1.@Component源码解析逻辑原理
文章目录
- 1.@Component源码解析逻辑原理
- 1.解析@Component流程
- 2.总结
- 2.@Component和@Service和@controller和@Repository区别
springboot如何解析@component注解的?
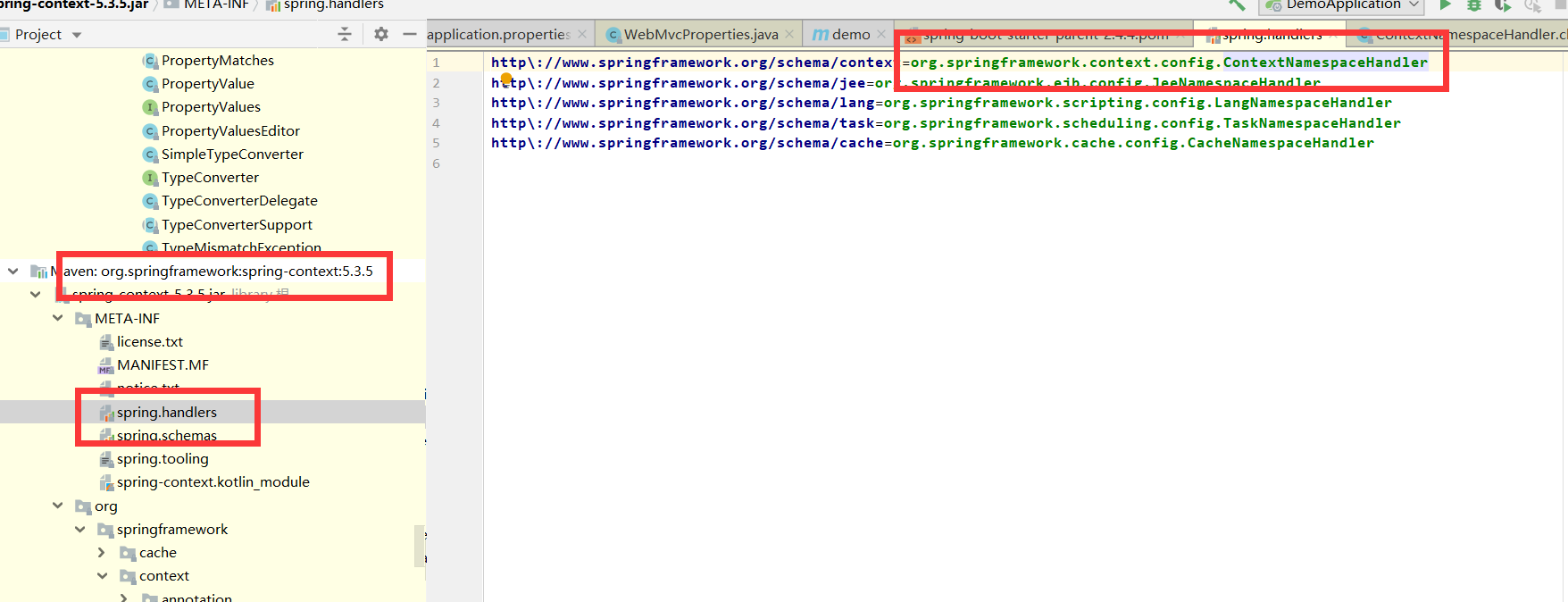
spring.springframework2.0开始要求xml文件编程机制要与handler建立映射关系…
我们找到spring-context.jar包下META-INF/spring.handlers 映射关系都在这个里面…
