中间容器
*/
System.out.println("-----------------");
return new HashSet<T>();
};
}
@Override
public BiConsumer<Set<T>, T> accumulator() {
System.out.println("accumulator invoked");
return (x, y) -> {
//如果多线程存在多个操作 可能会抛异常
// System.out.println("accumulator: " + x + "," + Thread.currentThread().getName());
/*
如果是串行流或者并行流设置IDENTITY_FINISH特性时 直接把中间结果容器当做最终结果返回
不会调用combiner()和finisher() 方法
*/
x.add(y);
};
}
@Override
public BinaryOperator<Set<T>> combiner() {
System.out.println("combiner invoked");//打印只是调用方法
return (x, y) -> {
/*
如果并行流去操作收集器此时未设置Characteristics.CONCURRENT特性时
此时会被调用(需收集多线程结果)返回行为(返回行为才算被调用)
如果设置了改特性 依然不会被调用 (此时多线程操作一个中间容器,结果都在一个中间容器中)
注意返回行为才算调用成功
*/
System.out.println("x:" + x);
x.addAll(y);
return x;
};
}
@Override
public Function<Set<T>, Map<T, T>> finisher() {
System.out.println("finisher invoked");
return (x) -> {
Map<T, T> collect = x.stream().collect(Collectors.toMap(Function.identity(), Function.identity()));
// Map<T, T> map = new HashMap<>();
// x.stream().forEach(y -> map.put(y, y));
return collect;
};
}
@Override
public Set<Characteristics> characteristics() {
System.out.println("characteristics invoked");
/*
UNORDERED 无序
CONCURRENT 并行
*/
return Collections.unmodifiableSet(EnumSet.of(Characteristics.UNORDERED, Characteristics.CONCURRENT));
}
public static void main(String[] args) {
List<String> list = Arrays.asList("hello", "world", "hello", "a", "bv", "cc");
for (int i = 0; i <= 100; ++i) {
Set<String> set = new HashSet();
set.addAll(list);
System.out.println("set:" + set);
System.out.println("============");
/*
当使用并行流操作收集器时收集器中方法characteristics
未标识Characteristics.CONCURRENT类型(并行多个线程操作一个容器)
此时每个线程对应一个中间容器此时 finisher就需要将他们进行合并
*/
Map<String, String> map = set.parallelStream().collect(new MyMapCollector<>());
/**
* parallel() 并行
* sequential() 串行
*/
// Map<String, String> map2 = set.stream().sequential().collect(new MyMapCollector<>()); //同上
System.out.println(map);
}
}
}
当执行改收集器可能会抛出如下异常

ConcurrentModificationException:通常不允许一个线程在另一个线程迭代集合时修改该集合。一般来说,在这种情况下迭代的结果是不确定的。
当我们加了改类型此时多个线程操作一个accumulator() 中间容器,可能存在一个线程在添加,另外一个线程在迭代查询
如何避免
当自定义收集器时
最后
以上就是纯真书本最近收集整理的关于lambda表达式:Comparator,自定义收集器CollectorComparator自定义收集器的全部内容,更多相关lambda表达式:Comparator内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复