在上一篇文档 kubernetes Master节点组件(三)- Controller Manager中我们说到,当我们通过kubectl添加一个deployment定义之后,replicaset控制器会为我们添加实际的pod副本。
但是这个pod定义仍然只是存在在etcd里面的配置而已,它如何能够在合适的宿主机(node)上面运行呢?
这个时候就需要用到另外一个组件 Scheduler(调度器) 对其进行调度,通过一系列的判定来为这个pod打上适合它的 nodeName。
以下面这个pod的定义为例
apiVersion: v1
kind: Pod
metadata:
name: qos-demo
namespace: qos-example
spec:
containers:
- name: qos-demo-ctr
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "100Mi"
cpu: "200m"
我们可以看到,这里定义了一个pod它对其需求的最少资源为100MiB的内存(Mi为1024)和0.2个CPU,而对资源的需求上限为200Mi内存和0.7个CPU。
那么在调度器对其进行调度的时候就会按照其request的资源来寻找相关的node进行调度,但是在宿主机的kubelet真正启动容器时,为其指定的cgroup限制却是通过其limit的资源来设置的。
这样做的原因是因为大多数应用在运行过程中其实际的资源使用量都远小于其最大的需求量,所以在调度的时候可以按照其最小需求量进行调度。
但是如果当宿主机上有大量应用的资源使用量暴增导致剩余资源达到一定阈值的时候怎么办呢?这个时候kubelet就会按照优先级删除部分低优先级的应用,直到剩余资源降到阈值以下。
而这里的优先级是怎么判定的呢?
就是通过其对资源的需求来判定:
- 最低优先级的是BestEffort,这种pod在kubelet进行删除操作时,是最先会被考虑的对象
- 次一等优先级的是Burstable,这种级别的pod至少设置了一个request参数。当没有BestEffort的pod同时当前紧张的资源已经不能满足其request的需求的时候,就会对其进行删除
- 最高优先级的是Guaranteed,这种级别的pod其requests和limits的参数完全一样,这种pod对资源的需求很重视,所以kubelet会为其分配固定的资源来运行。意思也就是说这个pod会在固定的CPU资源上运行,而不是根据系统动态分配CPU资源,这样也减少了CPU切换时导致的上下文切换所浪费的时间,所带来的好处也是很明显的,可以很大程度提升程序运行的效率。
Scheduler结构
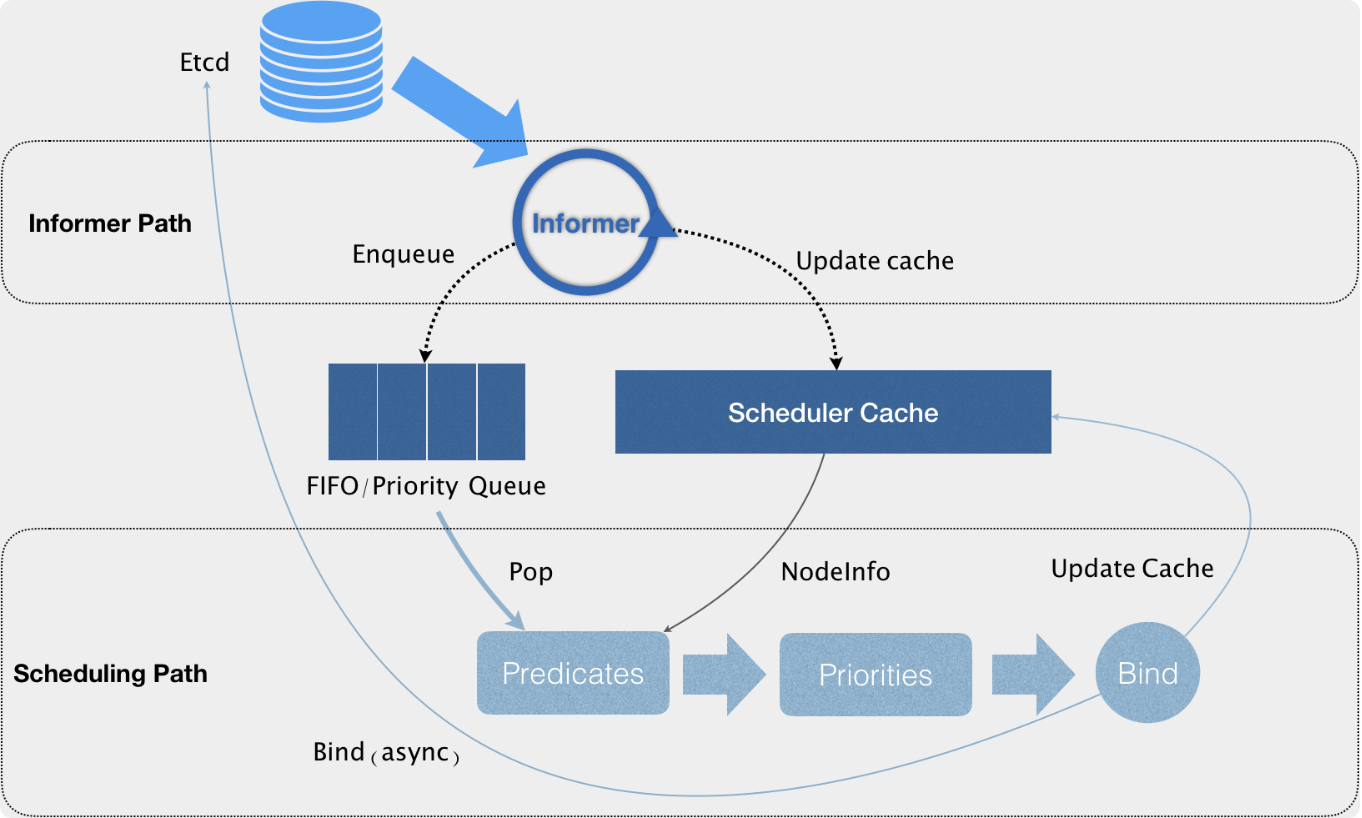
通过上图我们可以看到,调度器实际上主要是由两个控制循环来完成对pod,service等的调度的
Informer Path
第一个循环Informer Path中,调度器通过一系列的informer来对pod,node,service等信息进行list and watch。当对应资源(比如pod)有改变时,informer会收到来自api server的变化通知,然后informer会将资源的变动信息更新到调度器缓存中用于后续调度算法的判定依据(这里使用cache的好处就是避免了对api server的大量重复的请求操作,特别是后面的调度算法判定阶段,从而提升调度效率)。
如果有新增的资源,比如有个新的pod,那么informer会将其添加到调度队列中。这里的调度队列是一个优先级的队列,它在保证FIFO的基本功能的同时,还能满足调度器的一些特殊操作,比如基于优先级的抢占操作。
Scheduling Path