1.解析@Component流程
1.首先有一个componentScan扫描,猜测应该是递归寻找项目下的包找到含有@Component注解的类。
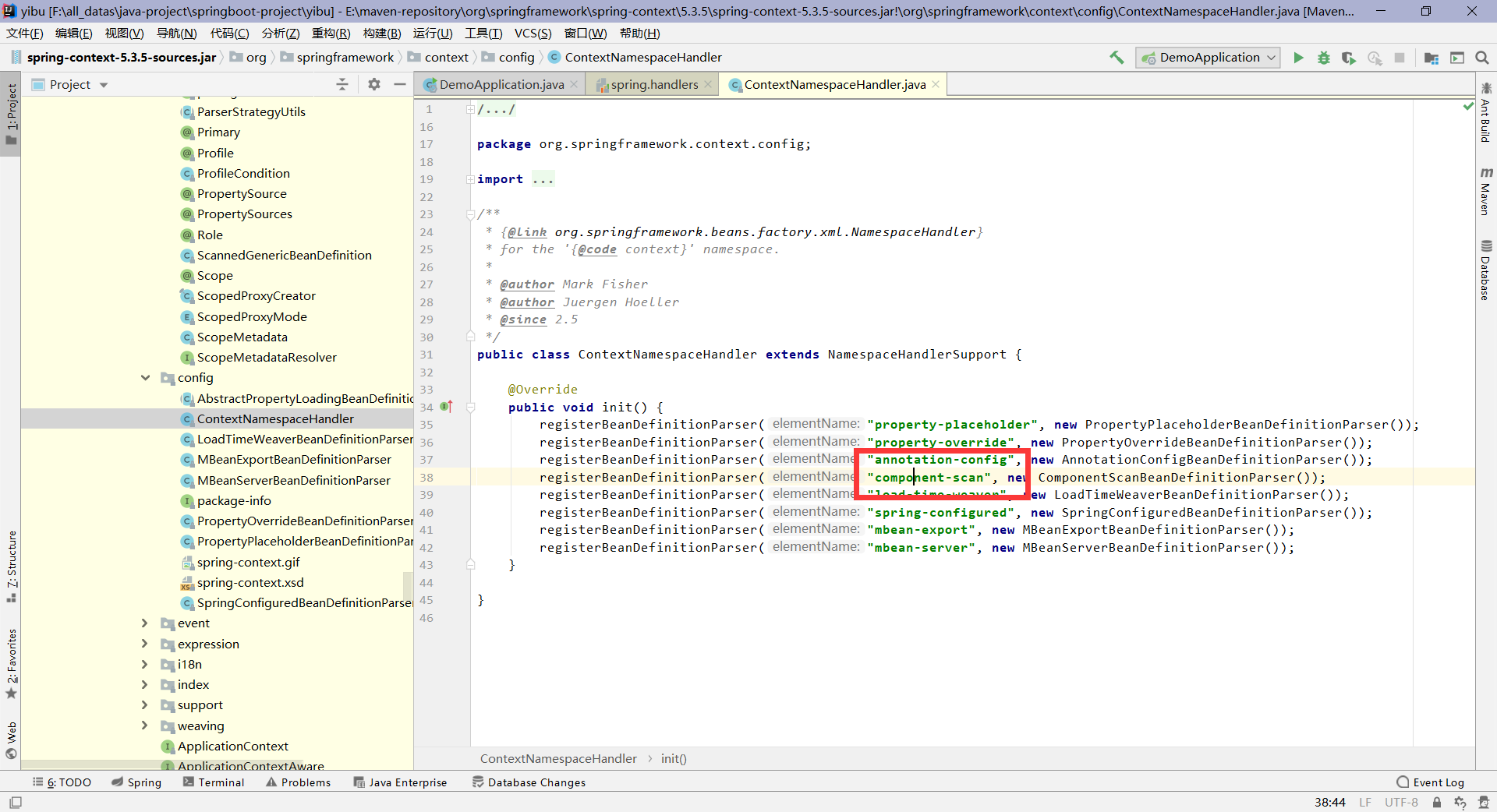
2.进入这个ComponentScanBeanDefinitionParser类,可以看到注释就是扫描component的元素.
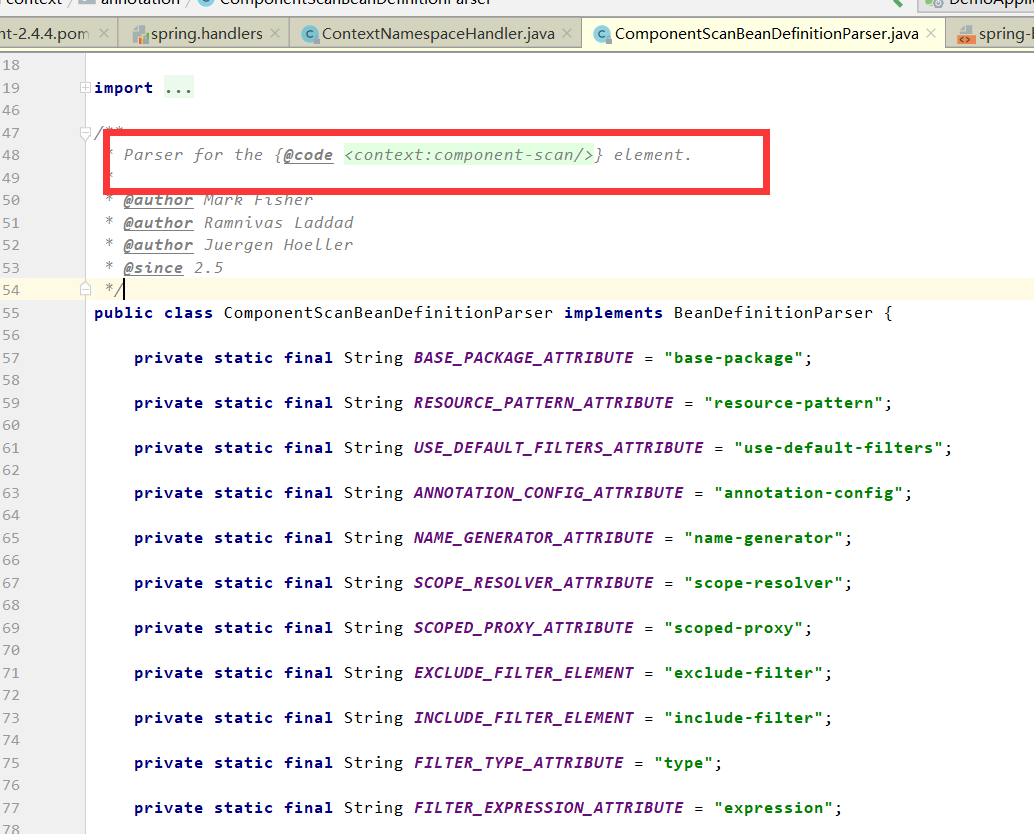
3.这个类中的重点方法
从名字ClassPathBeanDefinitionScanner知道这是一个BeanDedinition类的扫描器.
