[TOC]
1 场景
在实际过程中,遇到这样的场景:
日志数据打到HDFS中,运维人员将HDFS的数据做ETL之后加载到hive中,之后需要使用Spark来对日志做分析处理,Spark的部署方式是Spark on Yarn的方式。
从场景来看,需要在我们的Spark程序中通过HiveContext来加载hive中的数据。
如果希望自己做测试,环境的配置可以参考我之前的文章,主要有下面的需要配置:
1.Hadoop环境
Hadoop环境的配置可以参考之前写的文章;
2.Spark环境
Spark环境只需要在提交job的节点上进行配置即可,因为使用的是Spark on Yarn的方式;
3.Hive环境
需要配置好Hive环境,因为在提交Spark任务时,需要连同hive-site.xml文件一起提交,因为只有这样才能够识别已有的hive环境的元数据信息;
所以其实中Spark on Yarn的部署模式中,需要的只是hive的配置文件,以让HiveContext能够读取存储在mysql中的元数据信息以及存储在HDFS上的hive表数据;
hive环境的配置可以参考之前的文章;
其实之前已经有写过Spark Standalone with Hive的文章,可以参考:《Spark SQL笔记整理(三):加载保存功能与Spark SQL函数》。
2 编写程序与打包
作为一个测试案例,这里的测试代码比较简单,如下:
package cn.xpleaf.spark.scala.sql.p2
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author xpleaf
*/
object _01HiveContextOps {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
val conf = new SparkConf()
// .setMaster("local[2]")
.setAppName(s"${_01HiveContextOps.getClass.getSimpleName}")
val sc = new SparkContext(conf)
val hiveContext = new HiveContext(sc)
hiveContext.sql("show databases").show()
hiveContext.sql("use mydb1")
// 创建teacher_info表
val sql1 = "create table teacher_info(n" + "name string,n" + "height double)n" + "row format delimitedn" + "fields terminated by ','"
hiveContext.sql(sql1)
// 创建teacher_basic表
val sql2 = "create table teacher_basic(n" + "name string,n" + "age int,n" + "married boolean,n" + "children int)n" + "row format delimitedn" + "fields terminated by ','"
hiveContext.sql(sql2)
// 向表中加载数据
hiveContext.sql("load data inpath 'hdfs://ns1/data/hive/teacher_info.txt' into table teacher_info")
hiveContext.sql("load data inpath 'hdfs://ns1/data/hive/teacher_basic.txt' into table teacher_basic")