第二个循环Scheduling Path中,调度器会从调度队列里不断取出需要调度的资源,然后
- 通过Predicates算法对Scheduler Cache中的Nodes进行过滤,拿到合适的Node列表。
- 根据Priorities算法对第一步的Node列表进行打分,选出得分最高的Node
- 修改资源的nodeName字段为选出的Node,并更新Scheduler Cache中pod和node的信息,然后启动一个异步的线程去请求api server去修改持久化的pod信息。这样做的好处是提高了调度器的调度效率。如果异步线程失败了也无所谓,cache中的信息会随着后续的更新而恢复正常,调度失败的资源会在后续进行重新调度。当然这种基于乐观绑定的设计,就需要kubelet在实际运行资源的时候再次通过基本的调度算法进行确认看当前pod是否能够在当前node运行。
同时为了进一步提升调度的效率,调度器对Predicates和Priorities过程都是启动多个线程来并发地对多个资源进行判定,同时在Priorities的阶段以MapReduce的方式来进行打分。整个过程只有在资源出队和更新cache的时候会加锁,从而保证了
调度器的执行效率。
Predicates 调度策略
Predicates其实就相当于一个的filter chain,对当前所有的node list进行过滤,最后得到符合调度条件的node list。
GeneralPredicates
这一组 filter是最基础的filter,主要判断对应的node是否满足pod的运行条件。
- PodFitsResources,用于判断当前node的资源是否满足pod的request的资源条件
- PodFitsHost,用于判断当前node的名字是否满足pod所指定的nodeName
- PodFitsHostPorts,用于判断当前node可用的端口是否满足pod所要求的端口占用
- PodMatchNodeSelector,用于判断当前node是否匹配pod所定义的nodeSelector或者nodeAffinity
与Volume相关的规则
- NoDiskConflict,用于判断多个pod所声明的volume是否有冲突
- MaxPDVolumeCountPredicate,用于判断某种volume是否已经超过所指定的数目
- VolumeBindingPredicate,用于检查pod所定义的volume的nodeAffinity是否与node的标签所匹配
Node相关规则
- PodToleratesNodeTaints,只有当pod所指定的tolerate字段与node的taint字段匹配的时候,pod才会调度到该node
- NodeMemoryPressurePredicate,检查当前node的内存是否充足,只有充足的时候才会调度到该node
Pod相关的过滤规则
- PodAffinityPredicate,用于检查pod和该node上的pod是否和affinity以及anti-affinity规则匹配
而针对于这么多规则,调度器在面对一个待调度的pod的时候会同时启动很多个线程来并发地计算所有node是否满足所有的条件,最后将满足条件的node list 返回。当然对于条件计算是有一定顺序的,通常跟node相关的规则会先计算,这样就可以避免一些没有必要的规则校验,比如在一个内存严重不足的node上面计算pod的affinity是没有意义的。
Priorities打分规则
当调度器通过Predicates拿到可调度的node list之后,我们则需要通过进一步地对比得到最适合调度的node。这里就需要用到priorities打分规则。
其中最常用的一个打分规则就是LeastRequestedPriority。其算法公式可以简单地概括为:
score = (cpu((capacity-sum(requested))10/capacity) + memory((capacity-sum(requested))10/capacity))/2
从公式就可以看到,当前pod所要求的资源在该node上所占用的空闲资源越少,那么该node的得分也就越高。
但是这种算法有个问题就是可能会导致一个node上cpu资源被大量分配,但是内存资源却大量剩余。
这个时候就需要另外一种规则进行配合,那就是BalancedResourceAllocation。它通过计算多种资源的距离来保证node资源的均衡分配。其算法公式可概括为:
score = 10 - variance(cpuFraction,memoryFraction,volumeFraction)*10
其中每一种fraction为 pod请求资源/node空闲资源,而variance则计算几种fraction之间的距离,得分最高的表示该pod的调度能更好的均衡node上的资源。
此外还有 NodeAffinityPriority,TaintTolerationPriority,InterPodAffinityPriority以及ImageLocalityPriority等基于优先级的计算规则,一个node满足的要求越多,其得分就会越高。
调度器的抢占机制
上面我们说到调度器的调度任务缓存队列为一个优先级队列。这就意味着高优先级的pod是可以被提前调度的。
那么当一个pod调度失败之后会怎么样呢?
对于普通的pod,在调度失败之后,其调度任务会被pending,知道该pod被更新或者集群的状态发生变化。
但是对于高优先的pod,调度器就会通过抢占的机制来尽量保证其成功完成调度。
这里我们定义一个优先级,同时指定一个pod配置该优先级
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for high priority service pods only."
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
我们可以看到该pod的优先级为1million,而kubernetes允许的用户自定义优先级为1billion (再大的优先级需要分配给系统pod使用)。
调度器的队列实现中其实有两个队列:
- Active Queue,这个队列主要是存放待调度的pod
- Unschedulable Queue,这个队列主要是存放调度失败的pod
当Unschedulable Queue里面的pod被更新后,调度器会将其重新放入Active Queue中,给它重新调度的机会。
而对于高优先级的pod,调度器会
- 首先检查调度失败的原因,看看能否通过抢占来完成调度(有些调度失败无法通过抢占来恢复,比如pod指定要分配到某个固定的node上,但是该node不存在)。
- 一旦发现该pod能够通过抢占来完成调度,调度器就会调取一份当前所有node的信息来模拟抢占的过程,也就是对所有node模拟删除低优先级的pod直到该高优先级pod可以完成调度。然后找个一个影响最小的node来作为其实施抢占的节点。
- 当模拟完成后,调度器就开始实施实际的抢占过程。首先清除待删除pod上的nominatedNodeName字段,然后为该高优先级pod设置nominatedNodeName字段为该node,这个时候就会触发该pod的重新调度,最后启动一个线程同步删除所有待删除的pod。
就算是这样,调度器仍然不能保证该pod能够马上调度成功,因为可能还存在其他具有优先级的pod等待调度到这个节点。这个时候就需要将两个pod进行共同校验看是否能同时调度到该节点。