protected ClassPathBeanDefinitionScanner configureScanner(ParserContext parserContext, Element element){
//省略
}
那么如何扫描的呢?进入这个ClassPathBeanDefinitionScanner 类
找到如下图doScan方法.
/**
* Perform a scan within the specified base packages,
* returning the registered bean definitions.
* <p>This method does <i>not</i> register an annotation config processor
* but rather leaves this up to the caller.
* @param basePackages the packages to check for annotated classes
* @return set of beans registered if any for tooling registration purposes (never {@code null})
*/
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
它会根据base packages也就是项目启动类同级目录开始,然后返回注册了的bean difinitions.
先断言base package不为空,然后用一个Set集合装定义了的beanDefinitions.(这里用set集合是为了不重复获取beanDefinitions吧)
那么这个candidates集合是怎么获得的呢?通过findCandidateComponents(basePackage).那么findCandidateComponents就是核心方法,帮助我们寻找候选的Components.
findCandidateComponents方法如下:
/**
* Scan the class path for candidate components.
* @param basePackage the package to check for annotated classes
* @return a corresponding Set of autodetected bean definitions
*/
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
return scanCandidateComponents(basePackage);
}
}
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
//扫描包下的路径,并将路径 替换成 classpath:/方式.
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
//循环每一个路径
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
//判定是不是@Component注解的类.
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not readable: " + resource);
}
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
findCandidateComponents大体思路如下:
- 用ResourcePatternResolver加载basepackage包下路径并转化为资源搜索路径packageSearchPath,例如:com.wl.spring.boot转化为classpath*:com/wl/spring/boot/**/*.class.
2Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath); 加载搜素路径下的资源。.
3.isCandidateComponent 判断是否是备选组件
4.candidates.add(sbd); 添加到返回结果的list
isCandidateComponent如下:
/**
* Determine whether the given class does not match any exclude filter
* and does match at least one include filter.
* @param metadataReader the ASM ClassReader for the class
* @return whether the class qualifies as a candidate component
*/
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return false;
}
}
for (TypeFilter tf : this.includeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return isConditionMatch(metadataReader);
}
}
return false;
}
includeFilters定义了过滤规则,它的默认值又由registerDefaultFilters定义:
protected void registerDefaultFilters() {
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.annotation.ManagedBean", cl)), false));
logger.trace("JSR-250 'javax.annotation.ManagedBean' found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-250 1.1 API (as included in Java EE 6) not available - simply skip.
}
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.inject.Named", cl)), false));
logger.trace("JSR-330 'javax.inject.Named' annotation found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}
这个过滤规则里面看到了new AnnotationTypeFilter(Component.class) 要是@Component注解的类才可以.
2.总结
首先ResourcePatternResolver加载当前包路径,使用set集合存储包下候选的路径,防止重复扫描,并且转换为classpath:/ 形式…
加载路径下的资源
然后判定类是不是有component注解.判定是不是有Component注解的由excludeFilter过滤器提供规则,这个规则的定义又是registerDefaultFilters()提供的.
2.@Component和@Service和@controller和@Repository区别
这几个注解本质一样,@service @controller @repository都是component的派生注解
解析@service这些注解的时候是读取了他的元注解component,就 把service注解当作component处理。
然后至于为什么要派生那么都的注解出来?
仅仅是为了分层,便于容器的管理.@Component是万能组件注解,@Service是服务层的,@Reposiroty是接口层,@controller是控制层.
最后
以上就是迅速小猫咪最近收集整理的关于springboot@Component源码解析逻辑的全部内容,更多相关springboot@Component源码解析逻辑内容请搜索靠谱客的其他文章。








发表评论 取消回复