// 第二步操作:计算两张表的关联数据
val sql3 = "selectn" + "b.name,n" + "b.age,n" + "if(b.married,'已婚','未婚') as married,n" + "b.children,n" + "i.heightn" + "from teacher_info in" + "inner join teacher_basic b on i.name=b.name"
val joinDF:DataFrame = hiveContext.sql(sql3)
val joinRDD = joinDF.rdd
joinRDD.collect().foreach(println)
joinDF.write.saveAsTable("teacher")
sc.stop()
}
}
可以看到其实只是简单的在hive中建表、加载数据、关联数据与保存数据到hive表中。
编写完成之后打包就可以了,注意不需要将依赖一起打包。之后就可以把jar包上传到我们的环境中了。
3 部署
编写submit脚本,如下:
[hadoop@hadoop01 jars]$ cat spark-submit-yarn.sh
/home/hadoop/app/spark/bin/spark-submit
--class $2
--master yarn
--deploy-mode cluster
--executor-memory 1G
--num-executors 1
--files $SPARK_HOME/conf/hive-site.xml
--jars $SPARK_HOME/lib/mysql-connector-java-5.1.39.jar,$SPARK_HOME/lib/datanucleus-api-jdo-3.2.6.jar,$SPARK_HOME/lib/datanucleus-core-3.2.10.jar,$SPARK_HOME/lib/datanucleus-rdbms-3.2.9.jar
$1
注意其中非常关键的--files和--jars,说明如下:
--files $HIVE_HOME/conf/hive-site.xml //将Hive的配置文件添加到Driver和Executor的classpath中
--jars $HIVE_HOME/lib/mysql-connector-java-5.1.39.jar,…. //将Hive依赖的jar包添加到Driver和Executor的classpath中
之后就可以执行脚本,将任务提交到Yarn上:
[hadoop@hadoop01 jars]$ ./spark-submit-yarn.sh spark-process-1.0-SNAPSHOT.jar cn.xpleaf.spark.scala.sql.p2._01HiveContextOps
4 查看结果
需要说明的是,如果需要对执行过程进行监控,就需要进行配置historyServer(mr的jobHistoryServer和spark的historyServer),可以参考我之前写的文章。
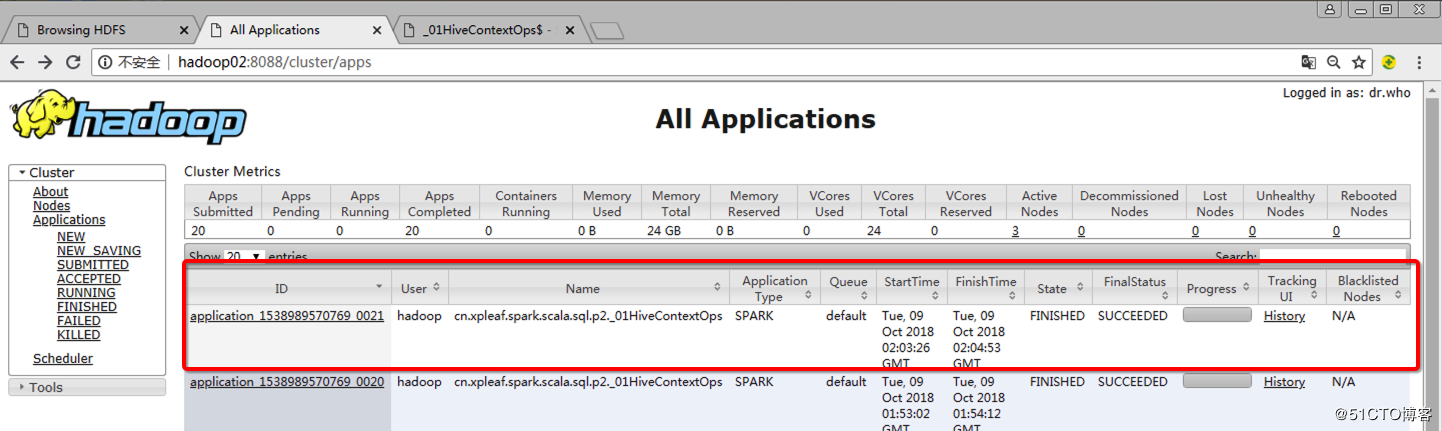
4.1 Yarn UI
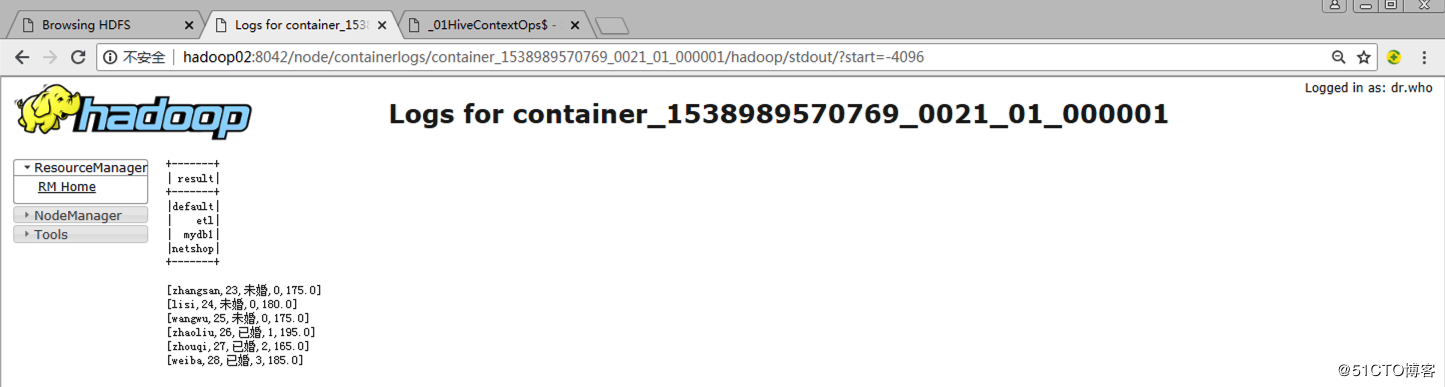
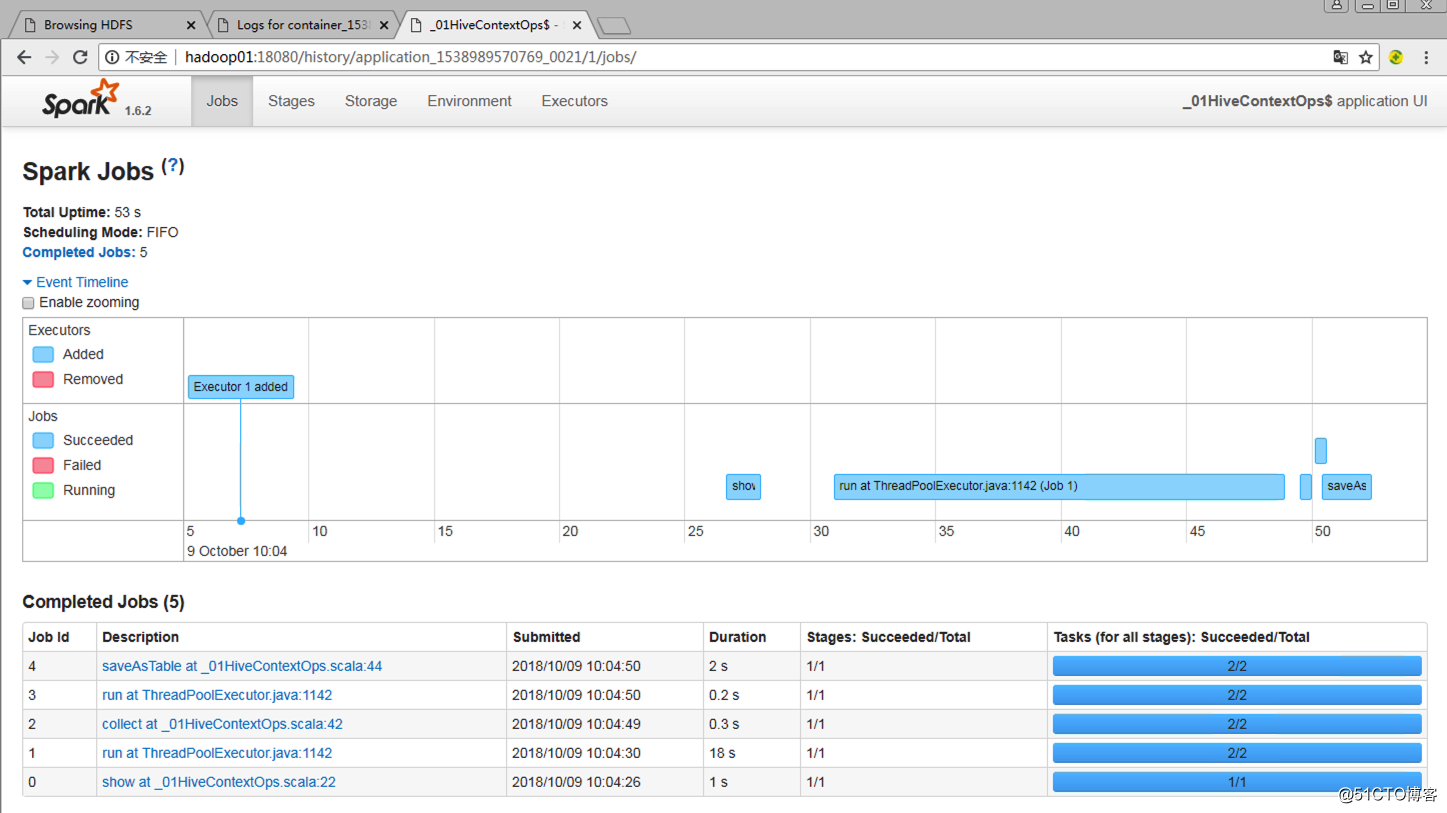
4.2 Spark UI

4.3 Hive
可以启动hive,然后查看我们的spark程序加载的数据:
hive (mydb1)>
>
>
> show tables;
OK
t1
t2
t3_arr
t4_map
t5_struct
t6_emp
t7_external
t8_partition
t8_partition_1
t8_partition_copy
t9