特殊资源与Device Plugin插件
我们在定义pod的时候需要声明对资源使用的要求,但是目前能够直接使用只有CPU和Memory。
如果我们想引入对GPU这种资源的声明怎么办?这里我们就需要使用到device plugin插件。
由于在kubernetes 的api path中并没有专门的GPU资源,所以需要用到kubernetes的Extended Resource来为GPU指定特殊的资源类型。比如我们声明一个需要GPU的pod
apiVersion: v1
kind: Pod
metadata:
name: cuda-vector-add
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "k8s.gcr.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
调度器不会管nvidia.com/gpu的具体含义,它只会去node的status/capacity路径下查找是否有相关定义以及其可用值是否满足要求。
而对于node,在调度pod之前我们需要通过path操作将相关的nvidia.com/gpu定义添加上去:
$ kubectl proxy
$ curl --header "Content-Type: application/json-patch+json"
--request PATCH
--data '[{"op": "add", "path": "/status/capacity/nvidia.com/gpu", "value": "1"}]'
http://localhost:8001/api/v1/nodes/<your-node-name>/status
但是node的GPU信息怎么进行更新呢,这个时候就需要用到device plugin插件了。
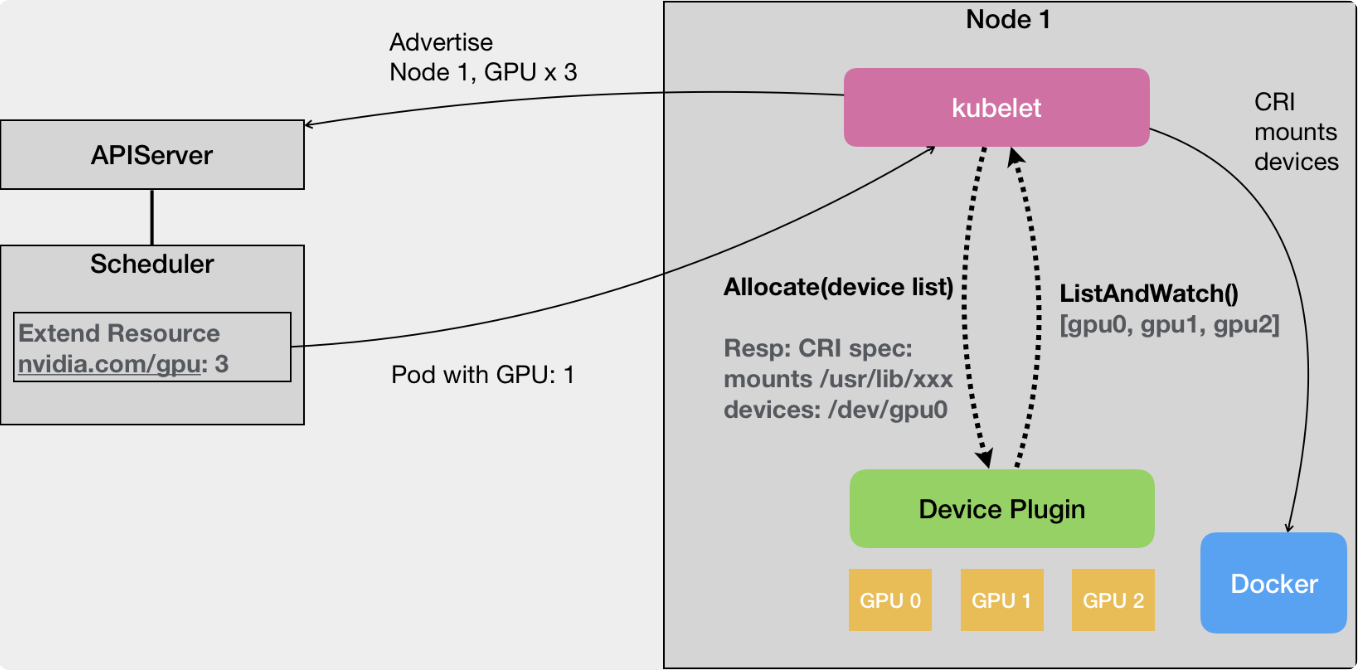
从上图可以看到,device plugin会通过list and watch接口及时地将当前GPU的资源列表上报给kubelet,而kubelet则会通过自己与API server的心跳包,将当前GPU的资源数上报到API server进行更新。
当有一个需要GPU的pod被调度后,kubelet会根据自己缓存的GPU信息分配具体的GPU资源,然后下发allocate请求告诉device plugin,而device plugin则会根据被分配的GPU资源拿到对应的GPU设备目录和驱动目录返回给kubelet,这样kubelet在添加容器的时候,就会把GPU相关目录挂载到容器上完成调度了。
虽然kubernetes社区目前有很多这种插件,但是这种机制目前来看比较简单粗暴,对于更细粒度的资源分配是无法完成的。
调度器的发展
目前的默认调度器是kubernetes内部最后一个没有对外暴露可扩展接口的组件。所以目前也在重构之中。而目前的重构方向则是希望通过插件的方式让用户能够添加自定义的一些优先级队列以及调度算法。
最后
以上就是舒适导师最近收集整理的关于Kubernetes Master节点组件(四)- SchedulerScheduler结构Predicates 调度策略Priorities打分规则调度器的抢占机制特殊资源与Device Plugin插件调度器的发展的全部内容,更多相关Kubernetes内容请搜索靠谱客的其他文章。



![[云原生·k8s] 终于读懂了Kubernetes1. Kubernetes概念2. Kubernetes 组件3. Kubernetes功能](https://www.shuijiaxian.com/files_image/reation/bcimg5.png)




发表评论 取消回复