t9_bucket
teacher
teacher_basic
teacher_info
test
tid
Time taken: 0.057 seconds, Fetched: 17 row(s)
hive (mydb1)> select *
> from teacher_info;
OK
zhangsan 175.0
lisi 180.0
wangwu 175.0
zhaoliu 195.0
zhouqi 165.0
weiba 185.0
Time taken: 1.717 seconds, Fetched: 6 row(s)
hive (mydb1)> select *
> from teacher_basic;
OK
zhangsan 23 false 0
lisi 24 false 0
wangwu 25 false 0
zhaoliu 26 true 1
zhouqi 27 true 2
weiba 28 true 3
Time taken: 0.115 seconds, Fetched: 6 row(s)
hive (mydb1)> select *
> from teacher;
OK
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
zhangsan 23 未婚 0 175.0
lisi 24 未婚 0 180.0
wangwu 25 未婚 0 175.0
zhaoliu 26 已婚 1 195.0
zhouqi 27 已婚 2 165.0
weiba 28 已婚 3 185.0
Time taken: 0.134 seconds, Fetched: 6 row(s)
5 问题与解决
1.User class threw exception: java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
注意我们的Spark部署模式是Yarn,yarn上面是没有相关spark和hive的相关依赖的,所以在提交任务时,必须要指定要上传的jar包依赖:
--jars $SPARK_HOME/lib/mysql-connector-java-5.1.39.jar,$SPARK_HOME/lib/datanucleus-api-jdo-3.2.6.jar,$SPARK_HOME/lib/datanucleus-core-3.2.10.jar,$SPARK_HOME/lib/datanucleus-rdbms-3.2.9.jar
其实在提交任务时,注意观察控制台的输出:
18/10/09 10:57:44 INFO yarn.Client: Uploading resource file:/home/hadoop/app/spark/lib/spark-assembly-1.6.2-hadoop2.6.0.jar -> hdfs://ns1/user/hadoop/.sparkStaging/application_1538989570769_0023/spark-assembly-1.6.2-hadoop2.6.0.jar
18/10/09 10:57:47 INFO yarn.Client: Uploading resource file:/home/hadoop/jars/spark-process-1.0-SNAPSHOT.jar -> hdfs://ns1/user/hadoop/.sparkStaging/application_1538989570769_0023/spark-process-1.0-SNAPSHOT.jar
18/10/09 10:57:47 INFO yarn.Client: Uploading resource file:/home/hadoop/app/spark/lib/mysql-connector-java-5.1.39.jar -> hdfs://ns1/user/hadoop/.sparkStaging/application_1538989570769_0023/mysql-connector-java-5.1.39.jar
18/10/09 10:57:47 INFO yarn.Client: Uploading resource file:/home/hadoop/app/spark/lib/datanucleus-api-jdo-3.2.6.jar -> hdfs://ns1/user/hadoop/.sparkStaging/application_1538989570769_0023/datanucleus-api-jdo-3.2.6.jar
18/10/09 10:57:47 INFO yarn.Client: Uploading resource file:/home/hadoop/app/spark/lib/datanucleus-core-3.2.10.jar -> hdfs://ns1/user/hadoop/.sparkStaging/application_1538989570769_0023/datanucleus-core-3.2.10.jar
18/10/09 10:57:47 INFO yarn.Client: Uploading resource file:/home/hadoop/app/spark/lib/datanucleus-rdbms-3.2.9.jar -> hdfs://ns1/user/hadoop/.sparkStaging/application_1538989570769_0023/datanucleus-rdbms-3.2.9.jar
18/10/09 10:57:47 INFO yarn.Client: Uploading resource file:/home/hadoop/app/spark/conf/hive-site.xml -> hdfs://ns1/user/hadoop/.sparkStaging/application_1538989570769_0023/hive-site.xml
18/10/09 10:57:47 INFO yarn.Client: Uploading resource file:/tmp/spark-6f582e5c-3eef-4646-b8c7-0719877434d8/__spark_conf__103916311924336720.zip -> hdfs://ns1/user/hadoop/.sparkStaging/application_1538989570769_0023/__spark_conf__103916311924336720.zip
也可以看到,其会将相关spark相关的jar包上传到yarn的环境也就是hdfs上,之后再执行相关的任务。
2.User class threw exception: org.apache.spark.sql.execution.QueryExecutionException: FAILED: SemanticException [Error 10072]: Database does not exist: mydb1
mydb1不存在,说明没有读取到我们已有的hive环境的元数据信息,那是因为在提交任务时没有指定把hive-site.xml配置文件一并提交,如下:
--files $SPARK_HOME/conf/hive-site.xml
最后
以上就是欢呼白开水最近收集整理的关于hivecontext mysql_Spark on Yarn with Hive实战案例与常见问题解决的全部内容,更多相关hivecontext内容请搜索靠谱客的其他文章。








发表评论 取消回复